In recent years, artificial intelligence agents have succeeded in a range of complex game environments. For instance, AlphaZero beat world-champion programs in chess, shogi, and Go after starting out with knowing no more than the basic rules of how to play. Through reinforcement learning (RL), this single system learnt by playing round after round of games through a repetitive process of trial and error. But AlphaZero still trained separately on each game — unable to simply learn another game or task without repeating the RL process from scratch. The same is true for other successes of RL, such as Atari, Capture the Flag, StarCraft II, Dota 2, and Hide-and-Seek. DeepMind’s mission of solving intelligence to advance science and humanity led us to explore how we could overcome this limitation to create AI agents with more general and adaptive behaviour. Instead of learning one game at a time, these agents would be able to react to completely new conditions and play a whole universe of games and tasks, including ones never seen before.
Today, we published “Open-Ended Learning Leads to Generally Capable Agents,” a preprint detailing our first steps to train an agent capable of playing many different games without needing human interaction data. We created a vast game environment we call XLand, which includes many multiplayer games within consistent, human-relatable 3D worlds. This environment makes it possible to formulate new learning algorithms, which dynamically control how an agent trains and the games on which it trains. The agent’s capabilities improve iteratively as a response to the challenges that arise in training, with the learning process continually refining the training tasks so the agent never stops learning. The result is an agent with the ability to succeed at a wide spectrum of tasks — from simple object-finding problems to complex games like hide and seek and capture the flag, which were not encountered during training. We find the agent exhibits general, heuristic behaviours such as experimentation, behaviours that are widely applicable to many tasks rather than specialised to an individual task. This new approach marks an important step toward creating more general agents with the flexibility to adapt rapidly within constantly changing environments.
A universe of training tasks
A lack of training data — where “data” points are different tasks — has been one of the major factors limiting RL-trained agents’ behaviour being general enough to apply across games. Without being able to train agents on a vast enough set of tasks, agents trained with RL have been unable to adapt their learnt behaviours to new tasks. But by designing a simulated space to allow for procedurally generated tasks, our team created a way to train on, and generate experience from, tasks that are created programmatically. This enables us to include billions of tasks in XLand, across varied games, worlds, and players.
Our AI agents inhabit 3D first-person avatars in a multiplayer environment meant to simulate the physical world. The players sense their surroundings by observing RGB images and receive a text description of their goal, and they train on a range of games. These games are as simple as cooperative games to find objects and navigate worlds, where the goal for a player could be “be near the purple cube.” More complex games can be based on choosing from multiple rewarding options, such as “be near the purple cube or put the yellow sphere on the red floor,” and more competitive games include playing against co-players, such as symmetric hide and seek where each player has the goal, “see the opponent and make the opponent not see me.” Each game defines the rewards for the players, and each player’s ultimate objective is to maximise the rewards.
Because XLand can be programmatically specified, the game space allows for data to be generated in an automated and algorithmic fashion. And because the tasks in XLand involve multiple players, the behaviour of co-players greatly influences the challenges faced by the AI agent. These complex, non-linear interactions create an ideal source of data to train on, since sometimes even small changes in the components of the environment can result in large changes in the challenges for the agents.

