LLMs demonstrate emergent intelligence with increased parameters, computes, and data, hinting at artificial general intelligence. Despite advancements, deployed LLMs still exhibit errors like hallucinations, bias, and factual inaccuracies. Also, the constant evolution of knowledge challenges their pretraining. Addressing errors promptly during deployment is crucial, as retraining or finetuning is often prohibitively costly, posing sustainability issues for accommodating lifelong knowledge growth.
While long-term memory can be updated through (re)pretraining, finetuning, and model editing, working memory aids inference, enhanced by methods like GRACE. However, debates persist on the efficacy of fine-tuning versus retrieval. Current knowledge injection methods face challenges like computational overhead and overfitting. Model editing techniques, including constrained finetuning and meta-learning, aim to efficiently edit LLMs. Recent advancements focus on lifelong editing but require extensive domain-specific training, posing challenges in predicting upcoming edits and accessing relevant data.
After studying the above issues and approaches thoroughly, researchers from Zhejiang University and Alibaba Group propose their method, WISE, a dual parametric memory scheme, comprising a main memory for pretrained knowledge and a side memory for edited knowledge. Only the side memory undergoes edits, with a router determining which memory to access for queries. For continual editing, WISE employs a knowledge-sharing mechanism, segregating edits into distinct parameter subspaces to prevent conflicts before merging them into a shared memory.
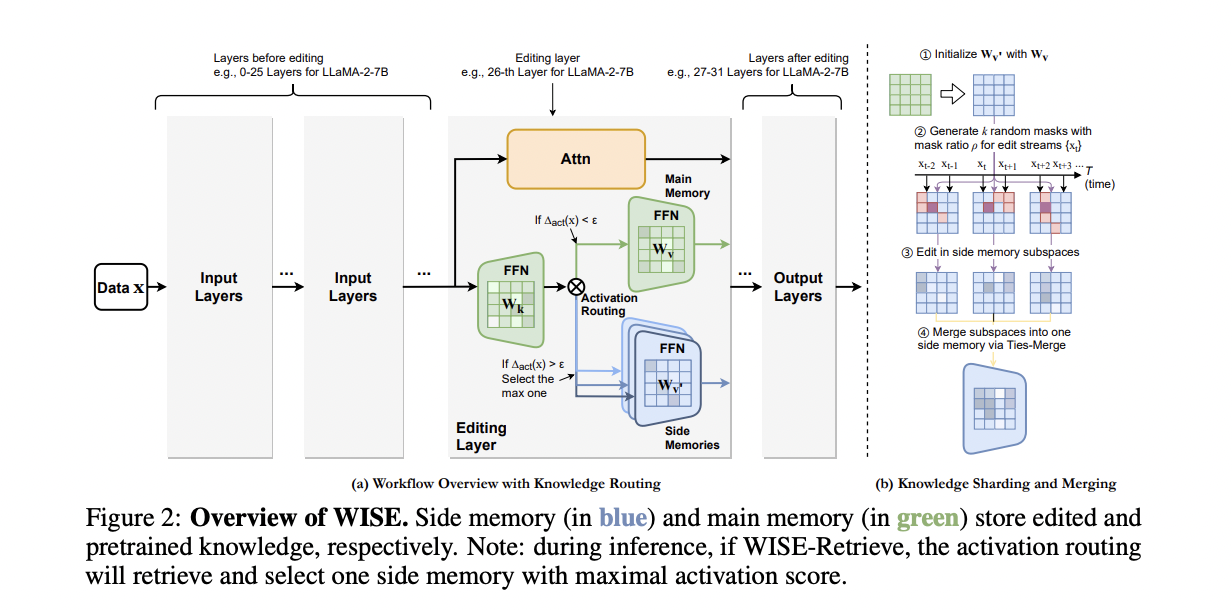
WISE comprises two main components: Side Memory Design and Knowledge Sharding and Merging. The former involves a side memory, initialized as a copy of a certain FFN layer of the LLM, storing edits, and a routing mechanism for memory selection during inference. The latter employs knowledge sharding to divide edits into random subspaces for editing and knowledge merging techniques to combine these subspaces into a unified side memory. Also, WISE introduces WISE-Retrieve, allowing retrieval among multiple side memories based on activation scores, enhancing lifelong editing scenarios.
