Effective lesson structuring remains a critical challenge in educational settings, particularly when conversations and tutoring sessions need to address predefined topics or worksheet problems. Educators face the complex task of optimally allocating time across different problems while accommodating diverse student learning needs. This challenge is especially pronounced for novice teachers and those managing large student groups, who frequently struggle with time management and lesson organization. While evidence-based insights into lesson structuring could provide valuable feedback to educators, tutoring platforms, and curriculum developers, obtaining such insights at scale presents significant difficulties. The analysis of conversation structure around reference materials involves two distinct natural language processing challenges: discourse segmentation and information retrieval, each presenting unique complexities when applied to educational conversations where teaching approaches vary based on student needs.
Previous approaches to conversation analysis have primarily focused on discourse segmentation as a preprocessing step for retrieval or summarization tasks. Traditional methods segment conversations based on various criteria like speech acts, topics, or conversation stages, depending on the domain. When applied to educational contexts, specifically for problem-oriented segments in mathematics discussions, these conventional approaches face significant limitations. Standard segmentation methods operate under the assumption that conversations follow predictable patterns and structures, which proves inadequate for educational conversations that are inherently diverse and adaptable. Also, mathematical information retrieval presents unique challenges due to the complexity of representing mathematical expressions in their proper context. The distinctive nature of mathematical discourse, combined with the variable structure of educational conversations, has highlighted the inadequacy of existing approaches in effectively analyzing and retrieving problem-oriented segments from mathematical tutoring sessions.
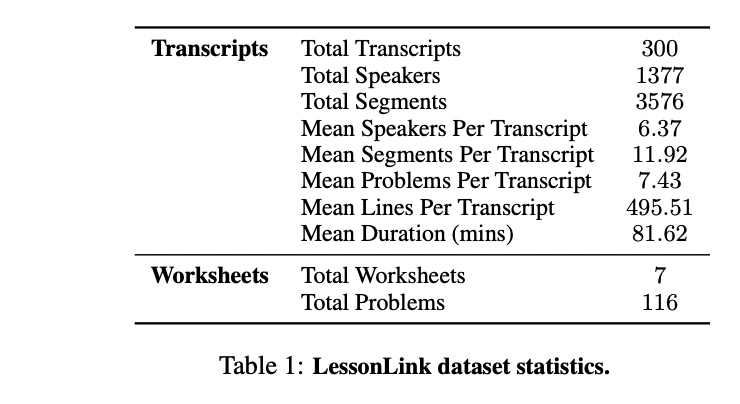
Researchers from Stanford University introduced the Problem-Oriented Segmentation and Retrieval (POSR) framework, a unique approach that simultaneously handles conversation segmentation and links these segments to corresponding reference materials. This integrated approach distinguishes itself from traditional methods by utilizing known reference topics to guide both segmentation and retrieval processes, particularly in educational contexts. The framework’s effectiveness is demonstrated through LessonLink, a comprehensive dataset designed to analyze mathematical tutoring sessions. LessonLink encompasses 3,500 segments drawn from real-world tutoring conversations, covering 116 SAT® math problems across more than 24,300 minutes of instruction. Each 1.5-hour conversation in the dataset is meticulously segmented and mapped to specific math problems, creating the first-ever collection that combines naturally structured conversations with their corresponding worksheet materials.