Training methods
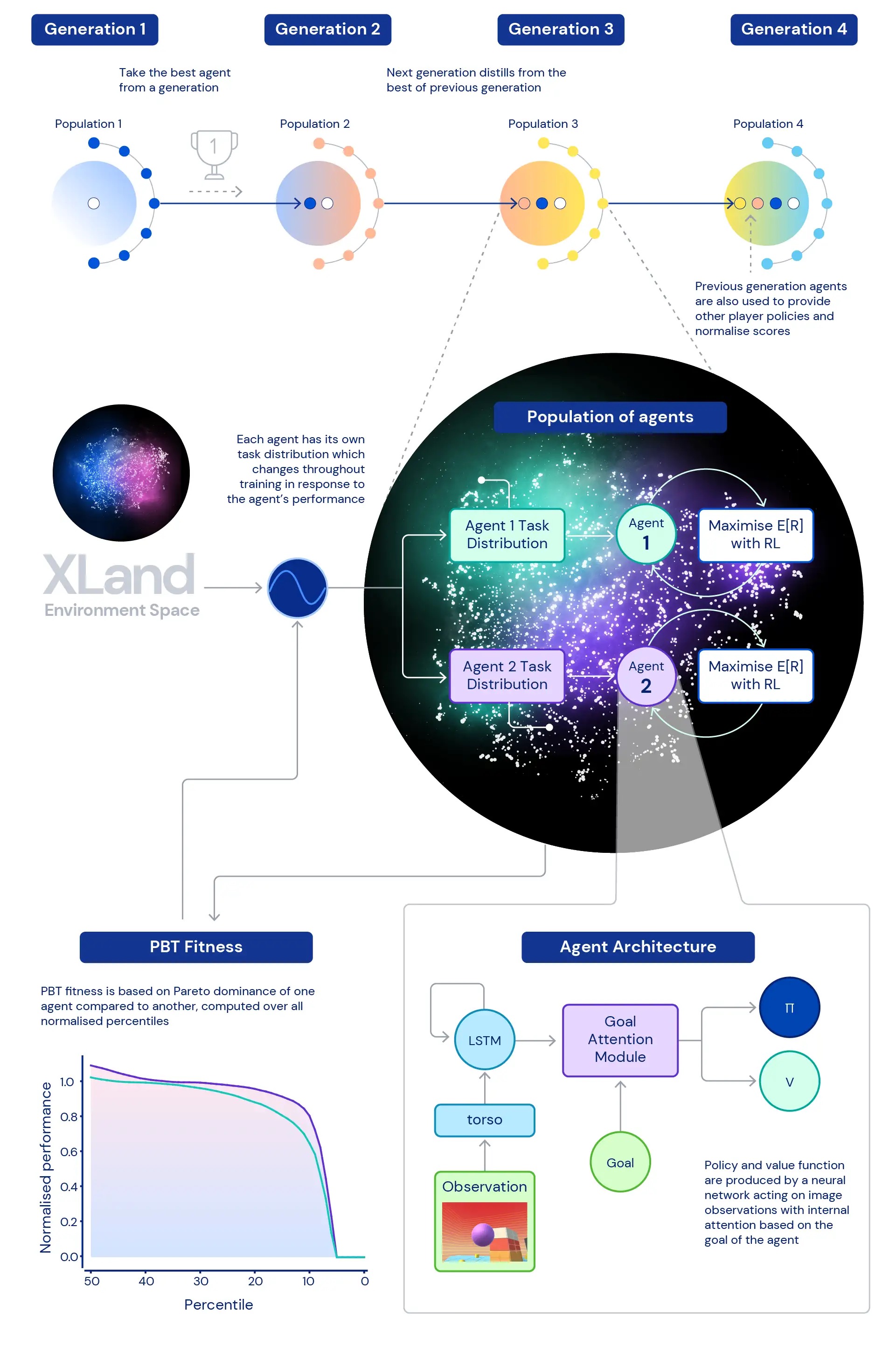
Central to our research is the role of deep RL in training the neural networks of our agents. The neural network architecture we use provides an attention mechanism over the agent’s internal recurrent state — helping guide the agent’s attention with estimates of subgoals unique to the game the agent is playing. We’ve found this goal-attentive agent (GOAT) learns more generally capable policies.
We also explored the question, what distribution of training tasks will produce the best possible agent, especially in such a vast environment? The dynamic task generation we use allows for continual changes to the distribution of the agent’s training tasks: every task is generated to be neither too hard nor too easy, but just right for training. We then use population based training (PBT) to adjust the parameters of the dynamic task generation based on a fitness that aims to improve agents’ general capability. And finally we chain together multiple training runs so each generation of agents can bootstrap off the previous generation.