WISE demonstrates superior performance compared to existing methods in both QA and Hallucination settings. It outperforms competitors, particularly in long editing sequences, achieving significant improvements in stability and managing sequential edits effectively. While methods like MEND and ROME are competitive initially, they falter as edit sequences lengthen. Directly editing long-term memory leads to significant declines in locality, impairing generalization. GRACE excels in locality but sacrifices generalization in continual editing. WISE achieves a balance between reliability, generalization, and locality, outperforming baselines across various tasks. In out-of-distribution evaluation, WISE exhibits excellent generalization performance, surpassing other methods.
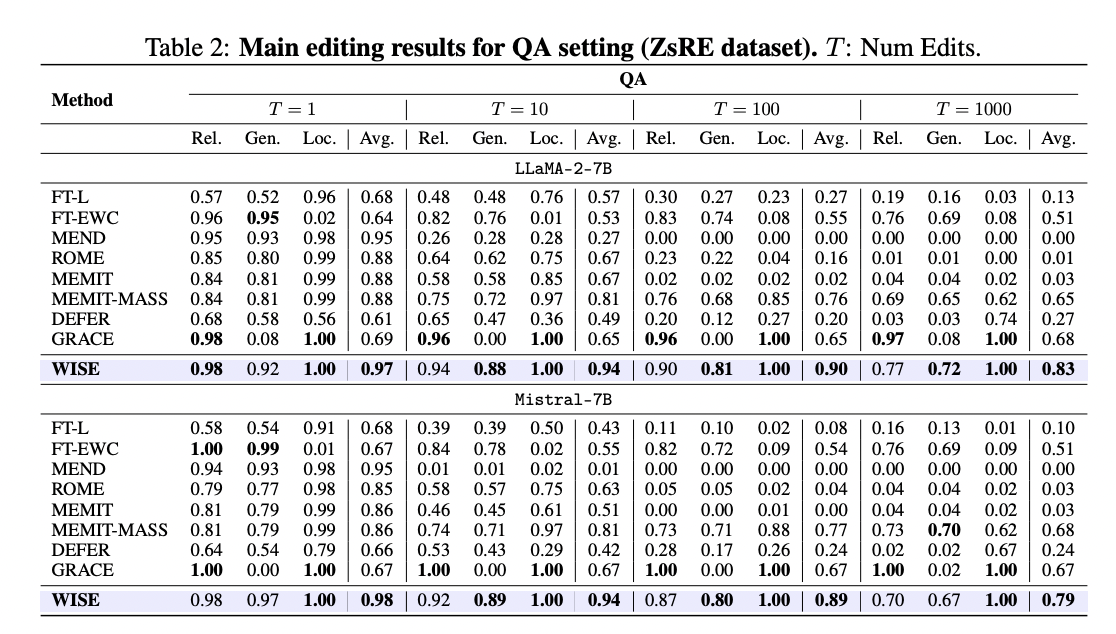
This research identifies the challenge of achieving reliability, generalization, and locality simultaneously in current lifelong modeling editing approaches, attributing it to the gap between working and long-term memory. To overcome this issue, WISE is proposed, comprising side memory and model merging techniques. Results indicate that WISE shows promise in simultaneously achieving high metrics across various datasets and LLM models.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 42k+ ML SubReddit
Asjad is an intern consultant at Marktechpost. He is persuing B.Tech in mechanical engineering at the Indian Institute of Technology, Kharagpur. Asjad is a Machine learning and deep learning enthusiast who is always researching the applications of machine learning in healthcare.
