Recent advancements in Large Language Models (LLMs) have led to models containing billions or even trillions of parameters, achieving remarkable performance across domains. However, their massive size poses challenges in practical deployment due to stringent hardware requirements. Research has focused on scaling models to enhance performance, guided by established scaling laws. This escalation underscores the need to address hardware limitations to facilitate the widespread utilization of these powerful LLMs.
Prior works address the challenge of deploying massive trained models by focusing on model compression techniques. These techniques, including quantization and pruning, aim to reduce inference costs. While quantization lowers precision, pruning removes redundant parameters without retraining. Recent advancements in pruning techniques have shown promise in simplifying model compression for large language models, highlighting the importance of exploring efficient pruning approaches tailored for such models.
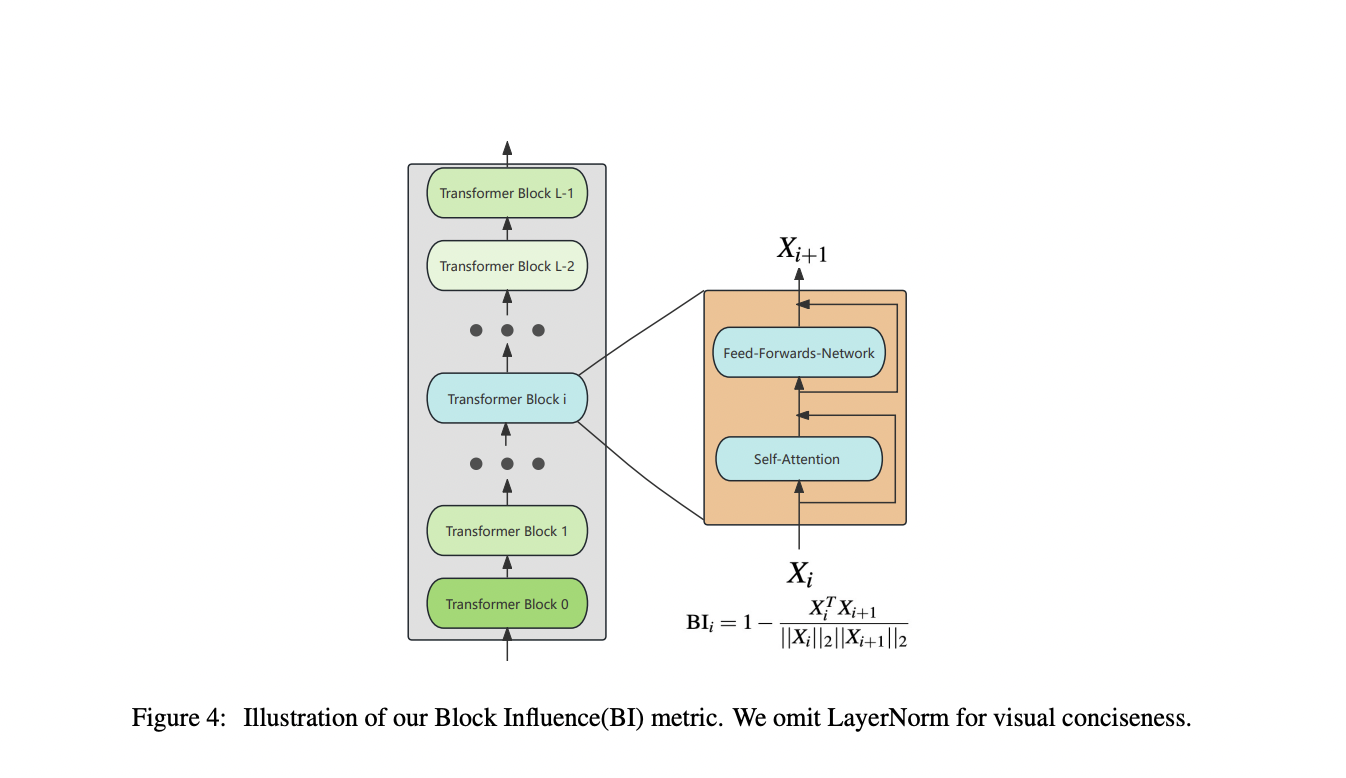
The researchers from Baichuan Inc. and the Chinese Information Processing Laboratory Institute of Software, Chinese Academy of Sciences, present a unique approach, ShortGPT, to analyze layer-wise redundancy in LLMs using Block Influence (BI), measuring hidden state transformations. Their method significantly outperforms previous complex pruning techniques by identifying and removing redundant layers based on BI scores. They demonstrate that LLMs exhibit substantial layer redundancy, offering a straightforward yet effective pruning strategy. This method, orthogonal to quantization, reduces parameters and computation while maintaining high performance, paving the way for more efficient LLM training.
Their proposed LLM layer deletion approach begins by quantifying layer redundancy, particularly in Transformer-based architectures. BI metric assesses each layer’s impact on hidden state transformations during inference. Layers with low BI scores, indicating minimal impact, are removed to reduce inference costs without compromising model performance. The method involves constructing a calibration set, collecting hidden states, calculating BI scores, and iteratively deleting less important layers based on BI rankings.
The proposed method’s comparative experiments against benchmarks (including MMLU, CMMLU, and CMNLI) and baseline techniques (including LLMPru, SliceGPT, and LaCo) are commonly used in LLM evaluation. Results show that the model pruned using the proposed approach consistently outperforms baseline methods across multiple natural language benchmarks. Also, reducing the number of layers proves more effective than reducing embedding dimensions, indicating deeper redundancy within the models.
In conclusion, the researchers from Baichuan Inc. and the Chinese Information Processing Laboratory Institute of Software, Chinese Academy of Sciences present ShortGPT, a unique LLM pruning approach based on layer redundancy and attention entropy. Results show significant layer-wise redundancy in LLMs, enabling the removal of minimally contributing layers without compromising performance. The proposed strategy maintains up to 95% of model performance while reducing parameter count and computational requirements by around 25%, surpassing previous pruning methods. This approach, simple yet effective, suggests depth-based redundancy in LLMs and offers compatibility with other compression techniques for versatile model size reduction.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and Google News. Join our 38k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
You may also like our FREE AI Courses….
Asjad is an intern consultant at Marktechpost. He is persuing B.Tech in mechanical engineering at the Indian Institute of Technology, Kharagpur. Asjad is a Machine learning and deep learning enthusiast who is always researching the applications of machine learning in healthcare.