This leads to a final training process with deep RL at the core updating the neural networks of agents with every step of experience:
- the steps of experience come from training tasks that are dynamically generated in response to agents’ behaviour,
- agents’ task-generating functions mutate in response to agents’ relative performance and robustness,
- at the outermost loop, the generations of agents bootstrap from each other, provide ever richer co-players to the multiplayer environment, and redefine the measurement of progression itself.
The training process starts from scratch and iteratively builds complexity, constantly changing the learning problem to keep the agent learning. The iterative nature of the combined learning system, which does not optimise a bounded performance metric but rather the iteratively defined spectrum of general capability, leads to a potentially open-ended learning process for agents, limited only by the expressivity of the environment space and agent neural network.
Measuring progress
To measure how agents perform within this vast universe, we create a set of evaluation tasks using games and worlds that remain separate from the data used for training. These “held-out” tasks include specifically human-designed tasks like hide and seek and capture the flag.
Because of the size of XLand, understanding and characterising the performance of our agents can be a challenge. Each task involves different levels of complexity, different scales of achievable rewards, and different capabilities of the agent, so merely averaging the reward over held out tasks would hide the actual differences in complexity and rewards — and would effectively treat all tasks as equally interesting, which isn’t necessarily true of procedurally generated environments.
To overcome these limitations, we take a different approach. Firstly, we normalise scores per task using the Nash equilibrium value computed using our current set of trained players. Secondly, we take into account the entire distribution of normalised scores — rather than looking at average normalised scores, we look at the different percentiles of normalised scores — as well as the percentage of tasks in which the agent scores at least one step of reward: participation. This means an agent is considered better than another agent only if it exceeds performance on all percentiles. This approach to measurement gives us a meaningful way to assess our agents’ performance and robustness.
More generally capable agents
After training our agents for five generations, we saw consistent improvements in learning and performance across our held-out evaluation space. Playing roughly 700,000 unique games in 4,000 unique worlds within XLand, each agent in the final generation experienced 200 billion training steps as a result of 3.4 million unique tasks. At this time, our agents have been able to participate in every procedurally generated evaluation task except for a handful that were impossible even for a human. And the results we’re seeing clearly exhibit general, zero-shot behaviour across the task space — with the frontier of normalised score percentiles continually improving.
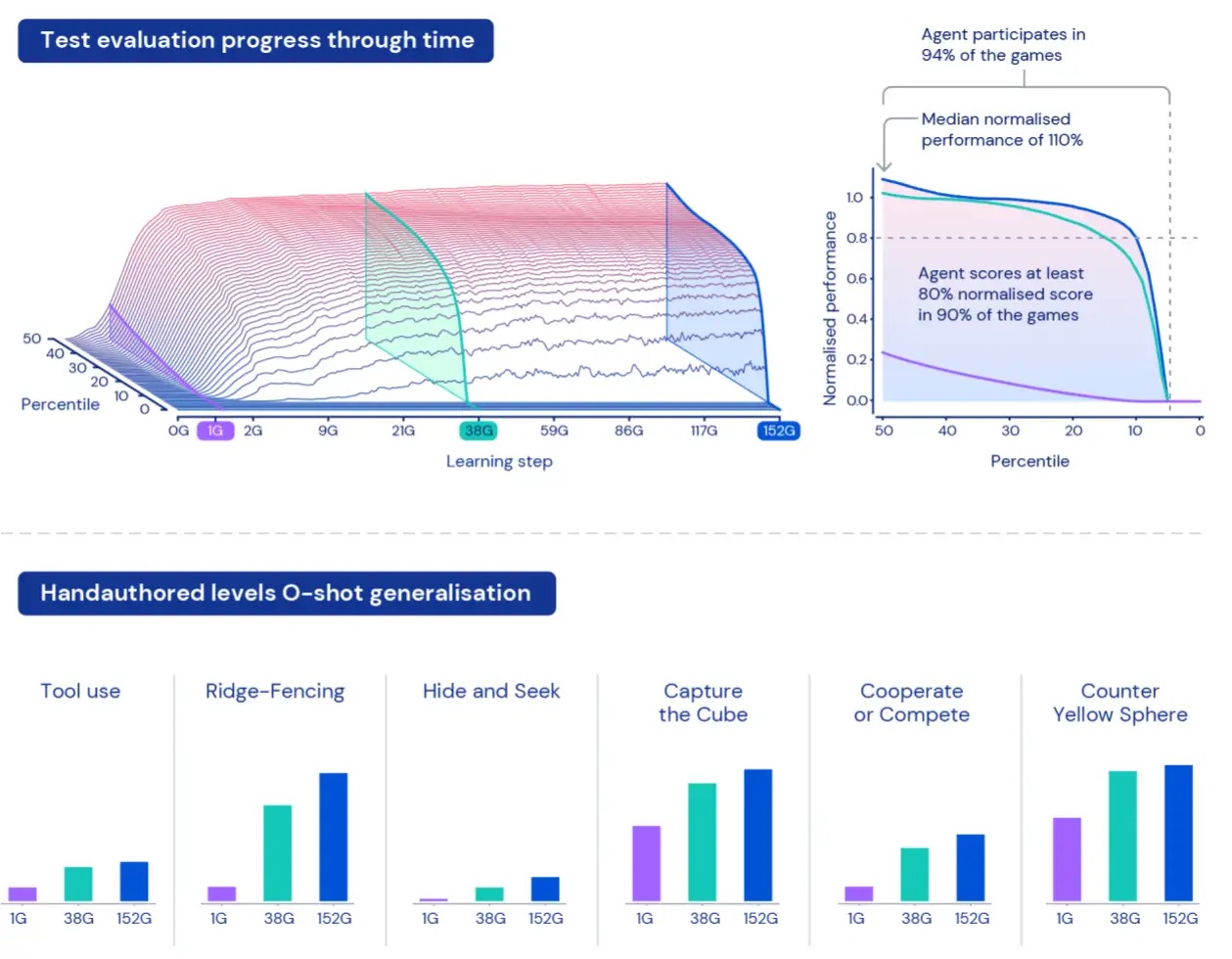
Looking qualitatively at our agents, we often see general, heuristic behaviours emerge — rather than highly optimised, specific behaviours for individual tasks. Instead of agents knowing exactly the “best thing” to do in a new situation, we see evidence of agents experimenting and changing the state of the world until they’ve achieved a rewarding state. We also see agents rely on the use of other tools, including objects to occlude visibility, to create ramps, and to retrieve other objects. Because the environment is multiplayer, we can examine the progression of agent behaviours while training on held-out social dilemmas, such as in a game of “chicken”. As training progresses, our agents appear to exhibit more cooperative behaviour when playing with a copy of themselves. Given the nature of the environment, it is difficult to pinpoint intentionality — the behaviours we see often appear to be accidental, but still we see them occur consistently.
