Large Language Models (LLMs) have shown remarkable potential in solving complex real-world problems, from function calls to embodied planning and code generation. A critical capability for LLM agents is decomposing complex problems into executable subtasks through workflows, which serve as intermediate states to improve debugging and interpretability. While workflows provide prior knowledge to prevent hallucinations, current evaluation benchmarks for workflow generation face significant challenges. The challenges include (a) Limited scope of scenarios, focusing only on function call tasks, (b) Sole emphasis on linear relationships between subtasks where real-world scenarios often involve more complex graph structures, including parallelism (c) Evaluations heavily rely on GPT-3.5/4.
Existing methods in workflow generation have primarily focused on three key areas: Large Language Agents, Workflow and Agent Planning, and Workflow generation and Evaluation. While LLM agents have been deployed across various domains including web interfaces, medical applications, and coding tasks, their planning abilities involve either reasoning or environmental interaction. Existing evaluation frameworks attempt to evaluate workflow generation through semantic similarity matching and GPT-4 scoring in tool learning scenarios. However, these methods are limited by their focus on linear function-calling, inability to handle complex task structures, and heavy dependency on potentially biased evaluation methods.
Researchers from Zhejiang University and Alibaba Group have proposed WORFBENCH, a benchmark for evaluating workflow generation capabilities in LLM agents. This method addresses previous limitations by utilizing multi-faceted scenarios and complex workflow structures, validated through rigorous data filtering and human evaluation. Further, researchers presented WORFEVAL, a systematic evaluation protocol utilizing advanced subsequence and subgraph matching algorithms to evaluate chain and graph structure workflow generation. The experiments reveal there are significant performance gaps between sequence and graph planning capabilities, with even advanced models like GPT-4 showing approximately a 15% difference in performance.
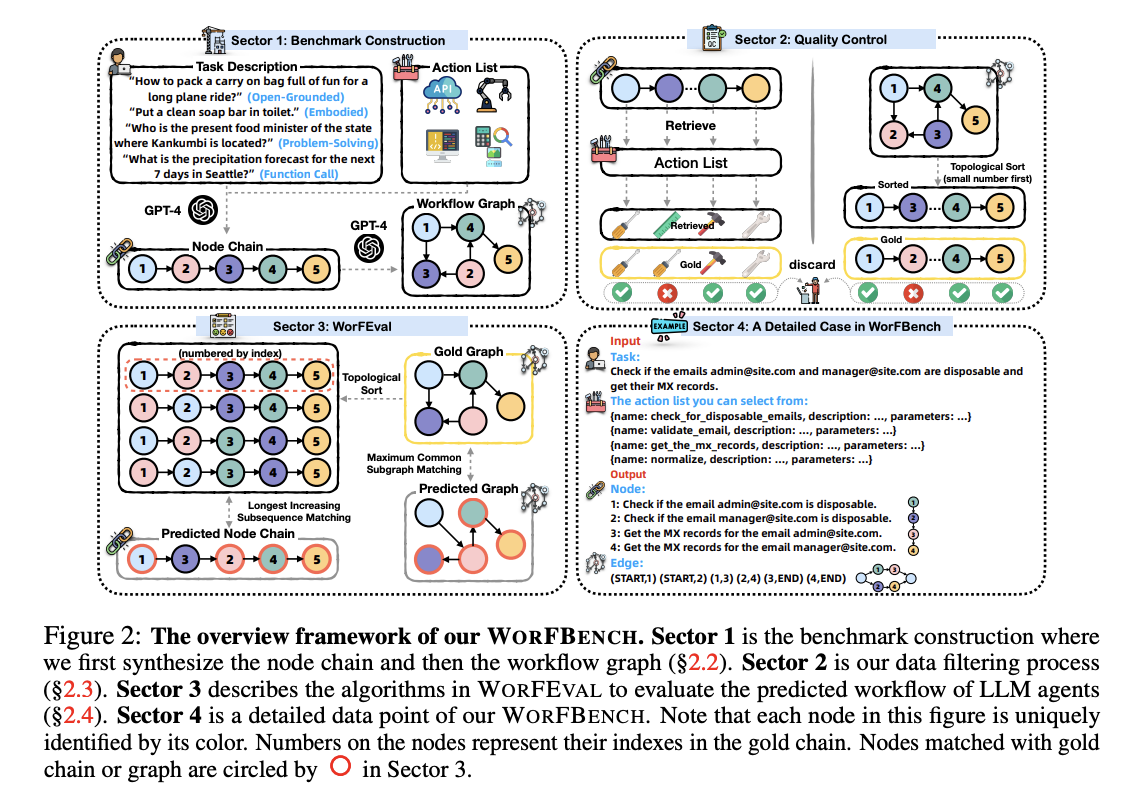
WORFBENCH’s architecture integrates tasks and action lists from established datasets, using a systematic approach of constructing node chains before building workflow graphs. The framework handles two main task categories:
- Function Call Tasks: The system uses GPT-4 to reverse-engineer thoughts from function calls using the REACT format, collected from ToolBench and ToolAlpaca. This generates subtask nodes for each step.
