Chain-of-thought (CoT) prompting has emerged as a popular technique to enhance large language models’ (LLMs) problem-solving abilities by generating intermediate steps. Despite its better performance in mathematical reasoning, CoT’s effectiveness in other domains remains questionable. Current research is focused more on mathematical problems, possibly overlooking how CoT could be applied more broadly. In some areas, CoT shows limited improvement or even decreased performance. This narrow focus on mathematical reasoning raises concerns about the generalizability of CoT and highlights the need for a more detailed evaluation of reasoning methods across different problem types.
Existing research includes various approaches to enhance LLMs’ reasoning capabilities beyond CoT. One of the approaches is Long-horizon planning which has emerged as a promising area in tasks like complex decision-making sequences. However, the debate on CoT’s effectiveness in planning tasks remains divided, with studies supporting and questioning its utility. Alternative methods like tree-of-thought have been developed to address planning challenges, resulting in more complex systems. Theoretical research indicates that CoT augments Transformers, opening the door for more advanced CoT variants. Recent work on internalizing CoT also suggests that the full potential of explicit intermediate token generation has yet to be realized.
Researchers from the University of Texas at Austin, Johns Hopkins University, and Princeton University have proposed a comprehensive evaluation of CoT prompting across diverse task domains. It includes a meta-analysis of over 100 CoT-related papers and original evaluations spanning 20 datasets and 14 models. The performance benefits of CoT are more focused on mathematical and logical reasoning tasks, with minimal improvements in other areas. It shows significant advantages on the MMLU benchmark, especially when questions or responses involve symbolic operations. The researchers also break down CoT’s effectiveness by analyzing its planning and execution aspects and comparing it to tool-augmented LLMs.
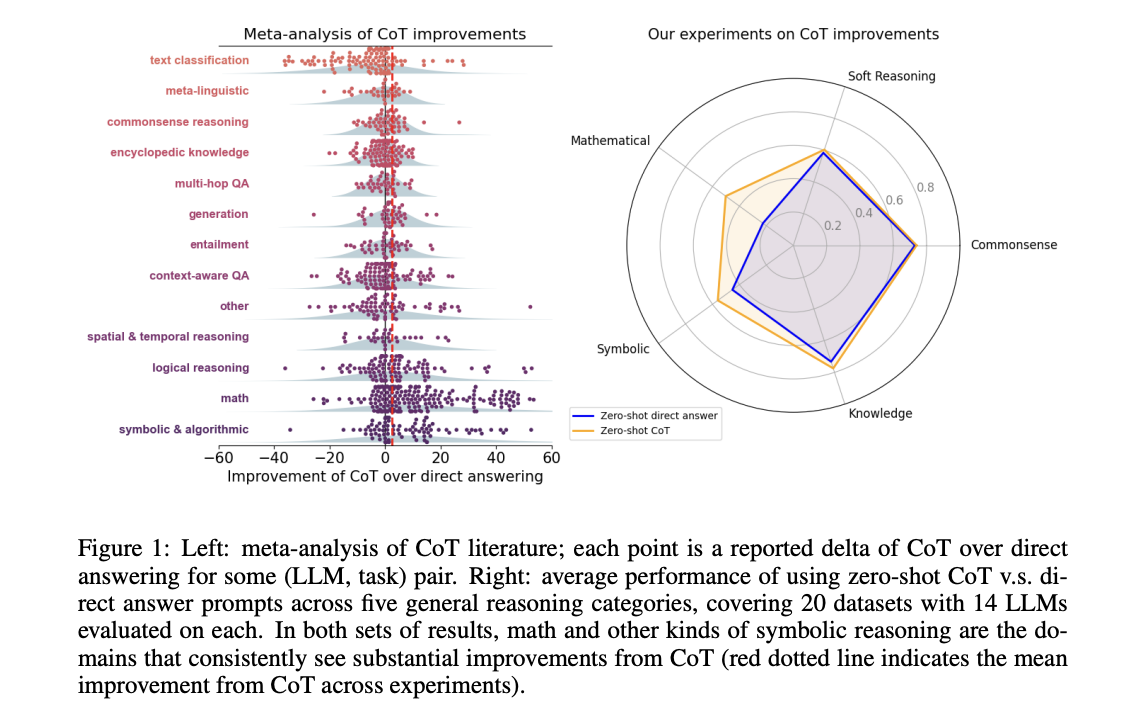
The researchers applied detailed methodology to evaluate CoT across various models, datasets, and prompting techniques. It focuses more on English, instruction-tuned language models commonly used for general reasoning tasks. The selected datasets cover various reasoning categories, like commonsense, knowledge, symbolic, mathematical, and soft reasoning. For implementation, researchers used vLLM, a high-throughput inference package, with greedy decoding applied to all models. Most prompts are derived from Llama 3.1 evaluations, with adjustments made for consistency, and custom answer parsers are created for each dataset and model to ensure accurate result extraction and analysis.
