The advancement of large language models (LLMs) in natural language processing has significantly improved various domains. As more complex models are developed, evaluating their outputs accurately becomes essential. Traditionally, human evaluations have been the standard approach for assessing quality, but this process is time consuming and needs to be more scalable for the rapid pace of model development.
Salesforce AI Research introduces SFR-Judge, a family of three LLM-based judge models, to revolutionize how LLM outputs are evaluated. Built using Meta Llama 3 and Mistral NeMO, SFR-Judge comes in three sizes: 8 billion (8B), 12 billion (12B), and 70 billion (70B) parameters. Each model is designed to perform multiple evaluation tasks, such as pairwise comparisons, single ratings, and binary classification. These models were developed to support research teams in rapidly and effectively evaluating new LLMs.
One of the main limitations of using traditional LLMs as judges is their susceptibility to biases and inconsistencies. Many judge models, for instance, exhibit position bias, where their judgment is influenced by the order in which responses are presented. Others may show length bias, favoring longer responses that seem more complete even when shorter ones are more accurate. To address these issues, the SFR-Judge models are trained using Direct Preference Optimization (DPO), allowing the model to learn from positive and negative examples. This training methodology enables the model to develop a nuanced understanding of evaluation tasks, reducing biases and ensuring consistent judgments.
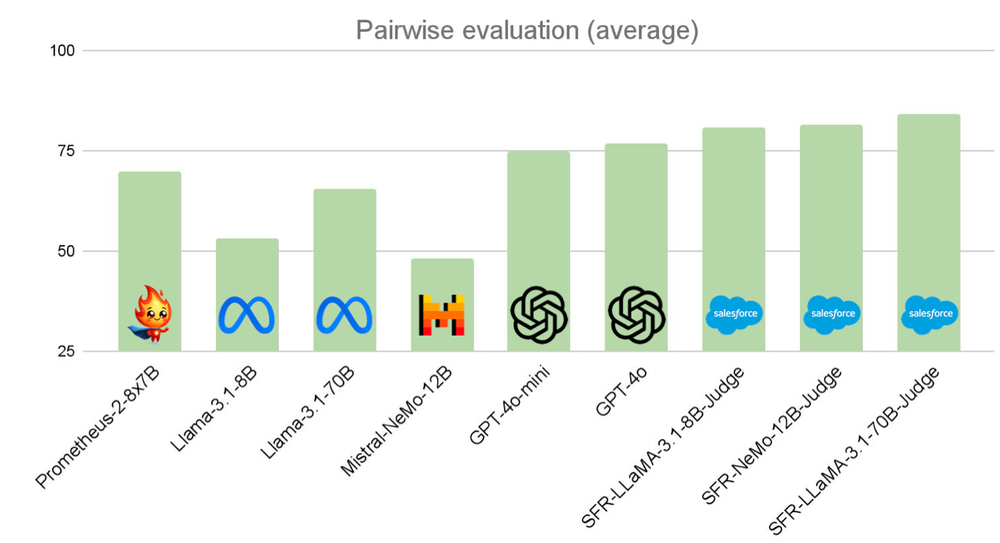
The SFR-Judge models were tested on 13 benchmarks across three evaluation tasks, demonstrating superior performance to existing judge models, including proprietary models like GPT-4o. Notably, SFR-Judge achieved the best performance on 10 of the 13 benchmarks, setting a new standard in LLM-based evaluation. For example, on the RewardBench leaderboard, SFR-Judge attained an accuracy of 92.7%, marking the first and second times any generative judge model crossed the 90% threshold. These results highlight the effectiveness of SFR-Judge not only as an evaluation model but also as a reward model capable of guiding downstream models in reinforcement learning from human feedback (RLHF) scenarios.
SFR-Judge’s training approach involves three distinct data formats. The first, the Chain-of-Thought Critique, helps the model generate structured and detailed analyses of the evaluated responses. This critique enhances the model’s ability to reason about complex inputs and produce informed judgments. The second format, Standard Judgment, simplifies evaluations by removing the critique providing more direct feedback on whether the responses meet the specified criteria. Finally, Response Deduction enables the model to deduce what a high-quality reaction looks like, reinforcing its judgment capabilities. These three data formats work in conjunction to strengthen the model’s capacity to produce well-rounded and accurate evaluations.
