
The human brain, regarded as the paradigm for neural network theories, concurrently processes information from various sensory inputs, such as visual, auditory, and tactile signals. Additionally, understanding from one source might help knowledge from another. However, due to the huge modality gap in deep learning, constructing a unified network capable of processing various input forms takes a lot of work. Models trained on one data modality must be adjusted to work with each data modality’s different data patterns. In contrast to spoken language, photographs have a significant degree of information redundancy caused by the tightly packed pixels in the images.
Contrarily, point clouds are difficult to describe because of their sparse distribution in 3D space and increased susceptibility to noise. Audio spectrograms are non-stationary, time-varying data patterns made up of combinations of waves from different frequency domains. Video data has the unique capacity to record spatial information and temporal dynamics since it comprises a series of picture frames. Graph data models complicated, many-to-many interactions between entities by representing items as nodes and relationships as edges in a graph. Due to the significant disparities between different data modalities, using other network topologies to encode each data modality independently is usual practice.
Point Transformer, for instance, uses vector-level position attention to extract structural information from 3D coordinates. Still, it cannot encode a picture, a sentence of natural language, or an audio spectrogram slice. Therefore, creating a single framework that can use a parameter space shared by several modalities to encode different data types takes time and effort. Through extensive multimodal pretraining on paired data, recently developed unified frameworks like VLMO, OFA, and BEiT-3 have improved the network’s capacity for multimodal understanding. However, because of their greater emphasis on vision and language, they cannot share the entire encoder across modalities. Deep learning has greatly benefited from the transformer architecture and attention mechanism other researchers presented for natural language processing (NLP).
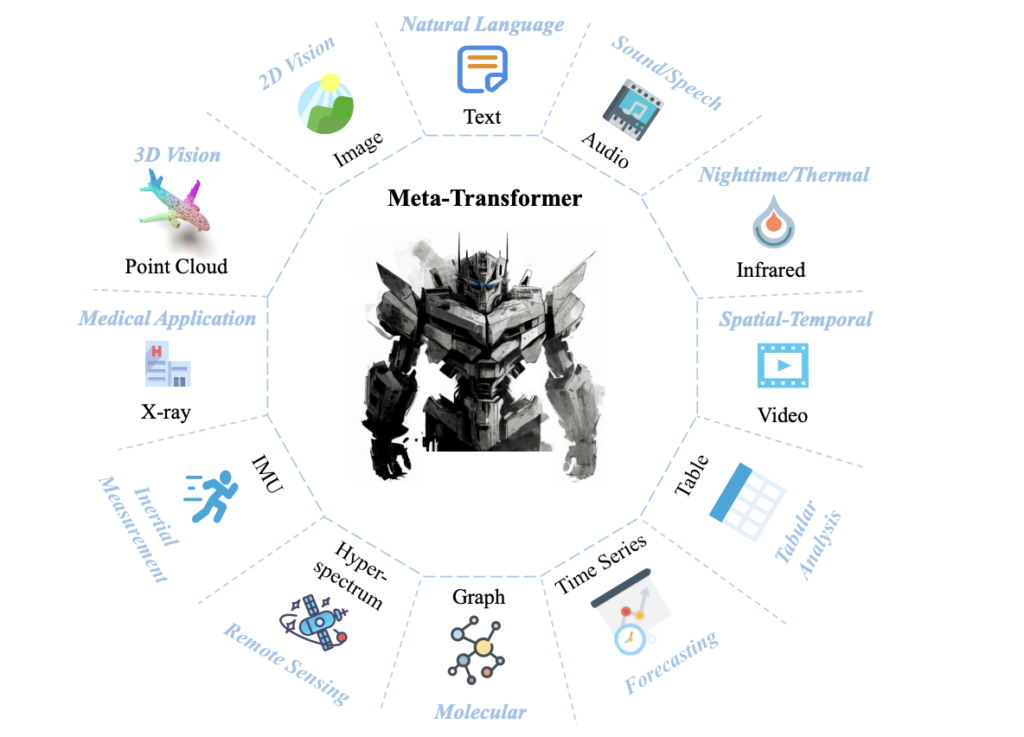
These developments have greatly improved perception across a variety of modalities, including 2D vision (including ViT and Swin Transformer), 3D vision (including Point Transformer and Point-ViT), auditory signal processing (AST), etc. These studies have illustrated the adaptability of transformer-based designs and motivated academics to investigate if foundation models for combining several modalities might be created, eventually realizing human-level perception across all modalities. Figure 1 illustrates how they investigate the potential of the transformer design to handle 12 modalities, including pictures, natural language, point clouds, audio spectrograms, videos, infrared, hyperspectral, X-rays, IMUs, tabular, graph, and time-series data.


They discuss the learning process for each modality using the transformers and address the difficulties in combining them into a unified framework. As a result, researchers from the Chinese University of Hong Kong and Shanghai AI Lab suggest a brand-new, integrated framework for multimodal learning called Meta-Transformer. The first framework, Meta-Transformer, uses the same set of parameters to simultaneously encode input from a dozen different modalities, enabling a more integrated approach to multimodal learning. A modality-specialist for data-to-sequence tokenization, a modality-shared encoder for extracting representations across modalities, and task-specific heads for downstream tasks are the three straightforward yet valuable components of Meta-Transformer. To be more precise, the Meta-Transformer first creates token sequences with shared manifold spaces from multimodal data.
After that, representations are extracted using a modality-shared encoder with frozen parameters. Individual tasks are further customized using the lightweight tokenizers and updated downstream task heads’ parameters. Finally, this straightforward approach can efficiently train task-specific and modality-generic representations. They carry out substantial research using several standards from 12 modalities. Meta-Transformer performs outstandingly processing data from several modalities, consistently outperforming state-of-the-art techniques in various multimodal learning tasks by only using pictures from the LAION-2B dataset for pretraining.
In conclusion, their contributions are as follows:
• They offer a unique framework called Meta-Transformer for multimodal research that enables a single encoder to simultaneously extract representations from several modalities using the same set of parameters.
• They thoroughly investigate the roles played by transformer components such as embeddings, tokenization, and encoders in processing multiple modalities for multimodal network architecture.
• Experimentally, Meta-Transformer achieves outstanding performance on various datasets regarding 12 modalities, which validates the further potential of Meta-Transformer for unified multimodal learning.
• Meta-Transformer sparks a promising new direction in developing a modality-agnostic framework that unifies all modalities.
Check out the Paper and Github. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 26k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.


Aneesh Tickoo is a consulting intern at MarktechPost. He is currently pursuing his undergraduate degree in Data Science and Artificial Intelligence from the Indian Institute of Technology(IIT), Bhilai. He spends most of his time working on projects aimed at harnessing the power of machine learning. His research interest is image processing and is passionate about building solutions around it. He loves to connect with people and collaborate on interesting projects.