Text-to-image diffusion models have exhibited impressive success in generating diverse and high-quality images based on input text descriptions. Nevertheless, they encounter challenges when the input text is lexically ambiguous or involves intricate details. This can lead to situations where the intended image content, such as an “iron” for clothes, is misrepresented as the “elemental” metal.
To address these limitations, existing methods have employed pre-trained classifiers to guide the denoising process. One approach involves blending the score estimate of a diffusion model with the gradient of a pre-trained classifier’s log probability. In simpler terms, this approach uses information from both a diffusion model and a pre-trained classifier to generate images that match the desired outcome and align with the classifier’s judgment of what the image should represent.
However, this method requires a classifier capable of working with real and noisy data.
Other strategies have conditioned the diffusion process on class labels using specific datasets. While effective, this approach is far from the full expressive capability of models trained on extensive collections of image-text pairs from the web.
An alternative direction involves fine-tuning a diffusion model or some of its input tokens using a small set of images related to a specific concept or label. Yet, this approach has drawbacks, including slow training for new concepts, potential changes in image distribution, and limited diversity captured from a small group of images.
This article reports a proposed approach that tackles these issues, providing a more accurate representation of desired classes, resolving lexical ambiguity, and improving the depiction of fine-grained details. It achieves this without compromising the original pretrained diffusion model’s expressive power or facing the mentioned drawbacks. The overview of this method is illustrated in the figure below.
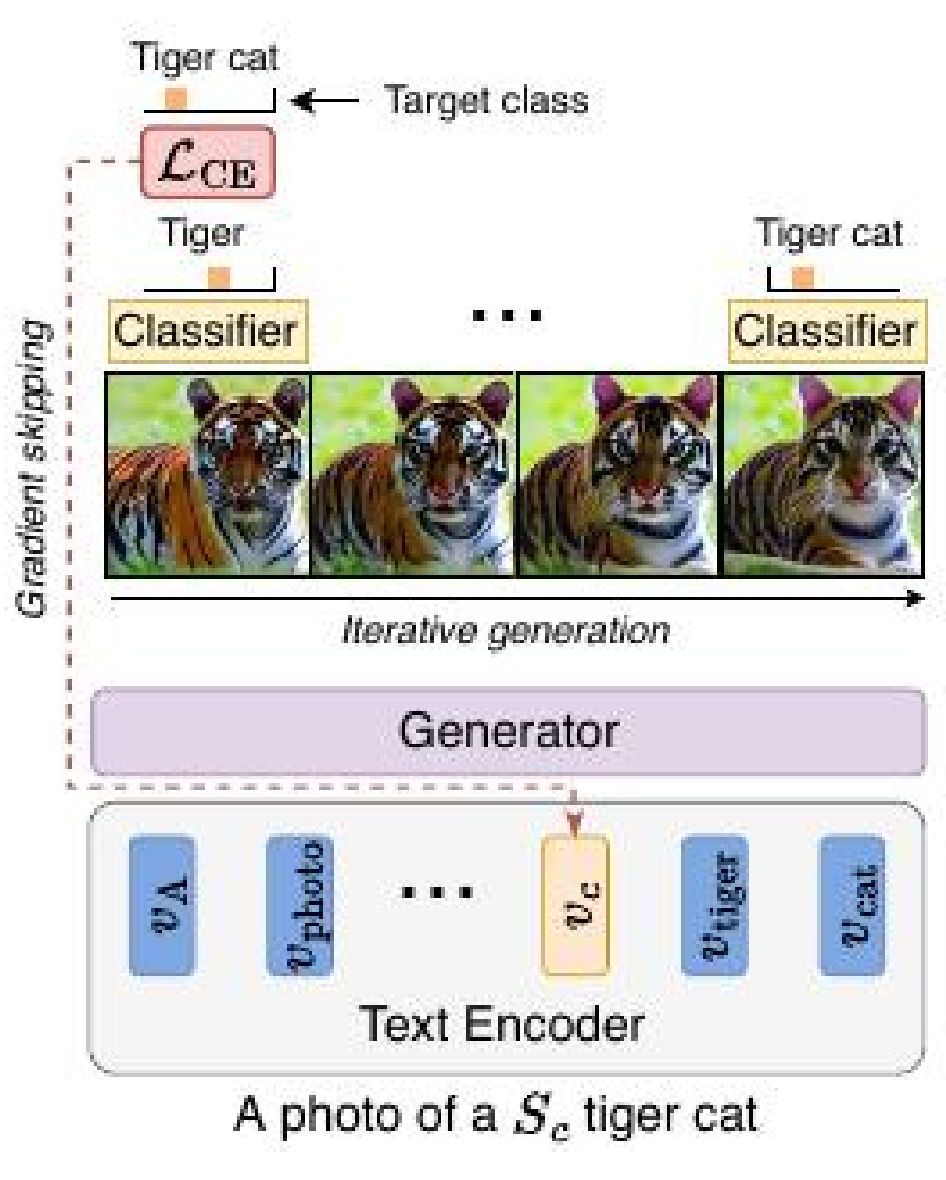

Instead of guiding the diffusion process or altering the entire model, this approach focuses on updating the representation of a single added token corresponding to each class of interest. Importantly, this update doesn’t involve model tuning on labeled images.
The method learns the token representation for a specific target class through an iterative process of generating new images with a higher class probability according to a pre-trained classifier. Feedback from the classifier guides the evolution of the designated class token in each iteration. A novel optimization technique called gradient skipping is employed, wherein the gradient is propagated solely through the final stage of the diffusion process. The optimized token is then incorporated as part of the conditioning text input to generate images using the original diffusion model.
According to the authors, this method offers several key advantages. It requires only a pre-trained classifier and doesn’t demand a classifier trained explicitly on noisy data, setting it apart from other class conditional techniques. Moreover, it excels in speed, allowing immediate improvements to generated images once a class token is trained, in contrast to more time-consuming methods.
Sample results selected from the study are shown in the image below. These case studies provide a comparative overview of the proposed and state-of-the-art approaches.

This was the summary of a novel AI non-invasive technique that exploits a pre-trained classifier to fine-tune text-to-image diffusion models. If you are interested and want to learn more about it, please feel free to refer to the links cited below.
Check out the Paper, Code, and Project. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 30k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
Daniele Lorenzi received his M.Sc. in ICT for Internet and Multimedia Engineering in 2021 from the University of Padua, Italy. He is a Ph.D. candidate at the Institute of Information Technology (ITEC) at the Alpen-Adria-Universität (AAU) Klagenfurt. He is currently working in the Christian Doppler Laboratory ATHENA and his research interests include adaptive video streaming, immersive media, machine learning, and QoS/QoE evaluation.
