

Adam is widely used in deep learning as an adaptive optimization algorithm, but it struggles with convergence unless the hyperparameter β2 is adjusted based on the specific problem. Attempts to fix this, like AMSGrad, require the impractical assumption of uniformly bounded gradient noise, which doesn’t hold in cases with Gaussian noise, as seen in variational autoencoders and diffusion models. Other methods, such as AdaShift, address convergence in limited scenarios but aren’t effective for general problems. Recent studies suggest Adam can converge by fine-tuning β2 per task, though this approach is complex and problem-specific, warranting further exploration for universal solutions.
Researchers from The University of Tokyo introduced ADOPT. This new adaptive gradient method achieves optimal convergence at an O(1/√T) rate without requiring specific choices for β2 or the bounded noise assumption. ADOPT addresses Adam’s non-convergence by excluding the current gradient from the second moment estimate and adjusting the order of momentum and normalization updates. Experiments across diverse tasks—such as image classification, generative modeling, language processing, and reinforcement learning—show ADOPT’s superior performance over Adam and its variants. The method also converges reliably in challenging cases, including scenarios where Adam and AMSGrad struggle.
This study focuses on minimizing an objective function that depends on a parameter vector by using first-order stochastic optimization methods. Rather than working with the exact gradient, they rely on an estimate known as the stochastic gradient. Since the function may be nonconvex, the goal is to find a stationary point where the gradient is zero. Standard analyses for convergence in this area generally make several key assumptions: the function has a minimum bound, the stochastic gradient provides an unbiased estimate of the gradient, the function changes smoothly, and the variance of the stochastic gradient is uniformly limited. For adaptive methods like Adam, an additional assumption about the gradient variance is often made to simplify convergence proofs. The researchers apply a set of assumptions to investigate how adaptive gradient methods converge without relying on the stricter assumption that the gradient noise remains bounded.
Prior research suggests that while basic stochastic gradient descent often converges in nonconvex settings, adaptive gradient methods like Adam are widely used in deep learning due to their flexibility. However, Adam sometimes needs to converge, especially in convex cases. A modified version called AMSGrad was developed to address this, which introduces a non-decreasing scaling of the learning rate by updating the second-moment estimate with a maximum function. Still, AMSGrad’s convergence is based on the stronger assumption of uniformly bounded gradient noise, which is not valid in all scenarios, such as in certain generative models. Therefore, the researchers propose a new adaptive gradient update approach that aims to ensure reliable convergence without relying on stringent assumptions about gradient noise, addressing Adam’s limitations regarding convergence and optimizing parameter dependencies.
The ADOPT algorithm is evaluated across various tasks to verify its performance and robustness compared to Adam and AMSGrad. Starting with a toy problem, ADOPT successfully converges where Adam does not, especially under high-gradient noise conditions. Testing with an MLP on the MNIST dataset and a ResNet on CIFAR-10 shows that ADOPT achieves faster and more stable convergence. ADOPT also outperforms Adam in applications such as Swin Transformer-based ImageNet classification, NVAE generative modeling, and GPT-2 pretraining under noisy gradient conditions and yields improved scores in LLaMA-7B language model finetuning on the MMLU benchmark.

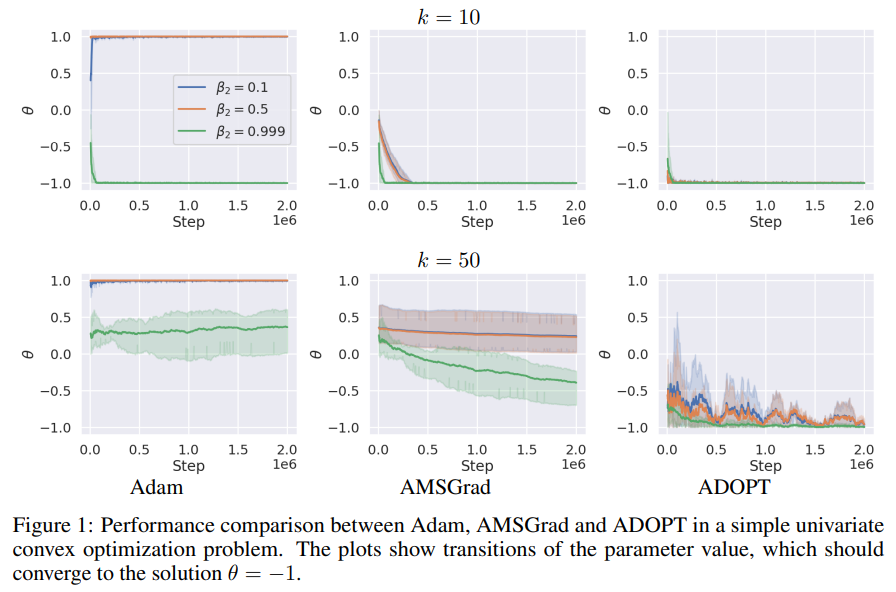
The study addresses the theoretical limitations of adaptive gradient methods like Adam, which need specific hyperparameter settings to converge. To resolve this, the authors introduce ADOPT, an optimizer that achieves optimal convergence rates across various tasks without problem-specific tuning. ADOPT overcomes Adam’s limitations by altering the momentum update order and excluding the current gradient from second-moment calculations, ensuring stability across tasks like image classification, NLP, and generative modeling. The work bridges theory and application in adaptive optimization, although future research may explore more relaxed assumptions to generalize ADOPT’s effectiveness further.
Check out the Paper and GitHub. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 55k+ ML SubReddit.
[AI Magazine/Report] Read Our Latest Report on ‘SMALL LANGUAGE MODELS‘


Sana Hassan, a consulting intern at Marktechpost and dual-degree student at IIT Madras, is passionate about applying technology and AI to address real-world challenges. With a keen interest in solving practical problems, he brings a fresh perspective to the intersection of AI and real-life solutions.