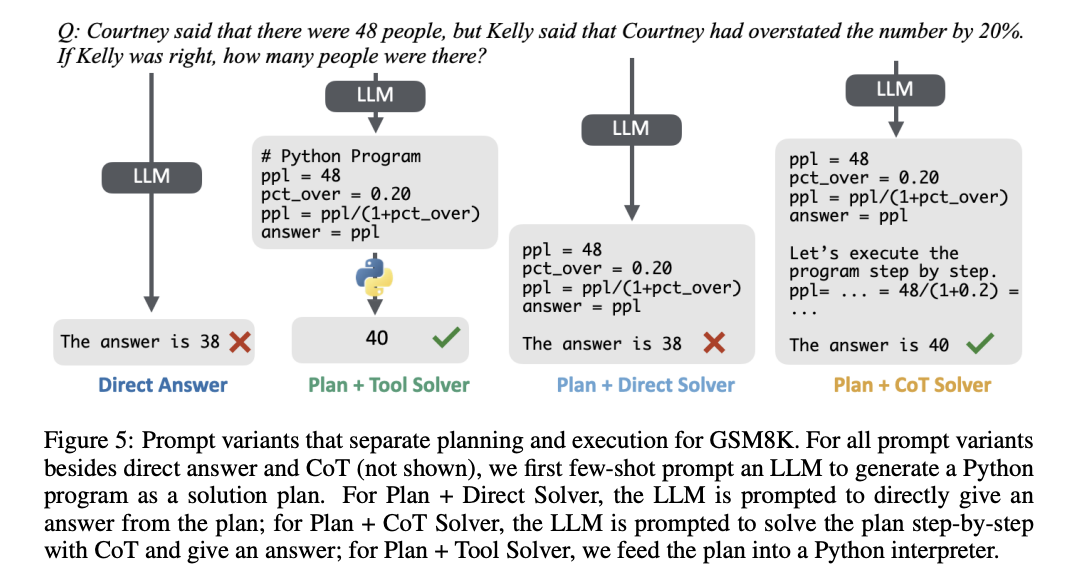
The evaluation results demonstrate significant variations in the effectiveness of CoT across diverse models and datasets. The combination of planning and execution (either through CoT or a direct solver) for tasks like mathematical reasoning, outperforms direct answering. However, the planning alone does not account for most of the performance gains. CoT and Plan + CoT solver methods show the strongest accuracy improvements, especially in math-heavy datasets. Moreover, the Plan + Tool solver method outperforms other methods across most scenarios, highlighting the limitations of LLMs in executing and tracking complex steps compared to specialized symbolic solvers. These findings indicate that CoT’s main advantage lies in its ability, to handle tasks that need detailed tracing and computation.
In this paper, researchers have introduced a comprehensive evaluation of CoT, prompting across diverse task domains. This evaluation of CoT prompting reveals its limited effectiveness across diverse language tasks. The benefits of CoT are more focused on mathematical and formal logic problems, regardless of prompting strategies or model strength. Further analysis shows that CoT’s performance improvements are largely due to its ability to trace intermediate steps in problem-solving. However, dedicated symbolic solvers consistently outperform CoT in these areas. This study highlighted the need for ongoing innovation in language model reasoning capabilities to address the full range of challenges in natural language processing.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 50k+ ML SubReddit

Sajjad Ansari is a final year undergraduate from IIT Kharagpur. As a Tech enthusiast, he delves into the practical applications of AI with a focus on understanding the impact of AI technologies and their real-world implications. He aims to articulate complex AI concepts in a clear and accessible manner.
