Multimodal generative models represent an exciting frontier in artificial intelligence, focusing on integrating visual and textual data to create systems capable of various tasks. These tasks range from generating highly detailed images from textual descriptions to understanding and reasoning across different data types. The advancements in this field are opening new possibilities for more interactive and intelligent AI systems that can seamlessly combine vision and language.
One of the critical challenges in this domain is the development of autoregressive (AR) models that can generate photorealistic images from text descriptions. While diffusion models have made significant strides in this area, AR models have historically lagged, particularly regarding image quality, resolution flexibility, and the ability to handle various visual tasks. This gap has driven the need for innovative approaches to enhance AR models’ capabilities.
The current landscape of text-to-image generation is dominated by diffusion models, which excel at creating high-quality, visually appealing images. However, AR models like LlamaGen and Parti need help matching this level of performance. These models often rely on complex encoder-decoder architectures and are typically limited to generating images at fixed resolutions. This restricts their flexibility and overall effectiveness in producing diverse, high-resolution outputs.
Researchers from the Shanghai AI Laboratory and the Chinese University of Hong Kong introduced Lumina-mGPT, an advanced AR model designed to overcome these limitations. Lumina-mGPT is based on a decoder-only transformer architecture with multimodal Generative PreTraining (mGPT). This model uniquely combines vision-language tasks within a unified framework, aiming to achieve the same level of photorealistic image generation as diffusion models while maintaining the simplicity and scalability of AR methods.
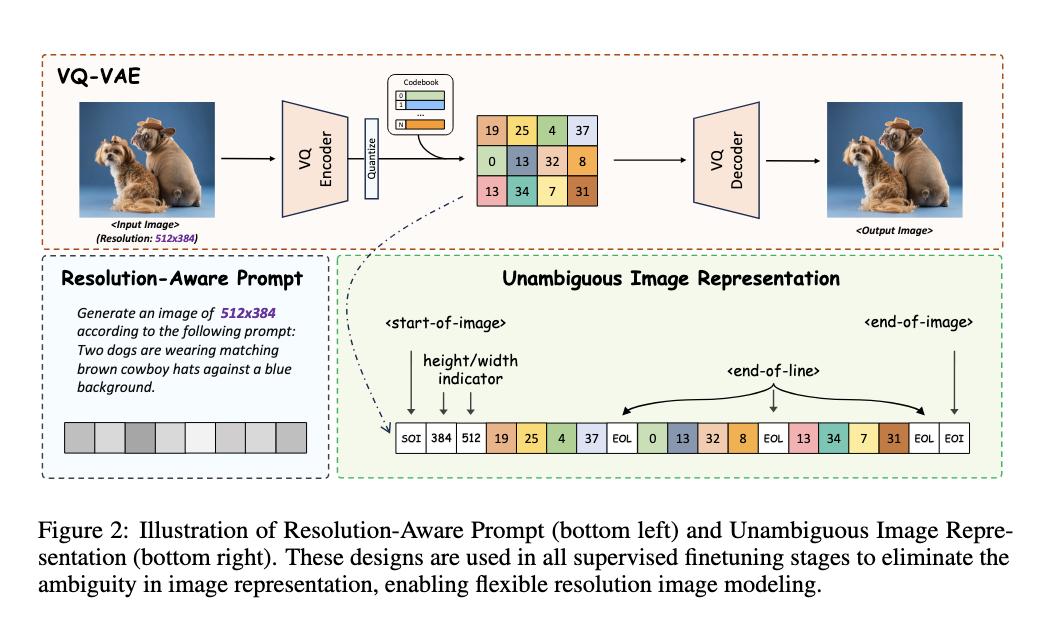
The Lumina-mGPT model employs a detailed approach to enhance its image generation capabilities. The Flexible Progressive Supervised Finetuning (FP-SFT) strategy is at its core, which progressively trains the model from low-resolution to high-resolution image generation. This process begins with learning general visual concepts at lower resolutions and incrementally introduces more complex, high-resolution details. The model also features an innovative, unambiguous image representation system, eliminating the ambiguity often associated with variable image resolutions and aspect ratios by introducing specific height and width indicators and end-of-line tokens.
In terms of performance, Lumina-mGPT has demonstrated a significant improvement in generating photorealistic images compared to previous AR models. It can produce high-resolution images of 1024×1024 pixels with intricate visual details that closely align with the text prompts provided. The researchers reported that Lumina-mGPT requires only 10 million image-text pairs for training, a significantly smaller dataset than that used by competing models like LlamaGen, which requires 50 million pairs. Despite the smaller dataset, Lumina-mGPT outperforms its AR counterparts in terms of image quality and visual coherence. Furthermore, the model supports a wide range of tasks, including visual question answering, dense labeling, and controllable image generation, showcasing its versatility as a multimodal generalist.

Its flexible and scalable architecture further enhances lumina-mGPT’s ability to generate diverse, high-quality images. The model’s use of advanced decoding techniques, such as Classifier-Free Guidance (CFG), plays a crucial role in refining the quality of the generated images. For instance, by adjusting parameters like temperature and top-k values, Lumina-mGPT can control the level of detail and diversity in the photos it produces, which helps reduce visual artifacts and enhances the overall aesthetic appeal.
In conclusion, Lumina-mGPT represents a significant advancement in autoregressive image generation. Developed by researchers at the Shanghai AI Laboratory and the Chinese University of Hong Kong, this model bridges the gap between AR and diffusion models, offering a powerful new tool for generating photorealistic images from text. Its innovative approach to multimodal pretraining and flexible finetuning demonstrates the potential to transform the capabilities of AR models, making them a viable option for a wide range of vision-language tasks. This breakthrough suggests a promising future for AR-based generative models, potentially leading to more sophisticated and versatile AI systems.
Check out the Paper and GitHub. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 48k+ ML SubReddit
Find Upcoming AI Webinars here
Nikhil is an intern consultant at Marktechpost. He is pursuing an integrated dual degree in Materials at the Indian Institute of Technology, Kharagpur. Nikhil is an AI/ML enthusiast who is always researching applications in fields like biomaterials and biomedical science. With a strong background in Material Science, he is exploring new advancements and creating opportunities to contribute.
