Transformers have transformed artificial intelligence, offering unmatched performance in NLP, computer vision, and multi-modal data integration. These models excel at identifying patterns within data through their attention mechanisms, making them ideal for complex tasks. However, the rapid scaling of transformer models needs to be improved because of the high computational cost associated with their traditional structure. As these models grow, they demand significant hardware resources and training time, which increases exponentially with model size. Researchers have aimed to address these limitations by innovating more efficient methods to manage and scale transformer models without sacrificing performance.
The primary obstacle in scaling transformers lies in the fixed parameters within their linear projection layers. This static structure limits the model’s ability to expand without being entirely retrained, which becomes exponentially more expensive as model sizes increase. These traditional models typically demand comprehensive retraining when architectural modifications occur, such as increasing channel dimensions. Consequently, the computational cost for these expansions grows impractically high, and the approach lacks flexibility. The inability to add new parameters dynamically stifles growth, rendering these models less adaptable to evolving AI applications and more costly in terms of time and resources.
Historically, approaches to managing model scalability included duplicating weights or restructuring models using methods like Net2Net, where duplicating neurons expand layers. However, these approaches often disrupt the balance of pre-trained models, resulting in slower convergence rates and additional training complexities. While these methods have made incremental progress, they still face limitations in preserving model integrity during scaling. Transformers rely heavily on static linear projections, making parameter expansion expensive and inflexible. Traditional models like GPT and other large transformers often retrain from scratch, incurring high computational costs with each new scaling stage.
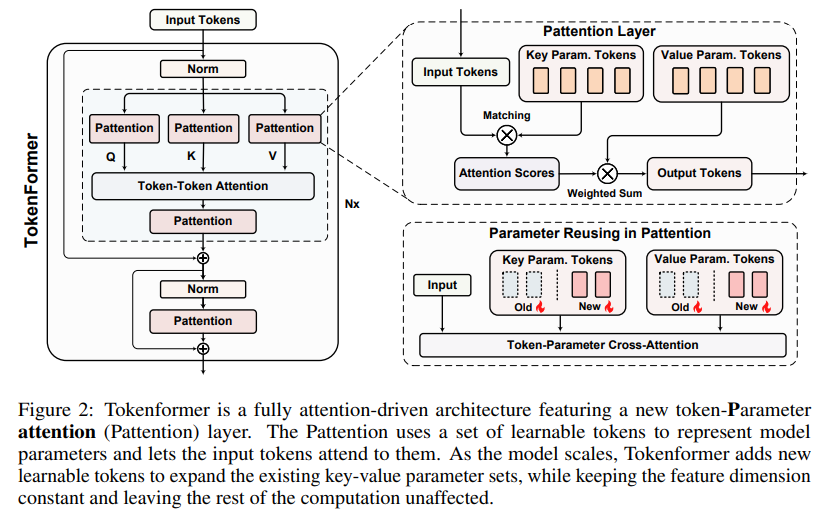
Researchers at the Max Planck Institute, Google, and Peking University developed a new architecture called Tokenformer. This model fundamentally reimagines transformers by treating model parameters as tokens, allowing for dynamic interactions between tokens and parameters. In this framework, Tokenformer introduces a novel component called the token-parameter attention (Pattention) layer, which facilitates incremental scaling. The model can add new parameter tokens without retraining, drastically reducing training costs. By representing input tokens and parameters within the same framework, Tokenformer allows for flexible scaling, providing researchers with a more efficient, resource-conscious model architecture that retains scalability and high performance.
Tokenformer’s Pattention layer uses input tokens as queries, while model parameters serve as keys and values, which differ from the standard transformer approach, relying solely on linear projections. The model’s scaling is achieved by adding new key-value parameter pairs, keeping input and output dimensions constant, and avoiding full retraining. Tokenformer’s architecture is designed to be modular, enabling researchers to expand the model seamlessly by incorporating additional tokens. This incremental scaling capability supports the efficient reuse of pre-trained weights while enabling rapid adaptation for new datasets or larger model sizes without disrupting learned information.
