Collaborative perception has become a critical area of research in autonomous driving and robotics. In these fields, agents—such as vehicles or robots—must work together to understand their environment more accurately and efficiently. By sharing sensory data among multiple agents, the accuracy and depth of environmental perception are enhanced, leading to safer and more reliable systems. This is especially important in dynamic environments where real-time decision-making prevents accidents and ensures smooth operation. The ability to perceive complex scenes is essential for autonomous systems to navigate safely, avoid obstacles, and make informed decisions.
One of the key challenges in multi-agent perception is the need to manage vast amounts of data while maintaining efficient resource use. Traditional methods must help balance the demand for accurate, long-range spatial and temporal perception with minimizing computational and communication overhead. Existing approaches often fall short when dealing with long-range spatial dependencies or extended timeframes, which are critical for making accurate predictions in real-world environments. This creates a bottleneck in improving the overall performance of autonomous systems, where the ability to model interactions between agents over time is vital.
Many multi-agent perception systems currently use methods based on CNNs or transformers to process and fuse data across agents. CNNs can capture local spatial information effectively, but they often struggle with long-range dependencies, limiting their ability to model the full scope of an agent’s environment. On the other hand, transformer-based models, while more capable of handling long-range dependencies, require significant computational power, making them less feasible for real-time use. Existing models, such as V2X-ViT and distillation-based models, have attempted to address these issues, but they still face limitations in achieving high performance and resource efficiency. These challenges call for more efficient models that balance accuracy with practical constraints on computational resources.
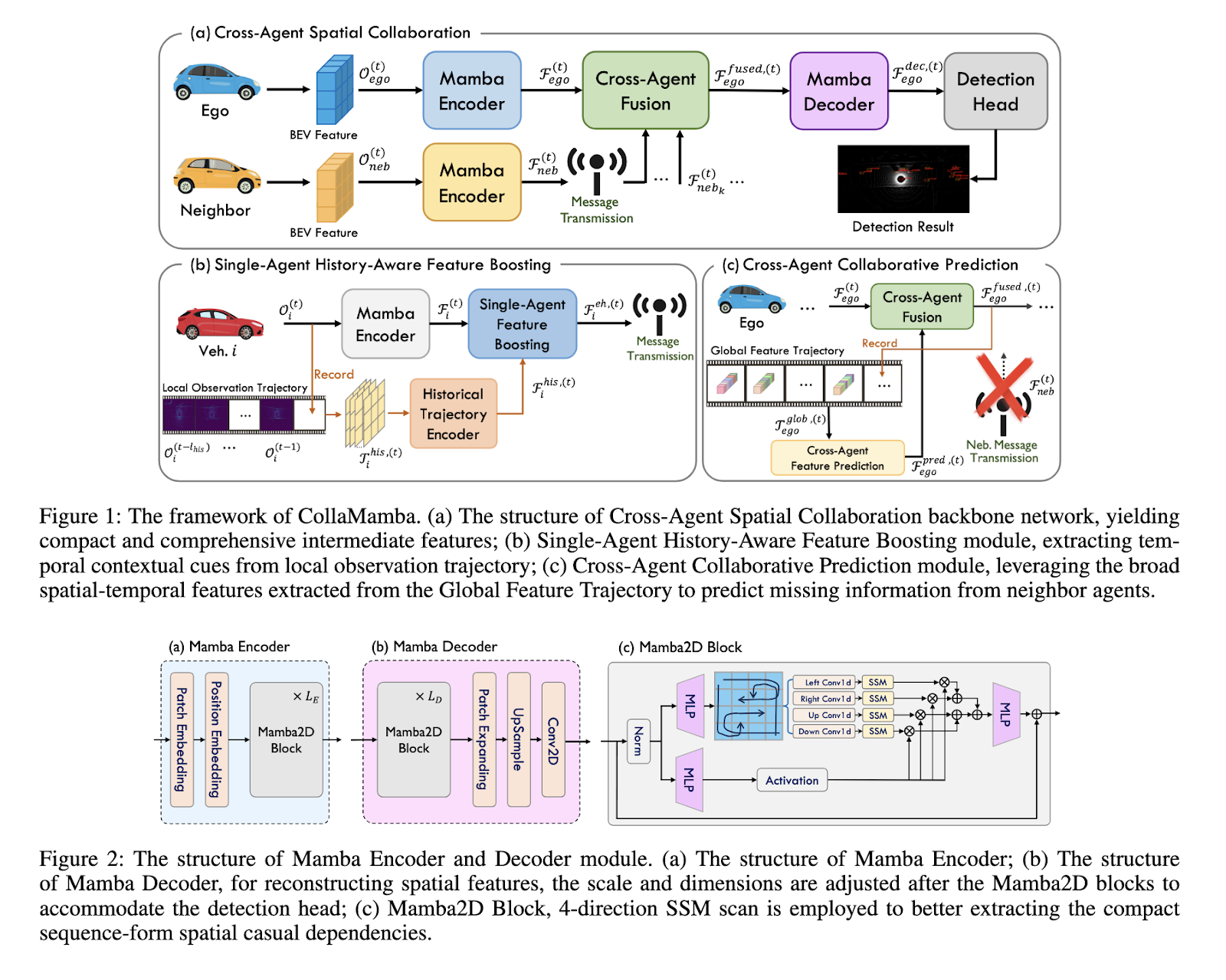
