Large language models (LLMs) excel in generating contextually relevant text; however, ensuring compliance with data privacy regulations, such as GDPR, requires a robust ability to unlearn specific information effectively. This capability is critical for addressing privacy concerns where data must be entirely removed from models and any logical connections that could reconstruct deleted information.
The problem of unlearning in LLMs is particularly challenging due to the interconnected nature of knowledge stored within these models. Removing a single fact is insufficient if related or deduced facts remain. For instance, removing a family relationship fact does not prevent the model from inferring it through logical rules or remaining connections. Addressing this issue necessitates unlearning approaches that consider explicit data and its logical dependencies.
Current unlearning methods focus on removing specific data points, such as gradient ascent, negative preference optimization (NPO), and task vector methods. These approaches aim to erase data while retaining overall model utility. However, they need to achieve deep unlearning, which involves removing the target fact and any inferable connections. This limitation compromises the completeness of data erasure and may lead to collateral damage, erasing unrelated facts unnecessarily.
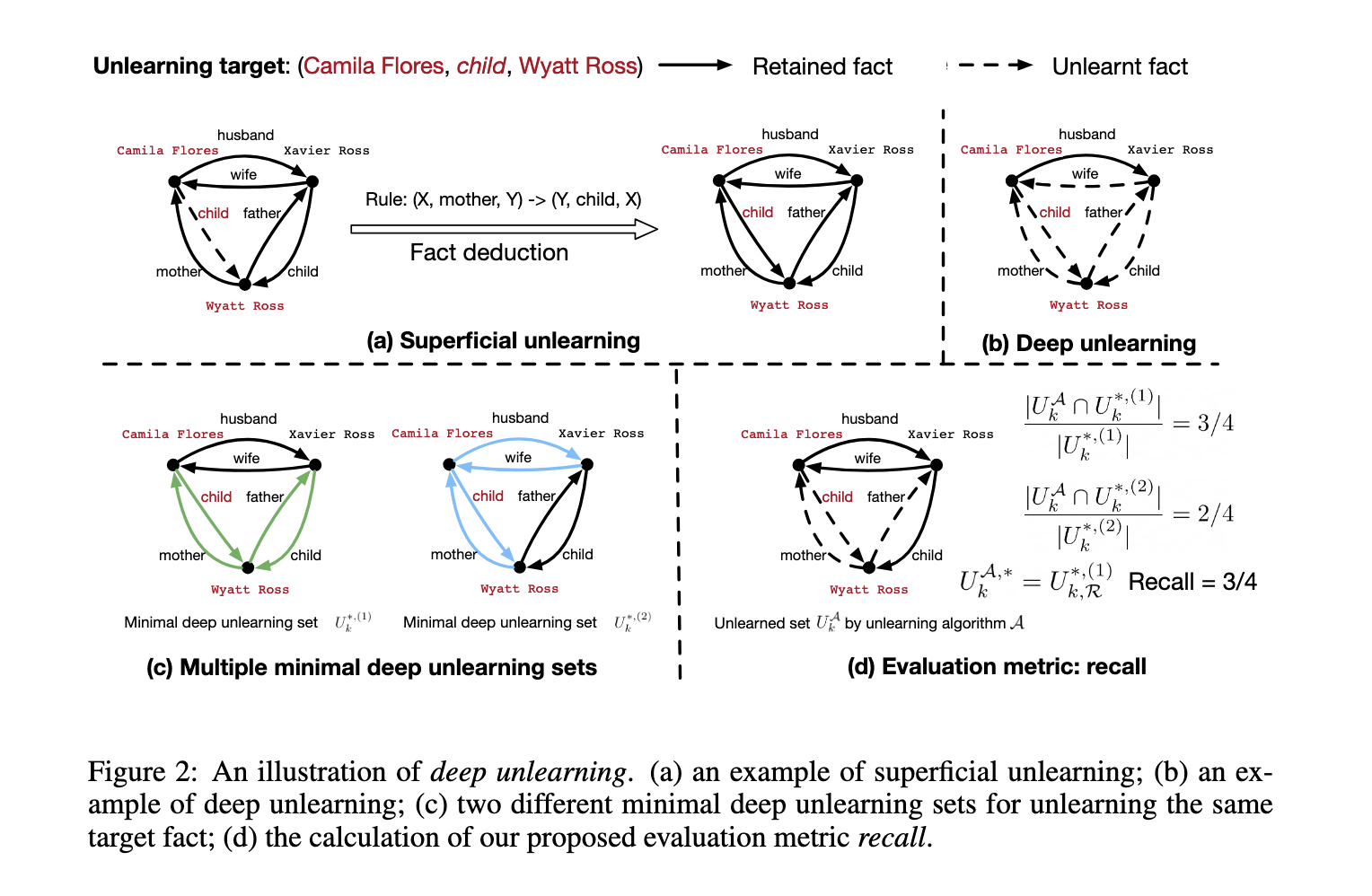
Researchers from the University of California, San Diego, & Carnegie Mellon University introduced the concept of “deep unlearning” to address these challenges. The research leverages a synthetic dataset, EDU-RELAT, consisting of 400 family relationships, 300 biographical facts, and 48 logical rules. These serve as a benchmark for evaluating unlearning methods. Key metrics such as recall, which measures the extent of unlearning, and accuracy, which assesses the preservation of unrelated facts, were used to evaluate performance.