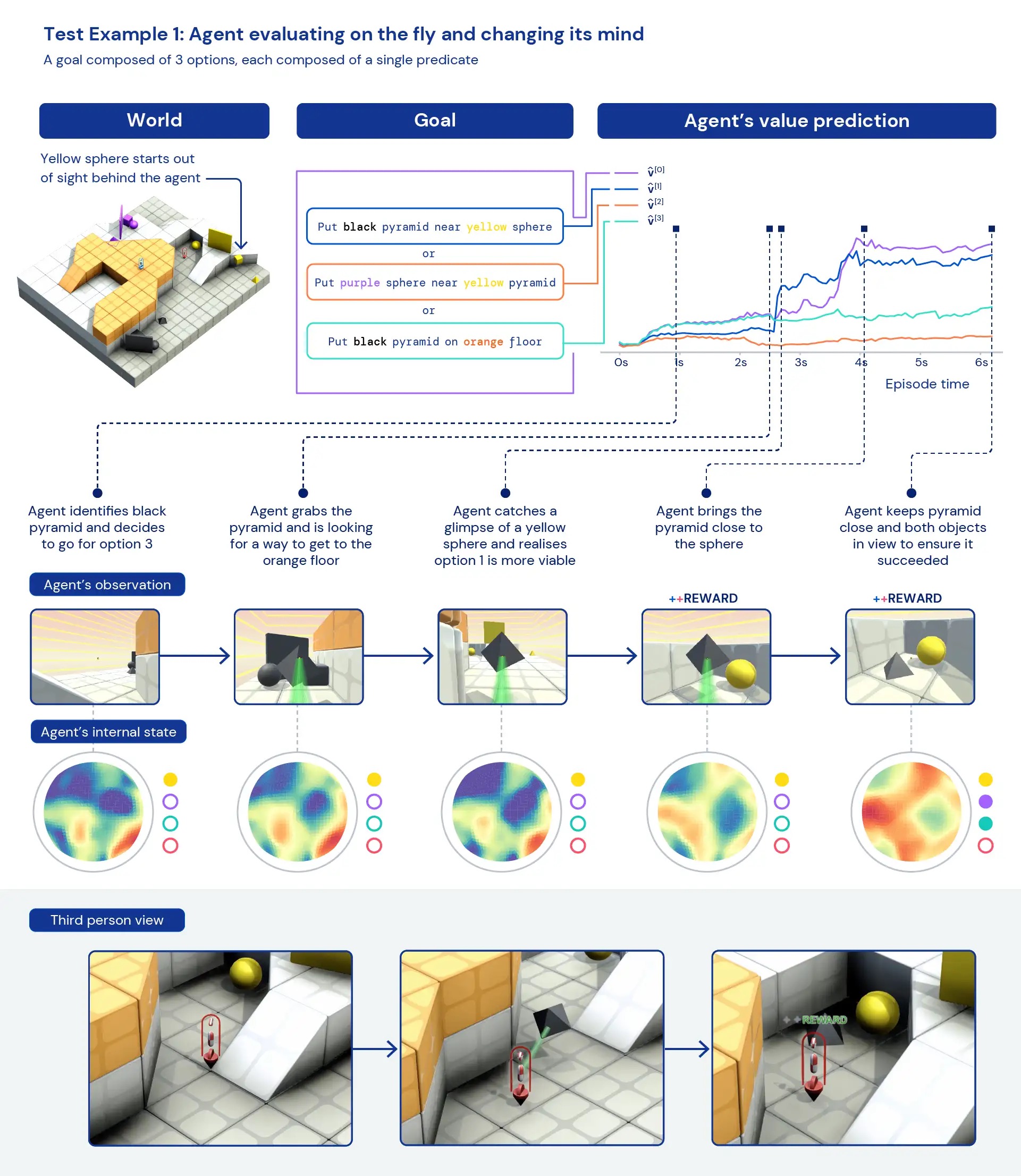
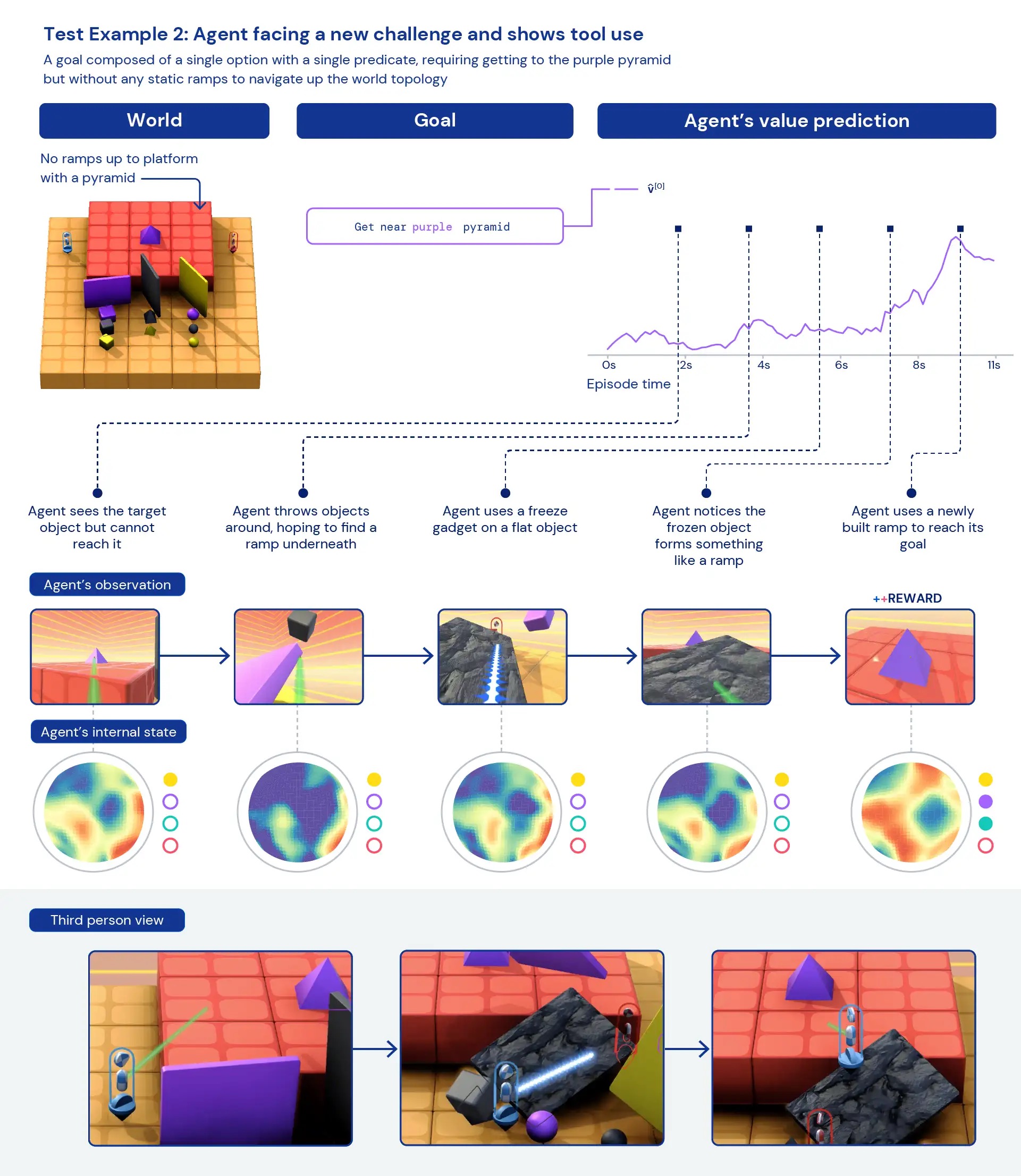
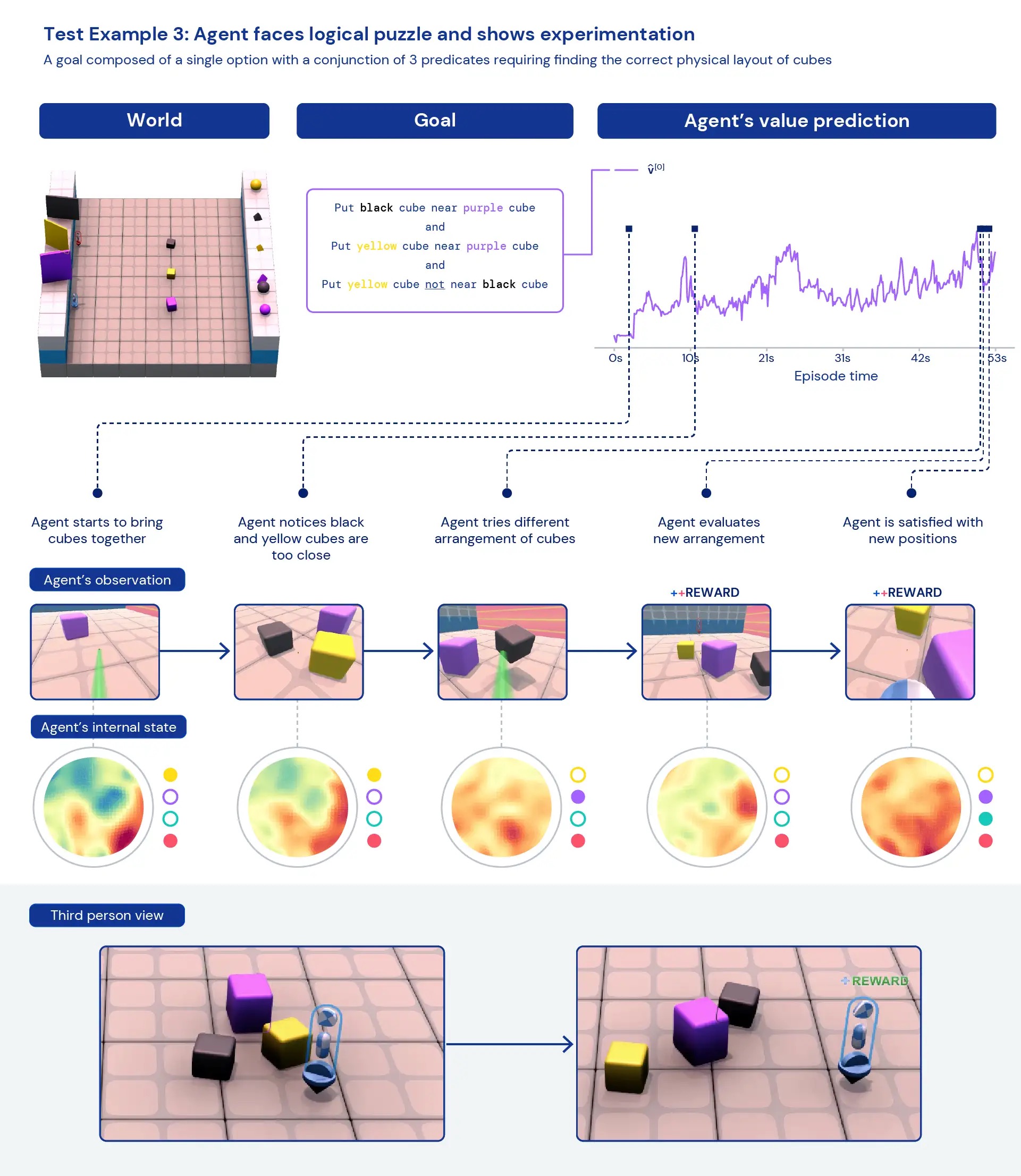



Analysing the agent’s internal representations, we can say that by taking this approach to reinforcement learning in a vast task space, our agents are aware of the basics of their bodies and the passage of time and that they understand the high-level structure of the games they encounter. Perhaps even more interestingly, they clearly recognise the reward states of their environment. This generality and diversity of behaviour in new tasks hints toward the potential to fine-tune these agents on downstream tasks. For instance, we show in the technical paper that with just 30 minutes of focused training on a newly presented complex task, the agents can quickly adapt, whereas agents trained with RL from scratch cannot learn these tasks at all.
By developing an environment like XLand and new training algorithms that support the open-ended creation of complexity, we’ve seen clear signs of zero-shot generalisation from RL agents. Whilst these agents are starting to be generally capable within this task space, we look forward to continuing our research and development to further improve their performance and create ever more adaptive agents.
For more details, see the preprint of our technical paper — and videos of the results we’ve seen. We hope this could help other researchers likewise see a new path toward creating more adaptive, generally capable AI agents. If you’re excited by these advances, consider joining our team.
