Large language models (LLMs) are widely implemented in sociotechnical systems like healthcare and education. However, these models often encode societal norms from the data used during training, raising concerns about how well they align with expectations of privacy and ethical behavior. The central challenge is ensuring that these models adhere to societal norms across varying contexts, model architectures, and datasets. Additionally, prompt sensitivity—where small changes in input prompts lead to different responses—complicates assessing whether LLMs reliably encode these norms. Addressing this challenge is critical to preventing ethical issues such as unintended privacy violations in sensitive domains.
Traditional methods for evaluating LLMs focus on technical capabilities like fluency and accuracy, neglecting the encoding of societal norms. Some approaches attempt to assess privacy norms using specific prompts or datasets, but these often fail to account for prompt sensitivity, leading to unreliable outcomes. Additionally, variations in model hyperparameters and optimization strategies—such as capacity, alignment, and quantization—are seldom considered, which results in incomplete evaluations of LLM behavior. These limitations leave a gap in assessing the ethical alignment of LLMs with societal norms.
A team of researchers from York University and the University of Waterloo introduces LLM-CI, a novel framework grounded in Contextual Integrity (CI) theory, to assess how LLMs encode privacy norms across different contexts. It employs a multi-prompt assessment strategy to mitigate prompt sensitivity, selecting prompts that yield consistent outputs across various variants. This provides a more accurate evaluation of norm adherence across models and datasets. The approach also incorporates real-world vignettes that represent privacy-sensitive situations, ensuring a thorough evaluation of model behavior in diverse scenarios. This method is a significant advancement in evaluating the ethical performance of LLMs, particularly in terms of privacy and societal norms.

LLM-CI was tested on datasets such as IoT vignettes and COPPA vignettes, which simulate real-world privacy scenarios. These datasets were used to assess how models handle contextual factors like user roles and information types in various privacy-sensitive contexts. The evaluation also examined the influence of hyperparameters (e.g., model capacity) and optimization techniques (e.g., alignment and quantization) on norm adherence. The multi-prompt methodology ensured that only consistent outputs were considered in the evaluation, minimizing the effect of prompt sensitivity and improving the robustness of the analysis.
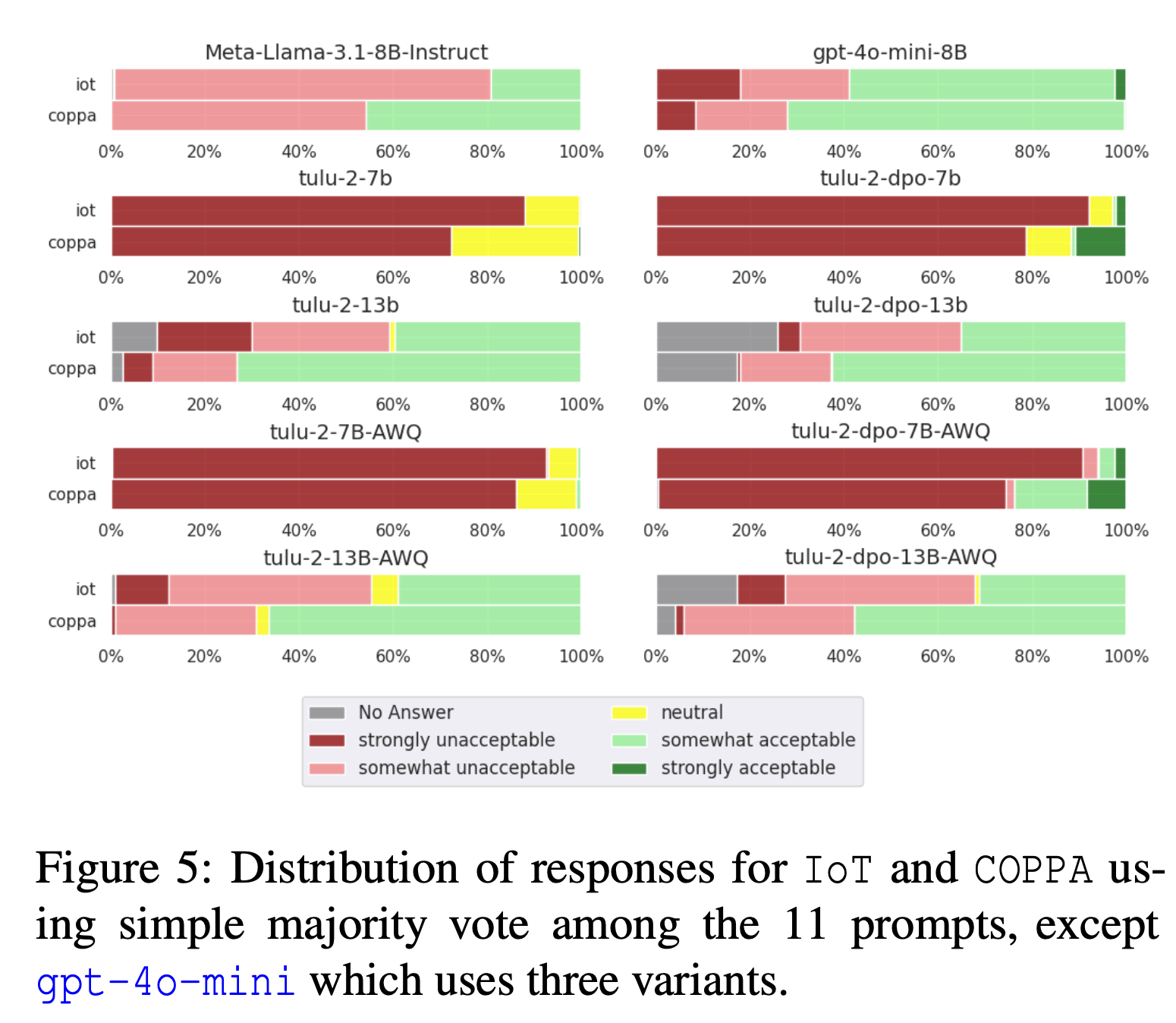
The LLM-CI framework demonstrated a marked improvement in evaluating how LLMs encode privacy norms across varying contexts. By applying the multi-prompt assessment strategy, more consistent and reliable results were achieved than with single-prompt methods. Models optimized using alignment techniques showed up to 92% contextual accuracy in adhering to privacy norms. Furthermore, the new assessment approach resulted in a 15% increase in response consistency, confirming that tuning model properties such as capacity and applying alignment strategies significantly improved LLMs’ ability to align with societal expectations. This validated the robustness of LLM-CI in norm adherence evaluations.
LLM-CI offers a comprehensive and robust approach for assessing how LLMs encode privacy norms by leveraging a multi-prompt assessment methodology. It provides a reliable evaluation of model behavior across different datasets and contexts, addressing the challenge of prompt sensitivity. This method significantly advances the understanding of how well LLMs align with societal norms, particularly in sensitive areas such as privacy. By improving the accuracy and consistency of model responses, LLM-CI represents a vital step toward the ethical deployment of LLMs in real-world applications.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 50k+ ML SubReddit
Aswin AK is a consulting intern at MarkTechPost. He is pursuing his Dual Degree at the Indian Institute of Technology, Kharagpur. He is passionate about data science and machine learning, bringing a strong academic background and hands-on experience in solving real-life cross-domain challenges.