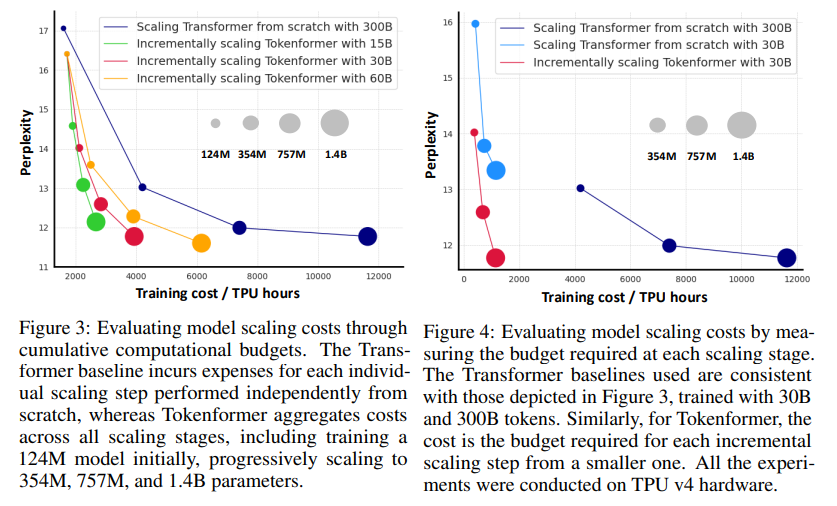
The performance benefits of Tokenformer are notable, as the model significantly reduces computational costs while maintaining accuracy. For instance, Tokenformer scaled from 124 million to 1.4 billion parameters with only half the typical training costs traditional transformers require. In one experiment, the model achieved a test perplexity of 11.77 for a 1.4 billion parameter configuration, nearly matching the 11.63 perplexity of a similarly sized transformer trained from scratch. This efficiency means Tokenformer can achieve high performance across multiple domains, including language and visual modeling tasks, at a fraction of the resource expenditure of traditional models.
Tokenformer presents numerous key takeaways for advancing AI research and improving transformer-based models. These include:
- Substantial Cost Savings: Tokenformer’s architecture reduced training costs by more than 50% compared to standard transformers. For instance, scaling from 124M to 1.4B parameters required only a fraction of the budget for scratch-trained transformers.
- Incremental Scaling with High Efficiency: The model supports incremental scaling by adding new parameter tokens without modifying core architecture, allowing flexibility and reduced retraining demands.
- Preservation of Learned Information: The tokenformer retains knowledge from smaller, pre-trained models, accelerating convergence and preventing the loss of learned information during scaling.
- Enhanced Performance on Diverse Tasks: In benchmarks, Tokenformer achieved competitive accuracy levels across language and visual modeling tasks, showing its capability as a versatile foundational model.
- Optimized Token Interaction Cost: By decoupling token-token interaction costs from scaling, Tokenformer can more efficiently manage longer sequences and larger models.

In conclusion, Tokenformer offers a transformative approach to scaling transformer-based models. This model architecture achieves scalability and resource efficiency by treating parameters as tokens, reducing costs, and preserving model performance across tasks. This flexibility represents a breakthrough in transformer design, providing a model that can adapt to the demands of advancing AI applications without retraining. Tokenformer’s architecture holds promise for future AI research, offering a pathway to develop large-scale models sustainably and efficiently.
Check out the Paper, GitHub Page, and Models on HuggingFace. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 55k+ ML SubReddit.
[Sponsorship Opportunity with us] Promote Your Research/Product/Webinar with 1Million+ Monthly Readers and 500k+ Community Members
Sana Hassan, a consulting intern at Marktechpost and dual-degree student at IIT Madras, is passionate about applying technology and AI to address real-world challenges. With a keen interest in solving practical problems, he brings a fresh perspective to the intersection of AI and real-life solutions.
