Recent advancements in large language models (LLMs) have significantly transformed the field of natural language processing (NLP), but their performance on existing benchmarks has begun to plateau. This stagnation makes it difficult to discern differences in model capabilities, hindering progress in AI research. Benchmarks like the Massive Multitask Language Understanding (MMLU) have played a crucial role in pushing the boundaries of what AI can achieve in language comprehension and reasoning across diverse domains. However, the need for more challenging and discriminative benchmarks has become apparent as models improve. The performance saturation on these benchmarks limits the ability to effectively evaluate newer, more advanced models. Additionally, the existing benchmarks often feature questions that are predominantly knowledge-driven with limited reasoning requirements, leading to inflated performance metrics and reduced robustness due to sensitivity to prompt variations.
Current methods, such as the original MMLU and other benchmarks like GLUE, SuperGLUE, and BigBench, have played pivotal roles in advancing language understanding tasks. However, these benchmarks primarily focus on knowledge-driven questions with limited reasoning requirements, leading to performance saturation among top-tier models like GPT-4, Gemini, and Claude. These methods also exhibit non-robustness to minor prompt variations, resulting in significant fluctuations in model scores and overestimating LLMs’ true performance. The typical multiple-choice question format, often limited to four options, fails to differentiate closely performing systems and does not adequately challenge the models’ reasoning capabilities.
Researchers from the University of Waterloo, the University of Toronto, and Carnegie Mellon University propose a new benchmark/leaderboard, MMLU-Pro, which addresses these limitations by incorporating more challenging, reasoning-intensive tasks and increasing the number of distractor options from three to nine. This benchmark spans 14 diverse domains, encompassing over 12,000 questions, thus providing a broader and more discriminative evaluation. MMLU-Pro also involves a two-round expert review process to reduce dataset noise and enhance question quality. This novel approach significantly raises the benchmark’s difficulty level and robustness, making it better suited for assessing the advanced reasoning capabilities of state-of-the-art LLMs.
