Financial data analysis plays a critical role in the decision-making processes of analysts and investors. The ability to extract relevant insights from unstructured text, such as earnings call transcripts and financial reports, is essential for making informed decisions that can impact market predictions and investment strategies. However, this task is complicated by the specialized language and varied formats within these documents, posing significant challenges to traditional data extraction methods.
The complexity of financial documents lies in their use of domain-specific terminology and intricate formats that are not easily interpreted by general-purpose data analysis tools. Traditional approaches often fail to capture the nuanced information embedded in these documents, leading to potential inaccuracies in analysis. This problem is exacerbated by the volume of data that financial analysts must process, which can result in overlooked insights and unreliable analyses.
To address these challenges, existing methods, such as Retrieval-Augmented Generation (RAG) techniques, have enhanced the capabilities of large language models (LLMs) in processing and understanding financial text. VectorRAG, a commonly used RAG method, retrieves relevant textual information from vector databases to support the generation of accurate and contextually appropriate responses. However, despite its advantages, VectorRAG needs help with the hierarchical nature of financial documents, often leading to the loss of critical contextual information necessary for precise analysis.
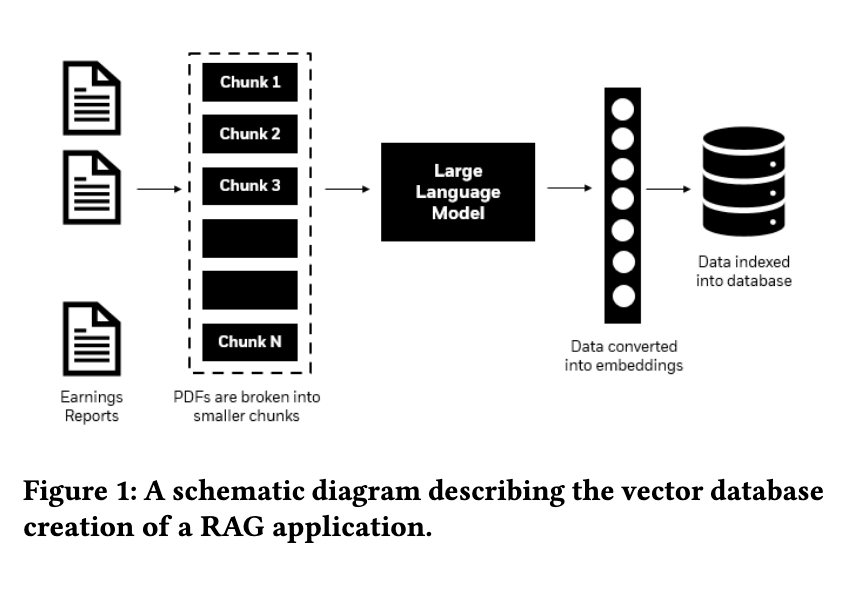
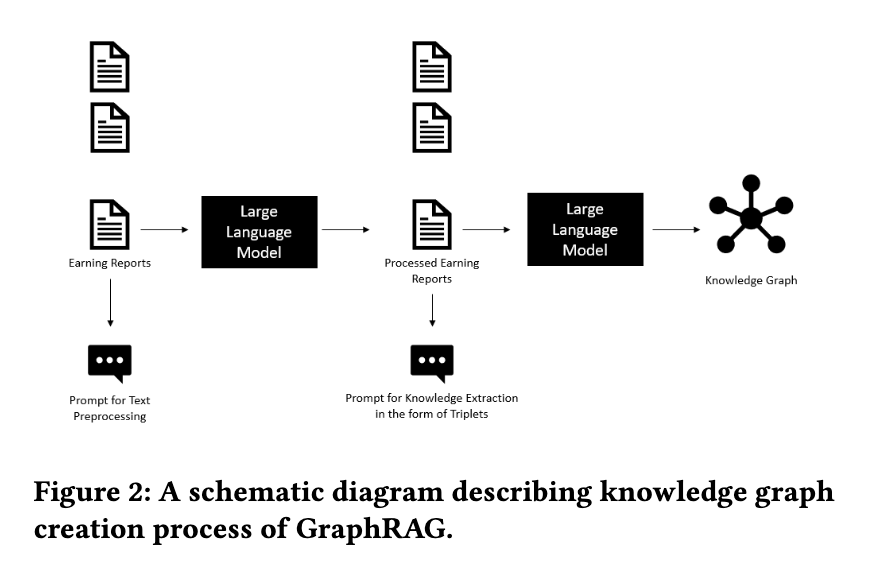
Researchers from BlackRock, Inc., and NVIDIA introduced a novel approach known as HybridRAG. This method integrates the strengths of both VectorRAG and Knowledge Graph-based RAG (GraphRAG) to create a more robust system for extracting information from financial documents. By combining these two techniques, HybridRAG aims to improve the accuracy of information retrieval and generate relevant responses, thereby enhancing the overall quality of financial analysis.