Researchers from the State Key Laboratory of Networking and Switching Technology at Beijing University of Posts and Telecommunications introduced a new framework called CollaMamba. This model utilizes a spatial-temporal state space (SSM) to process cross-agent collaborative perception efficiently. By integrating Mamba-based encoder and decoder modules, CollaMamba provides a resource-efficient solution that effectively models spatial and temporal dependencies across agents. The innovative approach reduces computational complexity to a linear scale, significantly improving communication efficiency between agents. This new model enables agents to share more compact, comprehensive feature representations, allowing for better perception without overwhelming computational and communication systems.
The methodology behind CollaMamba is built around enhancing both spatial and temporal feature extraction. The backbone of the model is designed to capture causal dependencies from both single-agent and cross-agent perspectives efficiently. This allows the system to process complex spatial relationships over long distances while reducing resource use. The history-aware feature boosting module also plays a critical role in refining ambiguous features by leveraging extended temporal frames. This module allows the system to incorporate data from previous moments, helping to clarify and enhance current features. The cross-agent fusion module enables effective collaboration by allowing each agent to integrate features shared by neighboring agents, further boosting the accuracy of the global scene understanding.
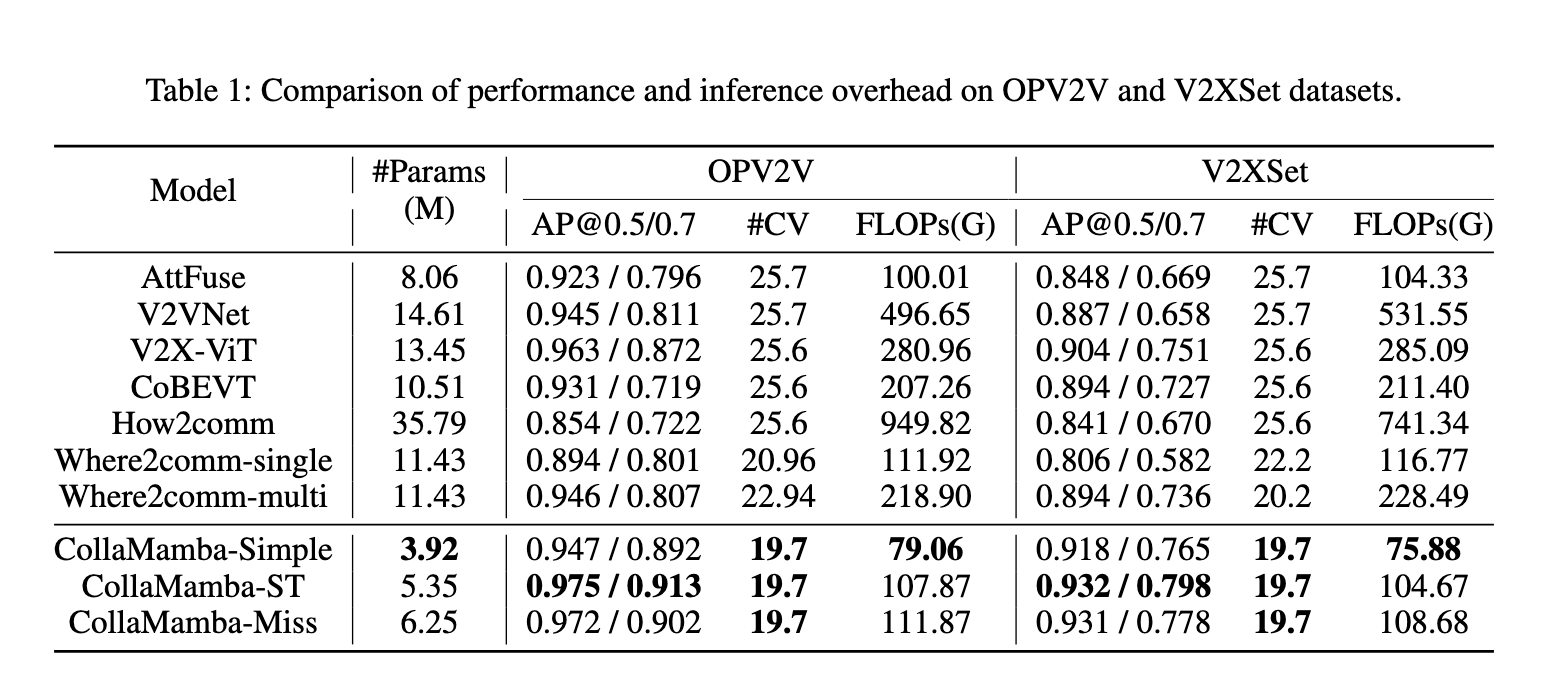
Regarding performance, the CollaMamba model demonstrates substantial improvements over state-of-the-art methods. The model consistently outperformed existing solutions through extensive experiments across various datasets, including OPV2V, V2XSet, and V2V4Real. One of the most substantial results is the significant reduction in resource demands: CollaMamba reduced computational overhead by up to 71.9% and decreased communication overhead by 1/64. These reductions are particularly impressive given that the model also increased the