Retrieval-Augmented Generation (RAG) is a cutting-edge approach in natural language processing (NLP) that significantly enhances the capabilities of Large Language Models (LLMs) by incorporating external knowledge bases. This method is particularly effective in domains where precision and reliability are critical, such as legal, medical, and financial. By leveraging external information, RAG systems can generate more accurate and contextually relevant responses, addressing common challenges in LLMs, such as outdated information and the tendency to produce hallucinations—responses that appear plausible but are factually incorrect. As RAG systems become integral to various applications, the need for robust evaluation frameworks that can accurately assess their performance has become increasingly important.
Despite the promising potential of RAG systems, evaluating their performance poses significant challenges. The primary issue stems from these systems’ modular nature, consisting of a retriever and a generator working in tandem. Existing evaluation metrics often need more granularity to capture the intricacies of this interaction. Traditional metrics, such as recall@k and MRR for retrievers and BLEU and ROUGE for generators, are typically rule-based or coarse-grained, making them ill-suited for evaluating the quality of long-form responses generated by RAG systems. This limitation results in assessments that are not only inaccurate but also difficult to interpret, thereby hindering the development of more effective RAG systems.
Current methods for evaluating RAG systems are generally divided into two categories: those that assess the capabilities of the generator alone and those that consider the system’s overall performance. For instance, RGB evaluates four fundamental abilities required for generators, including noise robustness and information integration, while RECALL focuses on counterfactual robustness by introducing manually edited contexts into datasets. However, these approaches often fail to account for the interplay between the retriever and generator components. This is crucial for understanding the sources of errors and how they affect the system’s output. As a result, these methods provide an incomplete picture of the system’s performance, particularly in complex RAG scenarios requiring long, coherent responses.
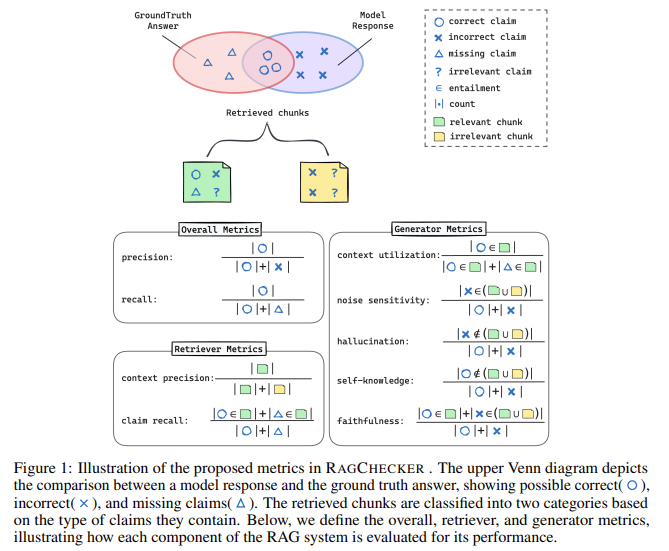
Researchers from Amazon AWS AI, Shanghai Jiaotong University, and Westlake University have introduced RAGChecker, a novel evaluation framework designed to analyze RAG systems comprehensively. RAGChecker incorporates a suite of diagnostic metrics that evaluate the retrieval and generation processes at a fine-grained level. The framework is based on claim-level entailment checking, which involves decomposing the system’s output into individual claims and verifying each claim’s validity against the retrieved context and the ground truth. This approach allows for assessing the system’s performance, enabling researchers to identify specific areas for improvement. RAGChecker’s metrics are designed to offer actionable insights, guiding the development of more effective RAG systems by pinpointing the sources of errors and providing recommendations for addressing them.
RAGChecker processes user queries, retrieved context, model responses, and ground truth answers, producing a comprehensive set of metrics that assess the quality of the generated responses, the retriever’s effectiveness, and the generator’s accuracy. For example, RAGChecker evaluates the proportion of correct claims in the model’s response, the retriever’s ability to return relevant information, and the generator’s sensitivity to noise. The framework also measures the generator’s faithfulness to the retrieved context and its tendency to hallucinate, providing a view of the system’s performance. Compared to existing frameworks, RAGChecker offers a more nuanced evaluation.
The effectiveness of RAGChecker was demonstrated through extensive experiments that evaluated eight state-of-the-art RAG systems across ten domains, using a benchmark repurposed from public datasets. The results revealed that RAGChecker’s metrics correlate significantly better with human judgments than other evaluation frameworks, such as RAGAS, TruLens, and ARES. For instance, in a meta-evaluation involving 280 instances labeled by human annotators, RAGChecker showed the strongest correlation with human preference in terms of correctness, completeness, and overall assessment, outperforming traditional metrics like BLEU, ROUGE, and BERTScore. This validation highlights RAGChecker’s ability to capture the quality and reliability of RAG systems from a human perspective, making it a robust tool for guiding the development of more effective RAG systems.
RAGChecker’s comprehensive analysis of RAG systems yielded several key insights. For example, the framework revealed that the retriever’s quality significantly impacts the system’s overall performance, as evidenced by notable differences in precision, recall, and F1 scores between different retrievers. The framework showed that larger generator models, such as Llama3-70B, consistently outperform smaller models regarding context utilization, noise sensitivity, and hallucination rates. These underscore optimizing the retriever and generator components for better performance. Moreover, RAGChecker identified that improving the retriever’s ability to return relevant information can enhance the generator’s faithfulness to the context while reducing the likelihood of hallucinations.

In conclusion, RAGChecker represents a significant advancement in evaluating Retrieval-Augmented Generation systems. Offering a more detailed and reliable assessment of the retriever and generator components, it provides critical guidance for developing more effective RAG systems. The insights gained from RAGChecker’s evaluations, such as the importance of retriever quality and generator size, are expected to drive future improvements in the design and application of these systems. RAGChecker not only deepens the understanding of RAG architectures but also offers practical recommendations for enhancing the performance and reliability of these systems.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 48k+ ML SubReddit
Find Upcoming AI Webinars here
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is committed to harnessing the potential of Artificial Intelligence for social good. His most recent endeavor is the launch of an Artificial Intelligence Media Platform, Marktechpost, which stands out for its in-depth coverage of machine learning and deep learning news that is both technically sound and easily understandable by a wide audience. The platform boasts of over 2 million monthly views, illustrating its popularity among audiences.

