Large language models (LLMs) like GPT-4, Gemini, and Llama 3 have revolutionized natural language processing through extensive pre-training and supervised fine-tuning (SFT). However, these models come with high computational costs for training and inference. Structured pruning has emerged as a promising method to improve LLM efficiency by selectively removing less critical components. Despite its potential, depth-wise structured pruning faces challenges like accuracy degradation, especially in tasks that require multi-step reasoning. Pruning can disrupt information flow between layers, leading to poor model quality even after SFT. Also, fine-tuning can increase catastrophic forgetting, further degrading model quality. So, developing effective strategies to mitigate these challenges during pruning is crucial.
Existing attempts to address LLM efficiency challenges include pruning for model compression, distillation, and methods to mitigate catastrophic forgetting. Pruning aims to reduce model complexity but can lead to inefficient acceleration or degraded model quality. Knowledge Distillation (KD) allows smaller models to learn from larger ones, with recent applications in pre-training and fine-tuning. However, these techniques often result in catastrophic forgetting, where models lose previously learned capabilities. In catastrophic forgetting, regularization techniques like Elastic Weight Consolidation and architecture-based methods have been used to solve this issue, but they also have limitations. However, challenges persist in maintaining model quality while improving efficiency, especially for complex reasoning tasks.
A team from Cerebras Systems has proposed self-data distilled fine-tuning, a method to address the challenges associated with pruning and SFT in large language models. This approach utilizes the original, unpruned model to generate a distilled dataset that preserves semantic richness and mitigates catastrophic forgetting by maintaining alignment with the base model’s knowledge. This method shows significant improvement over standard SFT, with an increase in average accuracy by up to 8% on the HuggingFace OpenLLM Leaderboard v1. This approach scales effectively across datasets, with quality improvements correlating positively with dataset size.
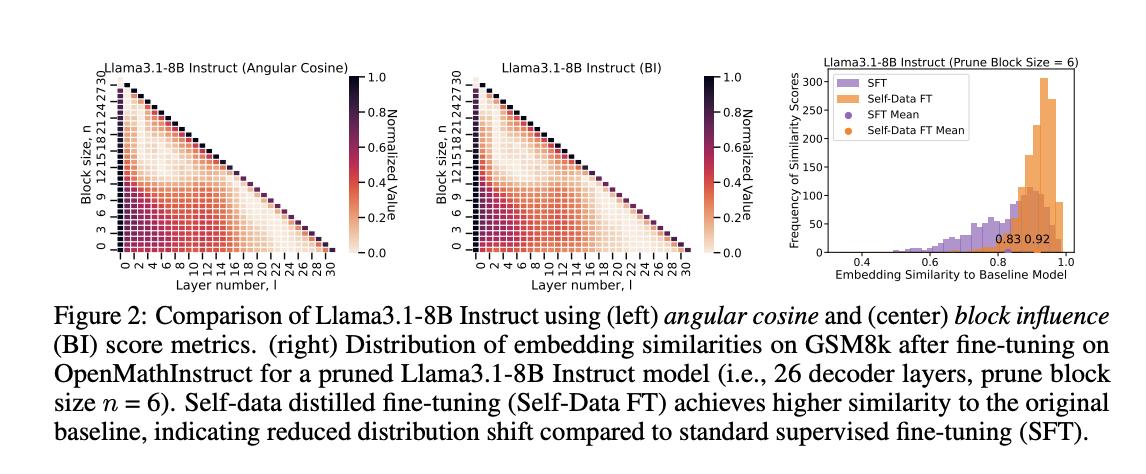
The methodology involves evaluating layer importance metrics, pruning block sizes, and fine-tuning strategies. Block Importance (BI) and angular cosine metrics are compared to determine layer redundancy, finding comparable results across block sizes. The proposed method uses LoRA fine-tuning on standard and self-distilled datasets, focusing on reasoning-heavy tasks. Models are evaluated on ARC-C, GSM8k, and MMLU tasks using LM-eval-harness. To reduce catastrophic forgetting, the researchers compared sentence embeddings of models fine-tuned on supervised and self-data distilled datasets. The self-data fine-tuned model preserves the original model’s learned representations compared to SFT.
The Llama3.1-8B Instruct models pruned at various block sizes are evaluated using three fine-tuning strategies: no fine-tuning, SFT, and self-data distillation. Pruned models without fine-tuning show a substantial loss in accuracy, highlighting the need for post-pruning adaptation. While SFT improved quality, achieving an average recovery of 81.66% at block size 6, it struggled with reasoning-heavy tasks. Self-data distillation significantly enhanced quality recovery, reaching 91.24% at block size 6, with great improvements in GSM8k accuracy. Moreover, the self-data distillation is improved using model merging called Spherical Linear Interpolation (SLERP). At block size 6, the merged model achieved a 93.30% recovery, outperforming the 91.24% recovery of the OpenMathInstruct model alone.
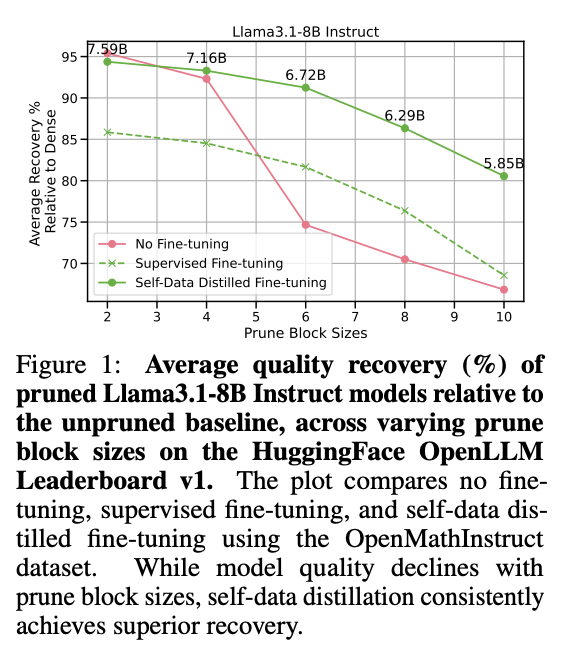
In conclusion, the team introduced self-data distilled fine-tuning, an effective method to counteract quality degradation in pruned Llama3.1-8B Instruct models. This approach outperforms standard SFT, showing superior accuracy recovery post-pruning across various tasks on the HuggingFace OpenLLM Leaderboard v1. The findings in this paper establish self-data distilled fine-tuning as a critical tool for maintaining high model quality post-pruning, providing an efficient solution for large-scale model compression. Future research includes integrating this technique with complementary compression methods, adopting fine-tuning strategies that leverage dynamically generated datasets or multi-modal inputs, and extending these methodologies to next-generation LLM architectures.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 50k+ ML SubReddit.
[Upcoming Live Webinar- Oct 29, 2024] The Best Platform for Serving Fine-Tuned Models: Predibase Inference Engine (Promoted)

Sajjad Ansari is a final year undergraduate from IIT Kharagpur. As a Tech enthusiast, he delves into the practical applications of AI with a focus on understanding the impact of AI technologies and their real-world implications. He aims to articulate complex AI concepts in a clear and accessible manner.