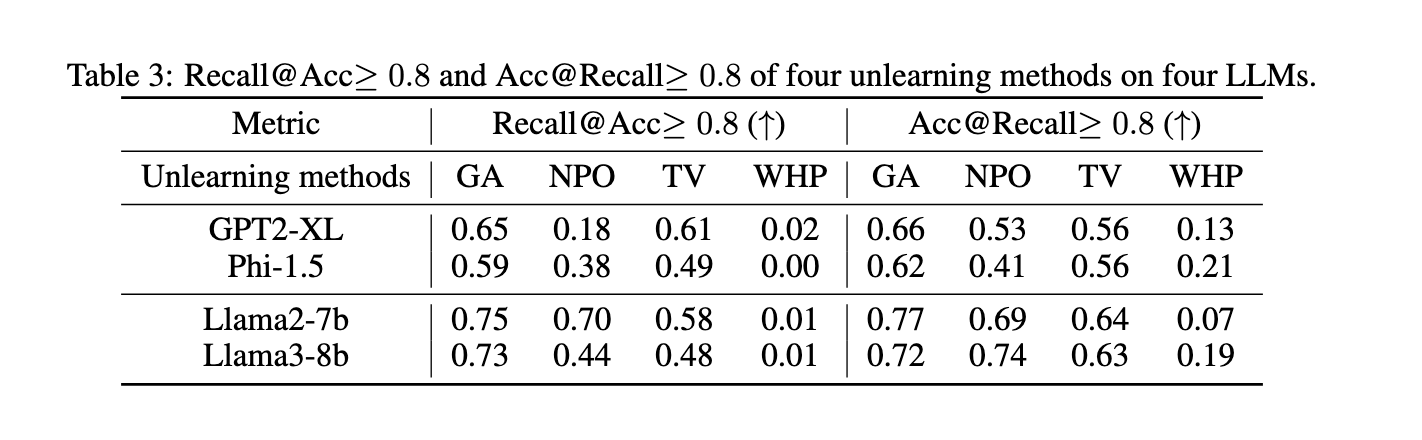
In the study, the researchers tested four unlearning techniques—Gradient Ascent (GA), Negative Preference Optimization (NPO), Task Vector (TV), and Who’s Harry Potter (WHP)—on four prominent LLMs: GPT2-XL, Phi-1.5, Llama2-7b, and Llama3-8b. The evaluation focused on deeply unlearning 55 specific facts related to family relationships. The study measured both Acc@Recall ≥ 0.8 (accuracy when a recall is above 80%) and Recall@Acc ≥ 0.8 (recall when accuracy is above 80%) to balance comprehensiveness and utility.