HybridRAG operates through a sophisticated two-tiered approach. Initially, VectorRAG retrieves context based on textual similarity, which involves dividing documents into smaller chunks and converting them into vector embeddings stored in a vector database. The system then performs a similarity search within this database to identify and rank the most relevant chunks. Simultaneously, GraphRAG uses Knowledge Graphs to extract structured information, representing entities and their relationships within the financial documents. By merging these two contexts, HybridRAG ensures that the language model generates contextually accurate responses and rich in detail.
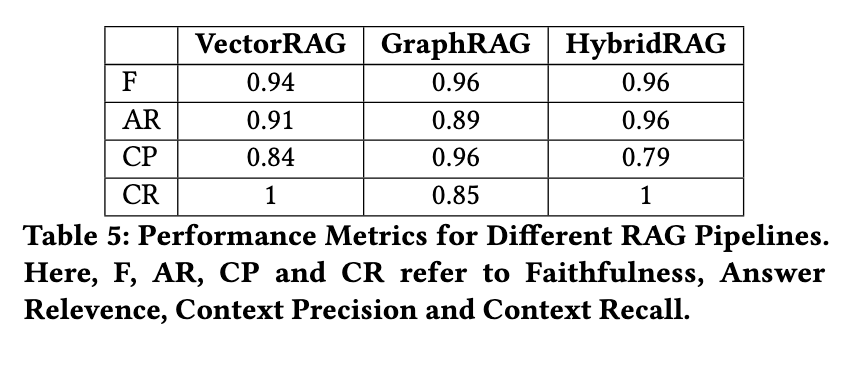
The effectiveness of HybridRAG was demonstrated through extensive experimentation using a dataset of earnings call transcripts from companies listed in the Nifty 50 index. This dataset, covering various sectors such as infrastructure, healthcare, and financial services, provided a diverse foundation for evaluating the system’s performance. The researchers compared HybridRAG, VectorRAG, and GraphRAG, focusing on key metrics such as faithfulness, answer relevance, context precision, and context recall.

The results of this analysis revealed that HybridRAG outperformed both VectorRAG and GraphRAG across several metrics. HybridRAG achieved a faithfulness score of 0.96, indicating that the generated answers aligned with the provided context. Regarding answer relevance, HybridRAG scored 0.96, outperforming VectorRAG (0.91) and GraphRAG (0.89). While GraphRAG excelled in context precision with a score of 0.96, HybridRAG maintained a strong performance in context recall, achieving a perfect score of 1.0 alongside VectorRAG. These results underscore the advantages of HybridRAG in providing accurate, contextually relevant responses while balancing the strengths of both vector-based and graph-based retrieval methods.
The HybridRAG system represents a significant advancement in financial data analysis. By leveraging the combined capabilities of VectorRAG and GraphRAG, the researchers from BlackRock, Inc. and NVIDIA have developed a tool that addresses the inherent challenges of extracting and interpreting complex financial information. This hybrid approach enhances the accuracy and reliability of financial analyses and paves the way for more sophisticated AI-driven tools in the financial sector.
In conclusion, the development of HybridRAG marks a pivotal step forward in extracting and analyzing financial documents. By integrating the strengths of vector-based and graph-based retrieval methods, HybridRAG offers a more comprehensive and accurate approach to financial data analysis, providing valuable insights that can inform better investment strategies and market predictions. The success of this system highlights the potential for future innovations in AI-driven financial analysis, setting the stage for more advanced tools that can handle the complexities of financial data with greater precision and reliability.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 48k+ ML SubReddit
Find Upcoming AI Webinars here
Nikhil is an intern consultant at Marktechpost. He is pursuing an integrated dual degree in Materials at the Indian Institute of Technology, Kharagpur. Nikhil is an AI/ML enthusiast who is always researching applications in fields like biomaterials and biomedical science. With a strong background in Material Science, he is exploring new advancements and creating opportunities to contribute.