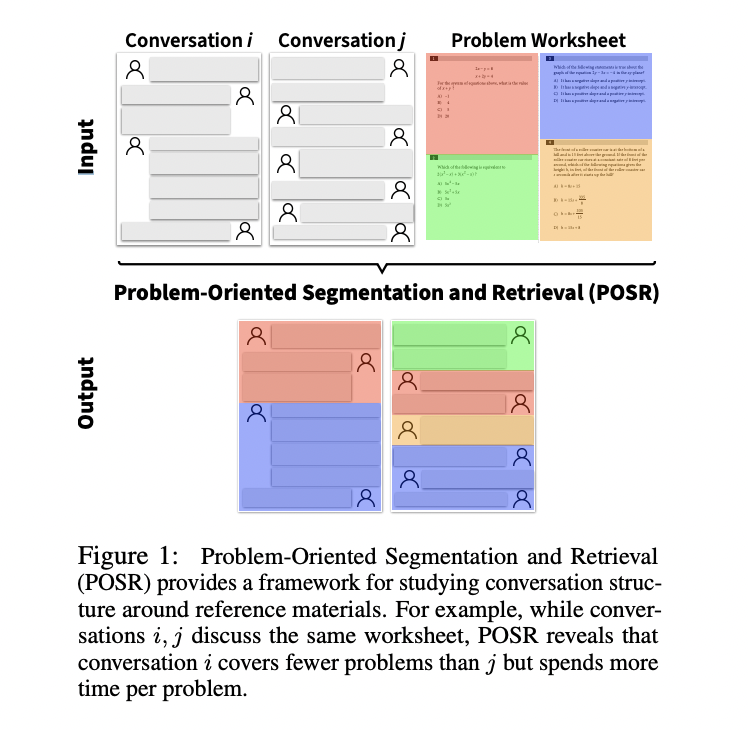
The POSR framework employs an innovative algorithmic approach that integrates segmentation and retrieval processes to analyze conversational transcripts more effectively. The system operates through a dual-phase process: first, it segments the conversation transcript while considering the available reference materials (unlike traditional methods that segment without this context), and second, it retrieves relevant topics or problems for each identified segment. This integrated approach enables better segmentation accuracy through awareness of potential retrieval topics while simultaneously improving retrieval precision through better-defined segments. When applied to the LessonLink dataset, the framework processes extensive tutoring conversations, handling input from 1,300 unique speakers and establishing connections to 116 distinct math problems. The algorithm’s design reflects a significant advancement over conventional methods by maintaining contextual awareness throughout both the segmentation and retrieval phases, leading to more accurate and meaningful analysis of educational conversations.

The experimental results demonstrate the superior performance of POSR methods compared to traditional independent segmentation and retrieval approaches. POSR Opus and POSR GPT4 achieved higher accuracy in both Line-SRS and Time-SRS metrics compared to their independent counterparts and combined independent approaches like Opus+TFIDF. Also, POSR Opus showed significant improvement over conventional topic and stage segmentation methods, reducing error rates by approximately 57% on both Pk and WindowDiff metrics. The framework’s cost-effectiveness is particularly noteworthy, with POSR methods requiring only $11-$21 per 100 transcripts, compared to $54 for combined independent methods like Opus+GPT4. The poor performance of word-level segmentation approaches (top-10 and top-20) highlighted the necessity of more sophisticated analysis methods. Both time-based and line-based metrics showed strong correlation across methods, though time-weighted metrics proved valuable in better handling long segment errors, with Time-Pk showing lower error rates than Line-Pk for over-segmentation cases.


The introduction of Problem-Oriented Segmentation and Retrieval (POSR) marks a significant advancement in analyzing educational conversations, particularly through its robust joint approach to segmentation and retrieval tasks. The framework’s effectiveness is validated through the LessonLink dataset, which provides unprecedented insights into real-world tutoring sessions. While LLM-based POSR methods demonstrate superior performance in accuracy metrics, their higher operational costs highlight the need for more cost-effective solutions. The framework’s success in analyzing tutoring strategies and conversation structures establishes POSR as a valuable tool for understanding and improving educational conversations.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 55k+ ML SubReddit.
[FREE AI WEBINAR] Implementing Intelligent Document Processing with GenAI in Financial Services and Real Estate Transactions– From Framework to Production
Asjad is an intern consultant at Marktechpost. He is persuing B.Tech in mechanical engineering at the Indian Institute of Technology, Kharagpur. Asjad is a Machine learning and deep learning enthusiast who is always researching the applications of machine learning in healthcare.