- Embodied Tasks: Drawn from sources like ALFWorld, WebShop, and AgentInstruct, these tasks require a unique approach due to their dynamic environmental nature. Instead of one-node-per-action mapping, these tasks are decomposed into fixed granularity, with carefully designed few-shot prompts for consistent workflow generation.
Performance analysis reveals significant disparities between linear and graph planning capabilities across all models. While GLM-4-9B showed the largest gap of 20.05%, even the best-performing Llama-3.1-70B demonstrated a 15.01% difference. In benchmark testing, GPT-4 achieved only 67.32% and 52.47% in f1chain and f1graph scores respectively, while Claude-3.5 topped open-grounded planning tasks with 61.73% and 41.49%. As workflow complexity increases, with more nodes and edges, performance consistently declines leading to lower scores. Analysis of low-performing samples identified four primary error types: inadequate task granularity, vague subtask descriptions, incorrect graph structures, and format non-compliance.
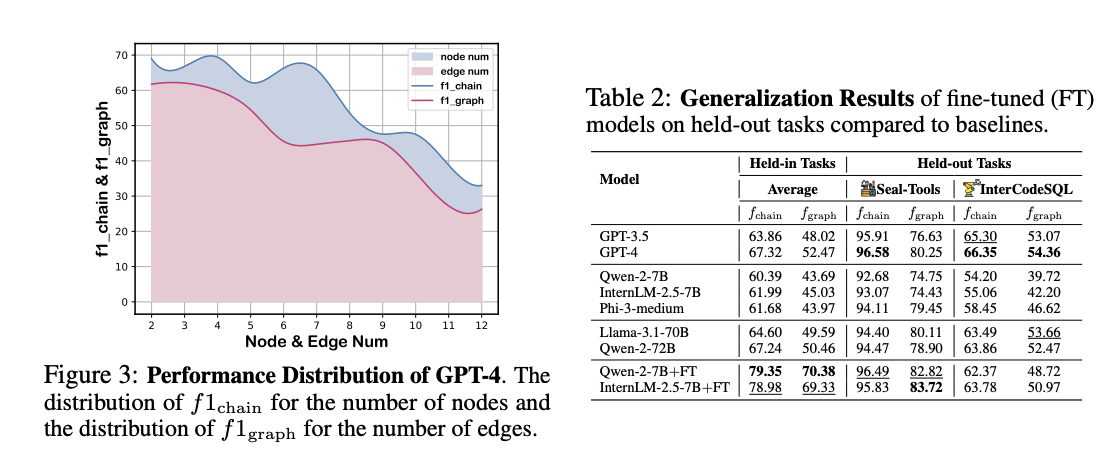
In conclusion, researchers introduced WORFBENCH, a method to evaluate workflow generation capabilities in LLM agents. Through the WORFEVAL system’s quantitative algorithms, the researchers revealed substantial performance gaps between linear and graph-structured workflow generation across various LLM architectures. The paper highlights the current limitations of LLM agents in complex workflow planning and provides a foundation for future improvements in agent architecture development. However, the proposed method has some limitations. While enforcing strict quality control on the node chain and workflow graph, some queries might have quality issues. Also, the workflow currently follows a one-pass generation paradigm and assumes all nodes require traversal to complete the task.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 55k+ ML SubReddit.
[Upcoming Live Webinar- Oct 29, 2024] The Best Platform for Serving Fine-Tuned Models: Predibase Inference Engine (Promoted)

Sajjad Ansari is a final year undergraduate from IIT Kharagpur. As a Tech enthusiast, he delves into the practical applications of AI with a focus on understanding the impact of AI technologies and their real-world implications. He aims to articulate complex AI concepts in a clear and accessible manner.