MMLU-Pro’s dataset construction involves integrating questions from various high-quality sources, including the original MMLU, STEM websites, TheoremQA, and SciBench, ensuring a diverse and challenging question set. The dataset is filtered and refined through a rigorous process, removing overly simple or erroneous questions and augmenting the question options to ten, which necessitates more discerning reasoning for correct selection. The benchmark also evaluates models’ performance across 24 different prompt styles to assess robustness and minimize prompt variability impacts. Notable technical aspects include leveraging the capabilities of advanced LLMs like GPT-4-Turbo for option augmentation and ensuring consistency and accuracy through expert verification.
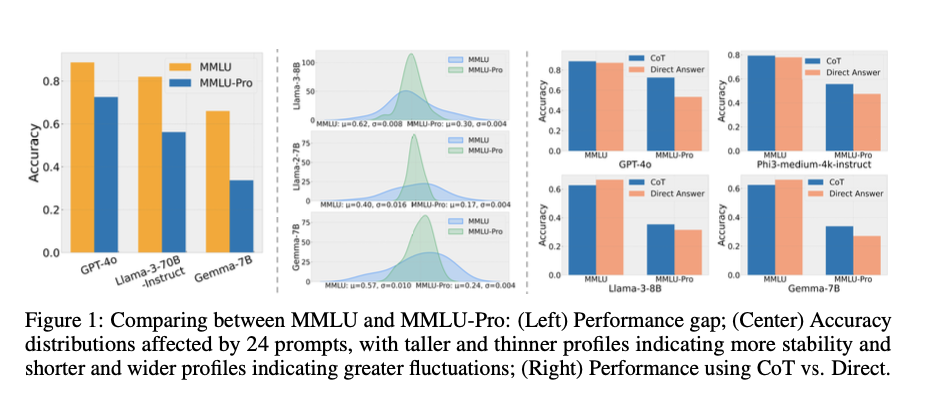
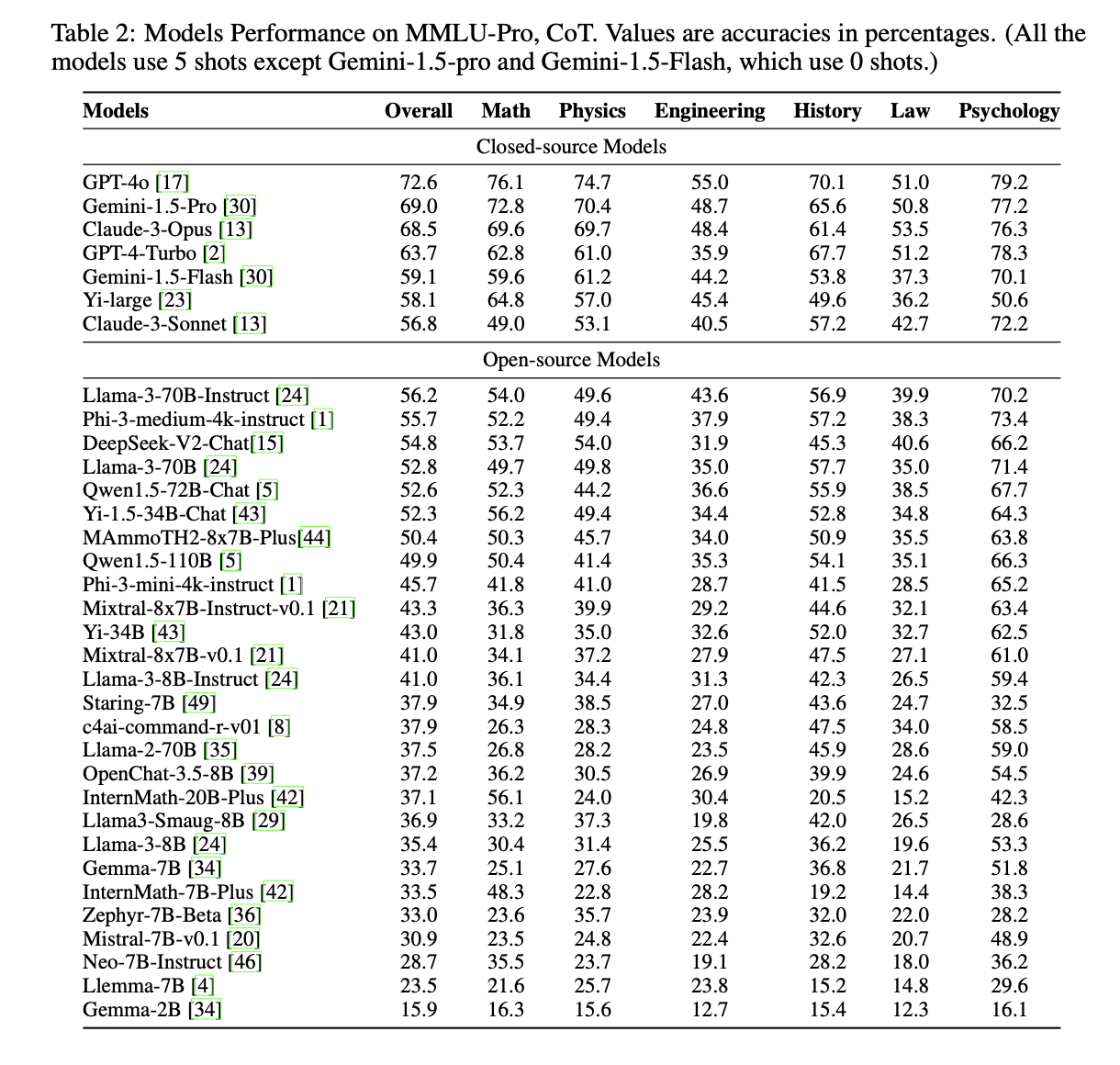
MMLU-Pro presents significant challenges even for the leading models. For instance, GPT-4o, the strongest model tested, achieved an overall accuracy of 72.6%, while other top-tier models like GPT-4-Turbo reached 63.7%. These results indicate substantial room for improvement, highlighting the benchmark’s effectiveness in differentiating models’ reasoning capabilities. The benchmark’s robustness is evidenced by reduced variability in model scores under different prompts, with a maximum impact of 3.74% compared to up to 10.98% on the original MMLU. This stability enhances the reliability of evaluations and the benchmark’s utility in advancing AI language understanding capabilities.
In Conclusion, MMLU-Pro represents a significant advancement in benchmarking LLMs by addressing the limitations of existing methods and enhancing the assessment of multi-task language understanding and reasoning capabilities. The benchmark introduces more complex, reasoning-intensive tasks and increases the number of distractor options, significantly improving its robustness and discriminative power. The evaluations show that even top-performing models face substantial challenges on MMLU-Pro, indicating its effectiveness in pushing the boundaries of AI capabilities. This benchmark is poised to play a crucial role in the future development and evaluation of LLMs, driving advancements in AI research by overcoming critical challenges in model evaluation.
Check out the Paper and Leaderboard. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 43k+ ML SubReddit | Also, check out our AI Events Platform
Aswin AK is a consulting intern at MarkTechPost. He is pursuing his Dual Degree at the Indian Institute of Technology, Kharagpur. He is passionate about data science and machine learning, bringing a strong academic background and hands-on experience in solving real-life cross-domain challenges.
