A significant challenge in text-to-speech (TTS) systems is the computational inefficiency of the Monotonic Alignment Search (MAS) algorithm, which is responsible for estimating alignments between text and speech sequences. MAS faces high time complexity, particularly when dealing with large inputs. The complexity is O(T×S), where T is the text length and S is the speech representation length. As the input size increases, the computational burden becomes unmanageable, especially when the algorithm is executed sequentially without leveraging parallel processing. This inefficiency hinders its applicability in real-time and large-scale applications in TTS models. Therefore, addressing this issue is crucial for improving the scalability and performance of TTS systems, enabling faster training and inference across various AI tasks requiring sequence alignment.
Current methods of implementing MAS are CPU-based and utilize Cython to parallelize the batch dimension. However, these methods employ nested loops for alignment calculations, which significantly increase the computational burden for larger datasets. Moreover, the need for inter-device memory transfers between the CPU and GPU introduces additional delays, making these methods inefficient for large-scale or real-time applications. Furthermore, the max_neg_val used in the traditional methods is set to -1e9, which is insufficient for preventing alignment mismatches, particularly in the upper diagonal regions of the alignment matrix. The inability to fully exploit GPU parallelization is another major limitation, as current methods remain bound by the processing constraints of CPUs, resulting in slower execution times as the input size grows.
A team of researchers from Johns Hopkins University and Supertone Inc. propose Super-MAS, a novel solution that leverages Triton kernels and PyTorch JIT scripts to optimize MAS for GPU execution, eliminating nested loops and inter-device memory transfers. By parallelizing the text-length dimension, this approach significantly reduces the computational complexity. The introduction of a larger max_neg_val (-1e32) mitigates alignment mismatches, improving overall accuracy. Additionally, the in-place computation of log-likelihood values minimizes memory allocation, further streamlining the process. These improvements make the algorithm much more efficient and scalable, particularly for real-time TTS applications or other AI tasks requiring large-scale sequence alignment.
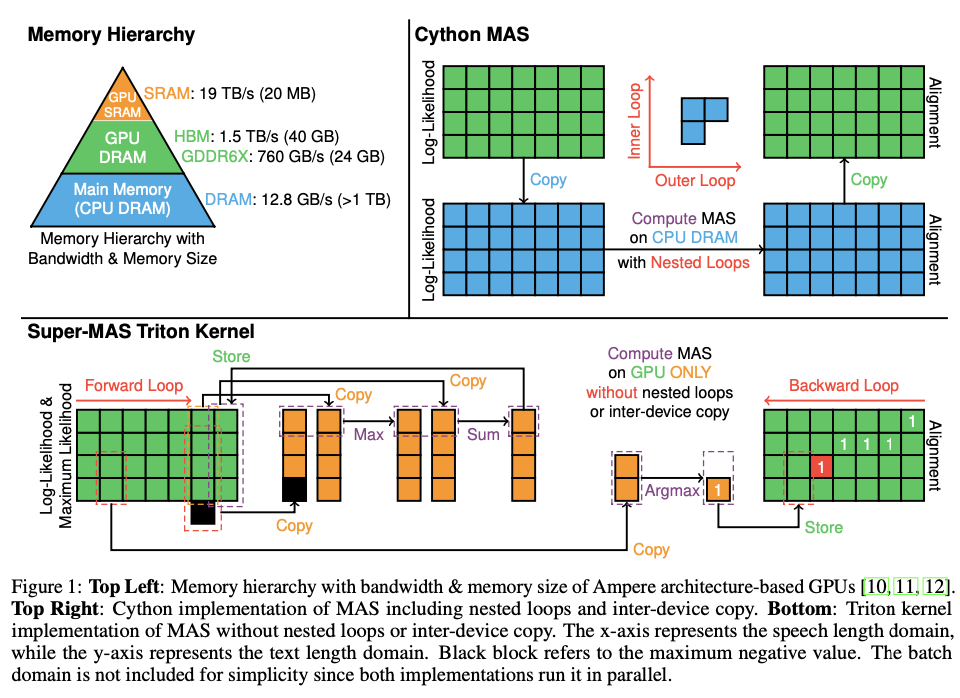
Super-MAS is implemented by vectorizing the text-length dimension using Triton kernels, unlike traditional methods that parallelize the batch dimensions with Cython. This restructuring eliminates the nested loops that previously slowed down computation. The log-likelihood matrix is initialized, and alignments are calculated using dynamic programming, with forward and backward loops iterating over the matrix to compute and reconstruct the alignment paths. The entire process is executed on the GPU, avoiding the inefficiencies caused by inter-device transfers between the CPU and GPU. A series of tests were conducted using log-likelihood tensors with a batch size of B=32, text length T, and speech length S=4T.
