Large language models (LLMs) have demonstrated remarkable in-context learning capabilities across various domains, including translation, function learning, and reinforcement learning. However, the underlying mechanisms of these abilities, particularly in reinforcement learning (RL), remain poorly understood. Researchers are attempting to unravel how LLMs learn to generate actions that maximize future discounted rewards through trial and error, given only a scalar reward signal. The central challenge lies in understanding how LLMs implement temporal difference (TD) learning, a fundamental concept in RL that involves updating value beliefs based on the difference between expected and actual rewards.
Previous research has explored in-context learning from a mechanistic perspective, demonstrating that transformers can discover existing algorithms without explicit guidance. Studies have shown that transformers can implement various regression and reinforcement learning methods in-context. Sparse autoencoders have been successfully used to decompose language model activations into interpretable features, identifying both concrete and abstract concepts. Several studies have investigated the integration of reinforcement learning and language models to improve performance in various tasks. This research contributes to the field by focusing on understanding the mechanisms through which large language models implement reinforcement learning, building upon the existing literature on in-context learning and model interpretability.
Researchers from the Institute for Human-Centered AI, Helmholtz Computational Health Center and Max Planck Institute for Biological Cybernetics have employed sparse autoencoders (SAEs) to analyse the representations supporting in-context learning in RL settings. This approach has proven successful in building a mechanistic understanding of neural networks and their representations. Previous studies have applied SAEs to various aspects of neural network analysis, demonstrating their effectiveness in uncovering underlying mechanisms. By utilizing SAEs to study in-context RL in Llama 3 70B, researchers aim to investigate and manipulate the model’s learning processes systematically. This method allows for identifying representations similar to TD errors and Q-values across multiple tasks, providing insights into how LLMs implement RL algorithms through next-token prediction.
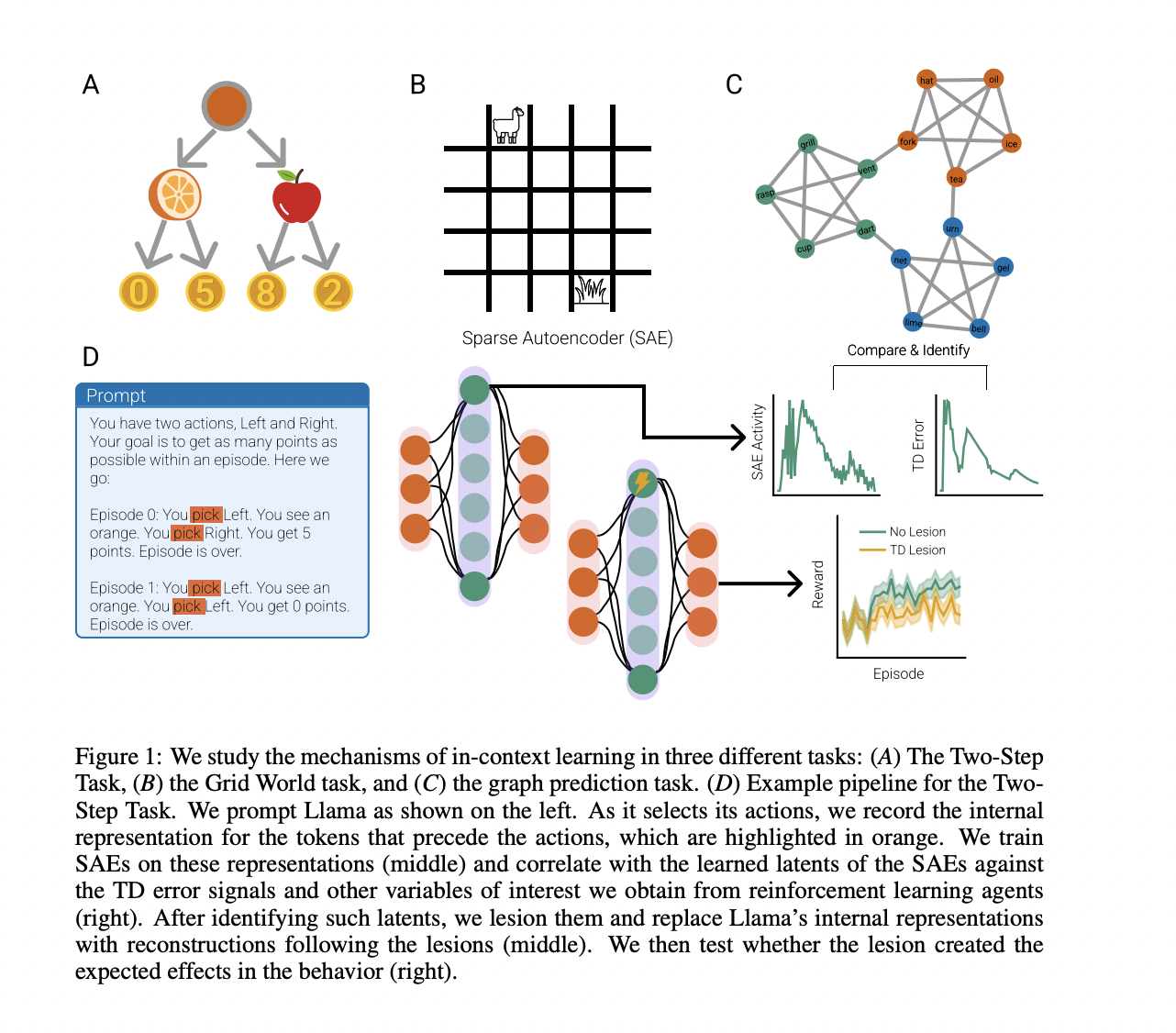
The researchers developed a methodology to analyze in-context reinforcement learning in Llama 3 70B using SAEs. They designed a simple Markov Decision Process inspired by the Two-Step Task, where Llama had to make sequential choices to maximize rewards. The model’s performance was evaluated across 100 independent experiments, each consisting of 30 episodes. SAEs were trained on residual stream outputs from Llama’s transformer blocks, using variations of the Two-Step Task to create a diverse training set. This approach allowed the researchers to uncover representations similar to TD errors and Q-values, providing insights into how Llama implements RL algorithms through next-token prediction.