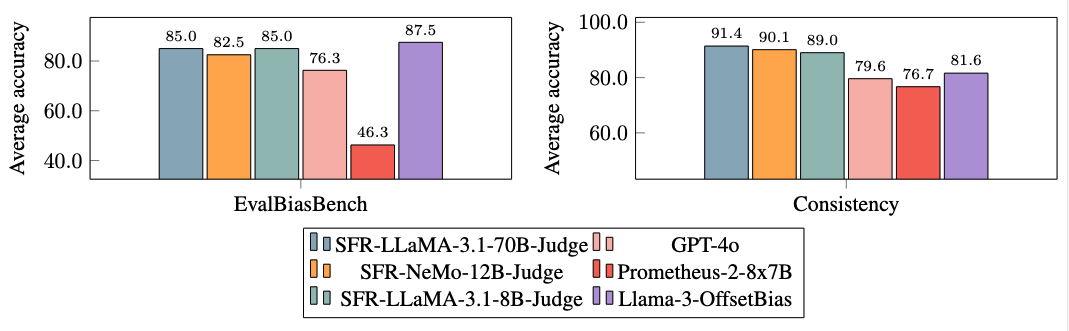
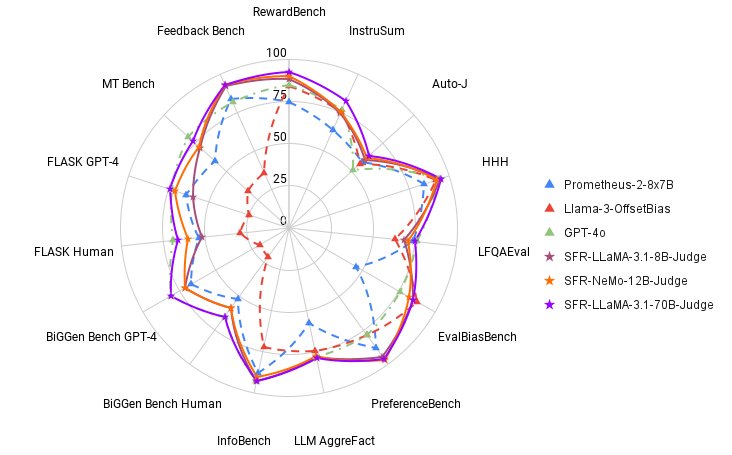
Extensive experiments revealed that SFR-Judge models are significantly less biased than competing models, as demonstrated by their performance on EvalBiasBench, a benchmark designed to test for six types of bias. The models exhibit high levels of pairwise order consistency across multiple benchmarks, indicating that their judgments remain stable even when the order of responses is altered. This robustness positions SFR-Judge as a reliable solution for automating the evaluation of LLMs, reducing the reliance on human annotators, and providing a scalable alternative for model assessment.
Key takeaways from the research:
- High Accuracy: SFR-Judge achieved top scores on 10 of 13 benchmarks, including a 92.7% accuracy on RewardBench, outperforming many state-of-the-art judge models.
- Bias Mitigation: The models demonstrated lower levels of bias, including length and position bias, compared to other judge models, as confirmed by their performance on EvalBiasBench.
- Versatile Applications: SFR-Judge supports three main evaluation tasks – pairwise comparisons, single ratings, and binary classification, making it adaptable to various evaluation scenarios.
- Structured Explanations: Unlike many judge models, SFR-Judge is trained to produce detailed explanations for its judgments, reducing the black-box nature of LLM-based evaluations.
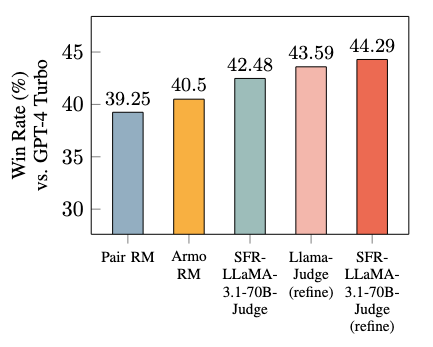
- Performance Boost in Downstream Models: The model’s explanations can improve downstream models’ outputs, making it an effective tool for RLHF scenarios.
In conclusion, the introduction of SFR-Judge by Salesforce AI Research marks a significant leap forward in the automated evaluation of large language models. By leveraging Direct Preference Optimization and a diverse set of training data, the research team has created a family of judge models that are both robust and reliable. These models can learn from diverse examples, provide detailed feedback, and reduce common biases, making them invaluable tools for evaluating and refining generative content. SFR-Judge sets a new benchmark in LLM-based evaluation and opens the door for further advancements in automated model assessment.
Check out the Paper and Details. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 50k+ ML SubReddit.
We are inviting startups, companies, and research institutions who are working on small language models to participate in this upcoming ‘Small Language Models’ Magazine/Report by Marketchpost.com. This Magazine/Report will be released in late October/early November 2024. Click here to set up a call!
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is committed to harnessing the potential of Artificial Intelligence for social good. His most recent endeavor is the launch of an Artificial Intelligence Media Platform, Marktechpost, which stands out for its in-depth coverage of machine learning and deep learning news that is both technically sound and easily understandable by a wide audience. The platform boasts of over 2 million monthly views, illustrating its popularity among audiences.