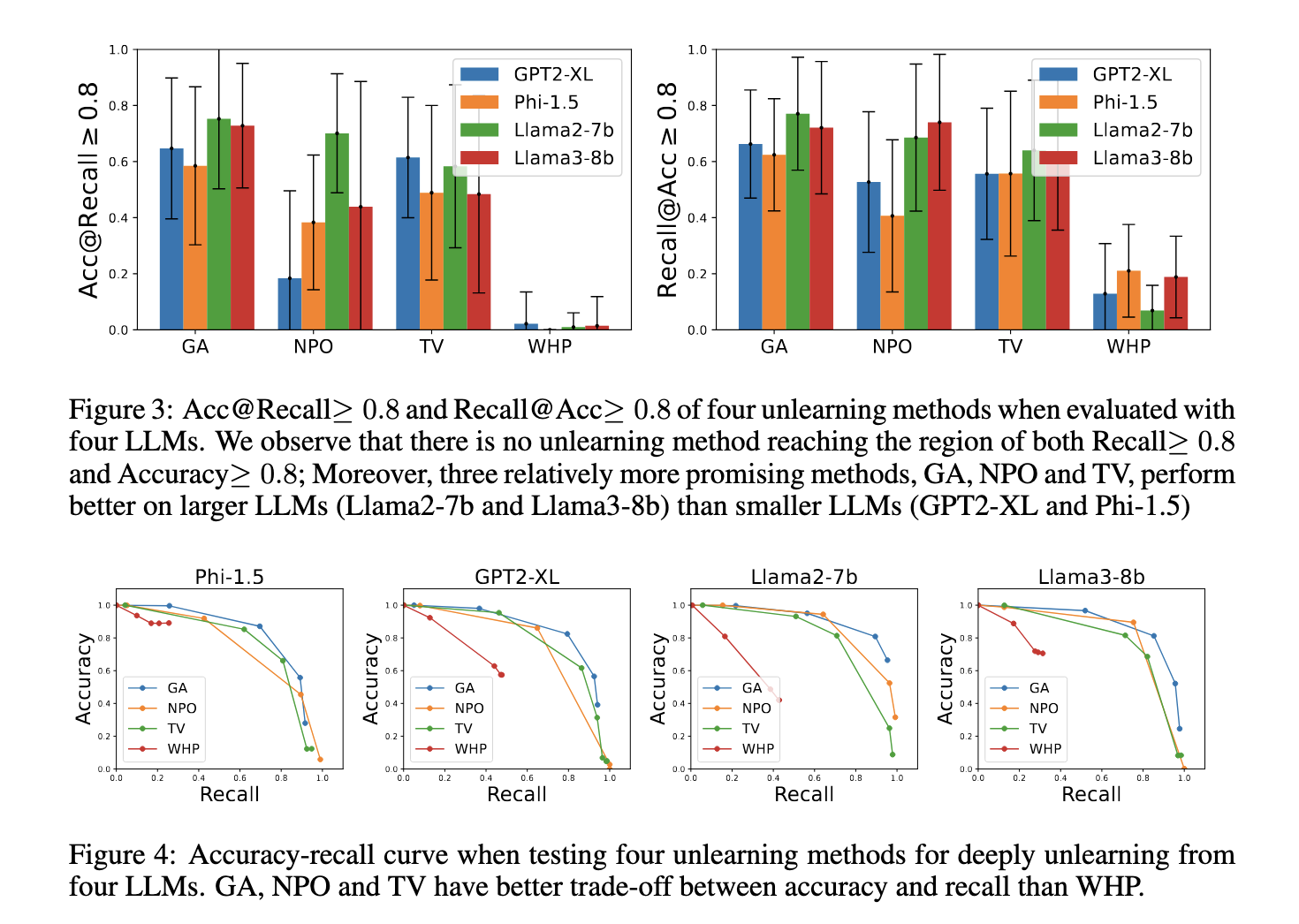
The results highlighted significant areas for improvement in existing unlearning methods—none of the methods achieved high recall and accuracy. For example, Gradient Ascent achieved a recall of 75% on Llama2-7b but often caused collateral damage by unlearning unrelated facts. NPO and Task Vector achieved recall rates between 70%-73% on larger models, such as Llama3-8b. In contrast, WHP performed poorly, with recall rates below 50% across all models. Larger models like Llama2-7b and Llama3-8b outperformed smaller ones like GPT2-XL and Phi-1.5 due to their more advanced reasoning capabilities, which aided in better handling logical dependencies.
Additional analysis revealed that the accuracy of biographical facts was generally higher than that of family relationships. For instance, GA achieved an Acc@Recall ≥ 0.8 for biographical facts on Llama2-7b and Llama3-8b but only 0.6 for family relationships. This discrepancy highlights the difficulty in unlearning closely related facts without unintended losses. Unlearning a single fact often required removing ten or more related facts, demonstrating the complexity of deep unlearning.
The research underscores the limitations of current approaches in achieving effective deep unlearning. While methods like Gradient Ascent showed potential for superficial unlearning, they needed to be more for deeply interconnected datasets. The study concludes with a call for comprehensively developing new methodologies that address these challenges. By establishing deep unlearning as a benchmark, this research lays the groundwork for advancements in privacy-preserving AI and highlights the importance of balancing unlearning efficacy with model utility.
Check out the Paper and GitHub Page. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 60k+ ML SubReddit.
🚨 [Must Attend Webinar]: ‘Transform proofs-of-concept into production-ready AI applications and agents’ (Promoted)
Nikhil is an intern consultant at Marktechpost. He is pursuing an integrated dual degree in Materials at the Indian Institute of Technology, Kharagpur. Nikhil is an AI/ML enthusiast who is always researching applications in fields like biomaterials and biomedical science. With a strong background in Material Science, he is exploring new advancements and creating opportunities to contribute.
