Natural Language Generation (NLG) is a domain of artificial intelligence that seeks to enable machines to produce human-like text. By leveraging advancements in deep learning, researchers aim to develop systems capable of generating contextually relevant and coherent responses. Applications of this technology span diverse areas, including automated customer support, creative writing, and real-time language translation, emphasizing seamless communication between humans and machines.
A key challenge in this domain lies in assessing the certainty of machine-generated text. Due to their probabilistic nature, language models may produce various outputs for the same input prompt. This variability raises concerns about the generated content’s reliability and the model’s confidence in its predictions. Addressing this issue is critical for applications where consistency and accuracy are paramount, such as medical or legal documentation.
To estimate uncertainty in generated text, traditional approaches rely on sampling multiple output sequences and analyzing them collectively. These methods, while insightful, demand significant computational resources since generating multiple sequences is computationally expensive. Consequently, the practicality of such methods diminishes for larger-scale deployments or tasks involving complex language models.
Researchers from the ELLIS Unit Linz and LIT AI Lab at Johannes Kepler University Linz, Austria, introduced a novel approach, G-NLL, to streamline the uncertainty estimation process. This method is based on computing the most probable output sequence’s negative log-likelihood (NLL). Unlike earlier approaches that rely on sampling, G-NLL uses greedy decoding to identify the most probable sequence and evaluate its likelihood. By focusing on this singular sequence, the method bypasses the need for extensive computational overhead, making it a more efficient alternative.
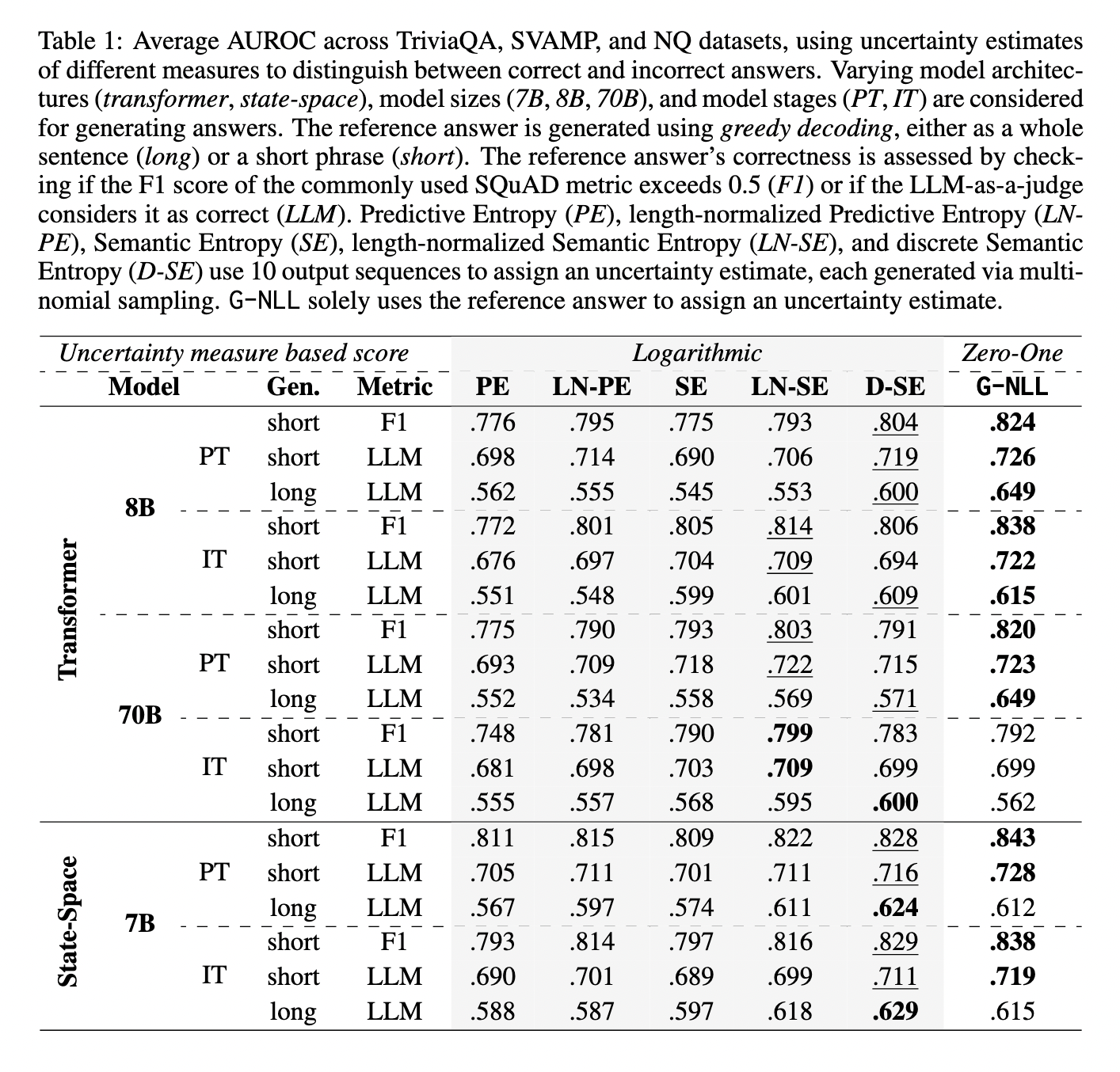
The G-NLL methodology involves calculating the probability of the most likely output sequence generated by a model. The negative log-likelihood of this sequence serves as a direct measure of uncertainty, with lower values indicating greater confidence in the generated text. This approach eliminates the redundancy of generating multiple sequences while maintaining the robustness required for effective uncertainty estimation. Further, the method integrates seamlessly with existing language models, requiring minimal modification to the decoding process.
Empirical evaluations of G-NLL demonstrated its superior performance across various tasks and models. Researchers tested the method on datasets commonly used for benchmarking language generation tasks, including machine translation and summarization. G-NLL consistently matched or surpassed the performance of traditional sampling-based methods. For instance, in a specific evaluation, the process reduced computational cost while maintaining accuracy levels on par with conventional techniques. Detailed results from experiments showed a significant efficiency improvement, with reduced computational demands by up to 50% in some tasks.
By addressing a critical limitation in NLG systems, the researchers provided a practical and scalable solution for estimating uncertainty. G-NLL represents a step forward in making language models more accessible for applications that require high reliability and computational efficiency. The innovation offers potential benefits for industries relying on automated text generation, including healthcare, education, and customer service, where confidence in outputs is crucial.
In conclusion, this research tackles the fundamental problem of uncertainty estimation in machine-generated text by introducing G-NLL. The method simplifies the process, reduces computational costs, and achieves strong performance across multiple benchmarks, solidifying its contribution to NLG. This advancement sets a new standard for efficiency and reliability in uncertainty estimation methods, paving the way for the broader adoption of language generation systems.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. Don’t Forget to join our 60k+ ML SubReddit.
Nikhil is an intern consultant at Marktechpost. He is pursuing an integrated dual degree in Materials at the Indian Institute of Technology, Kharagpur. Nikhil is an AI/ML enthusiast who is always researching applications in fields like biomaterials and biomedical science. With a strong background in Material Science, he is exploring new advancements and creating opportunities to contribute.