overall accuracy of multi-agent perception tasks. For example, CollaMamba-ST, which incorporates the history-aware feature boosting module, achieved a 4.1% improvement in average precision at a 0.7 intersection over the union (IoU) threshold on the OPV2V dataset. Meanwhile, the simpler version of the model, CollaMamba-Simple, showed a 70.9% reduction in model parameters and a 71.9% reduction in FLOPs, making it highly efficient for real-time applications.
Further analysis reveals that CollaMamba excels in environments where communication between agents is inconsistent. The CollaMamba-Miss version of the model is designed to predict missing data from neighboring agents using historical spatial-temporal trajectories. This ability allows the model to maintain high performance even when some agents fail to transmit data promptly. Experiments showed that CollaMamba-Miss performed robustly, with only minimal drops in accuracy during simulated poor communication conditions. This makes the model highly adaptable to real-world environments where communication issues may arise.
In conclusion, the Beijing University of Posts and Telecommunications researchers have successfully tackled a significant challenge in multi-agent perception by developing the CollaMamba model. This innovative framework improves the accuracy and efficiency of perception tasks while drastically reducing resource overhead. By effectively modeling long-range spatial-temporal dependencies and utilizing historical data to refine features, CollaMamba represents a significant advancement in autonomous systems. The model’s ability to function efficiently, even in poor communication, makes it a practical solution for real-world applications.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 50k+ ML SubReddit
Nikhil is an intern consultant at Marktechpost. He is pursuing an integrated dual degree in Materials at the Indian Institute of Technology, Kharagpur. Nikhil is an AI/ML enthusiast who is always researching applications in fields like biomaterials and biomedical science. With a strong background in Material Science, he is exploring new advancements and creating opportunities to contribute.