Super-MAS achieves remarkable improvements in execution speed, with the Triton kernel performing 19 to 72 times faster than the Cython implementation, depending on the input size. For instance, with a text length of 1024, Super-MAS completes its task in 19.77 milliseconds, compared to 1299.56 milliseconds for Cython. These speedups are especially pronounced as input size increases, confirming that Super-MAS is highly scalable and significantly more efficient for handling large datasets. It also outperforms PyTorch JIT versions, particularly for larger inputs, making it an ideal choice for real-time applications in TTS systems or other tasks requiring efficient sequence alignment.
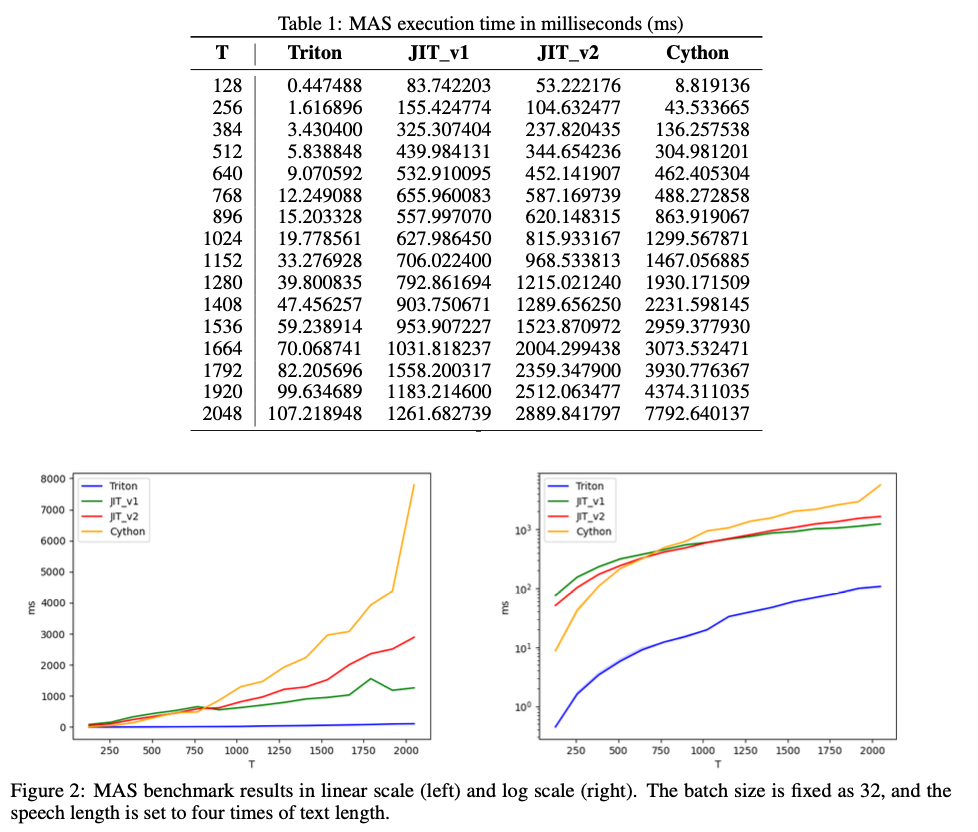
In conclusion, Super-MAS presents an advanced solution to the computational challenges of Monotonic Alignment Search in TTS systems, achieving substantial reductions in time complexity through GPU parallelization and memory optimization. By eliminating the need for nested loops and inter-device transfers, it delivers a highly efficient and scalable method for sequence alignment tasks, offering speedups of up to 72 times compared to existing approaches. This breakthrough enables faster and more accurate processing, making it invaluable for real-time AI applications like TTS and beyond.
Check out the Paper and GitHub. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 50k+ ML SubReddit
Aswin AK is a consulting intern at MarkTechPost. He is pursuing his Dual Degree at the Indian Institute of Technology, Kharagpur. He is passionate about data science and machine learning, bringing a strong academic background and hands-on experience in solving real-life cross-domain challenges.