The researchers extended their analysis to a more complex 5×5 grid navigation task, where Llama predicted the actions of Q-learning agents. They found that Llama improved its action predictions over time, especially when provided with correct reward information. SAEs trained on Llama’s residual stream representations revealed latents highly correlated with Q-values and TD errors of the generating agent. Deactivating or clamping these TD latents significantly degraded Llama’s action prediction ability and reduced correlations with Q-values and TD errors. These findings further support the hypothesis that Llama’s internal representations encode reinforcement learning-like computations, even in more complex environments with larger state and action spaces.
Researchers investigate Llama’s ability to learn graph structures without rewards, using a concept called Successor Representation (SR). They prompted Llama with observations from a random walk on a latent community graph. Results showed that Llama quickly learned to predict the next state with high accuracy and developed representations similar to the SR, capturing the graph’s global geometry. Sparse autoencoder analysis revealed stronger correlations with SR and associated TD errors than with model-based alternatives. Deactivating key TD latents impaired Llama’s prediction accuracy and disrupted its learned graph representations, demonstrating the causal role of TD-like computations in Llama’s ability to learn structural knowledge.

This study provides evidence that large language models (LLMs) implement temporal difference (TD) learning to solve reinforcement learning problems in-context. By using sparse autoencoders, researchers identified and manipulated features crucial for in-context learning, demonstrating their impact on LLM behaviour and representations. This approach opens avenues for studying various in-context learning abilities and establishes a connection between LLM learning mechanisms and those observed in biological agents, both of which implement TD computations in similar scenarios.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 50k+ ML SubReddit
Interested in promoting your company, product, service, or event to over 1 Million AI developers and researchers? Let’s collaborate!
Asjad is an intern consultant at Marktechpost. He is persuing B.Tech in mechanical engineering at the Indian Institute of Technology, Kharagpur. Asjad is a Machine learning and deep learning enthusiast who is always researching the applications of machine learning in healthcare.
