Knowledge Distillation has gained popularity for transferring the expertise of a “teacher” model to a smaller “student” model. Initially, an iterative learning process involving a high-capacity model is employed. The student, with equal or greater capacity, is trained with extensive augmentation. Subsequently, the trained student expands the dataset through pseudo-labeling new data. Notably, the student can surpass the teacher’s performance. Ensemble distillation, involving multiple teachers with restricted domain knowledge, has also been explored.
Recently, Foundation Models (FMs) have emerged as large, general models trained on vast datasets, exemplified by CLIP and DINOv2, showcasing remarkable zero-shot performances in computer vision tasks. SAM is noted for its instance segmentation capabilities, attributed to its strong dense feature representations. Despite their conceptual differences, these models can be effectively merged into a unified model through multi-teacher distillation.
Knowledge Distillation involves training a “student” model using soft targets generated by a pre-trained “teacher” model, either through the teacher’s output logits or intermediate network activations. Multi-Teacher Distillation explores jointly distilling a student model from multiple teachers, with each student mapped independently to each teacher. Also, Foundation Models, large and resource-intensive, are distilled to train smaller variants, as demonstrated in prior research works.
NVIDIA researchers present AM-RADIO to utilize multiple foundational models simultaneously, enabling student models, given sufficient capacity, to surpass individual teachers on crucial metrics. These student models mimic their teachers, facilitating performance on various downstream tasks, including CLIP-ZeroShot applications and Segment-Anything tasks. Also, they provide a study that evaluates the impact of hardware-efficient model architectures, highlighting the challenge of distilling ViT VFMs with CNN-like architectures. Which led to the development of a novel hybrid architecture E-RADIO, outperforming predecessors and exhibiting superior efficiency.
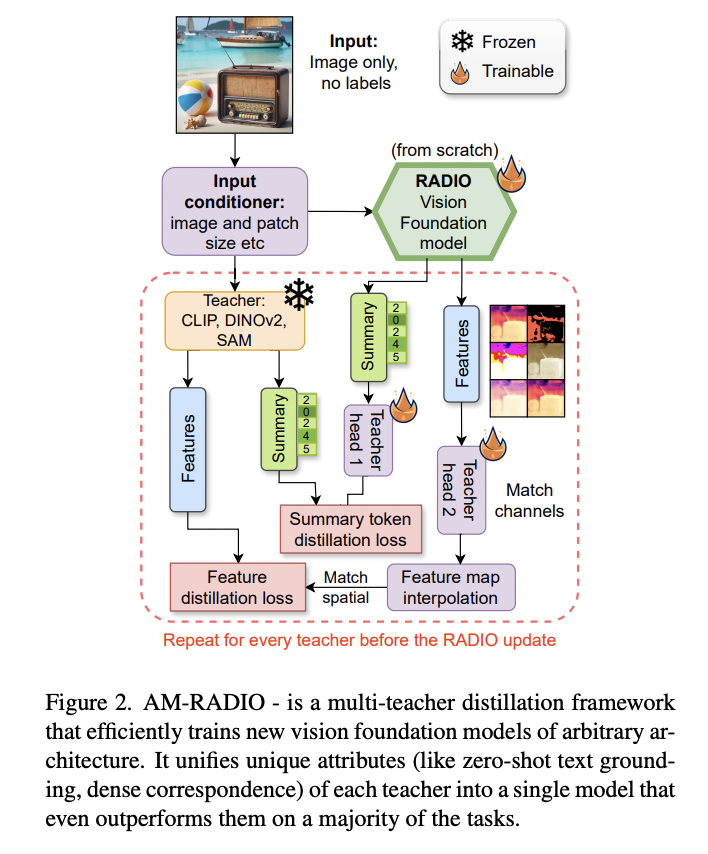
AM-RADIO framework aims to train a vision foundation model from scratch through multi-teacher distillation. Three seminal teacher model families, CLIP, DINOv2, and SAM, are selected for their outstanding performance across various tasks. Given the assumption that these teacher models represent a broad spectrum of internet images, no supplemental ground truth guidance is used. Evaluation metrics encompass image-level reasoning, pixel-level visual tasks such as segmentation mIOU on ADE20K and Pascal VOC, integration into large Vision-Language Models, and SAM-COCO instance segmentation.
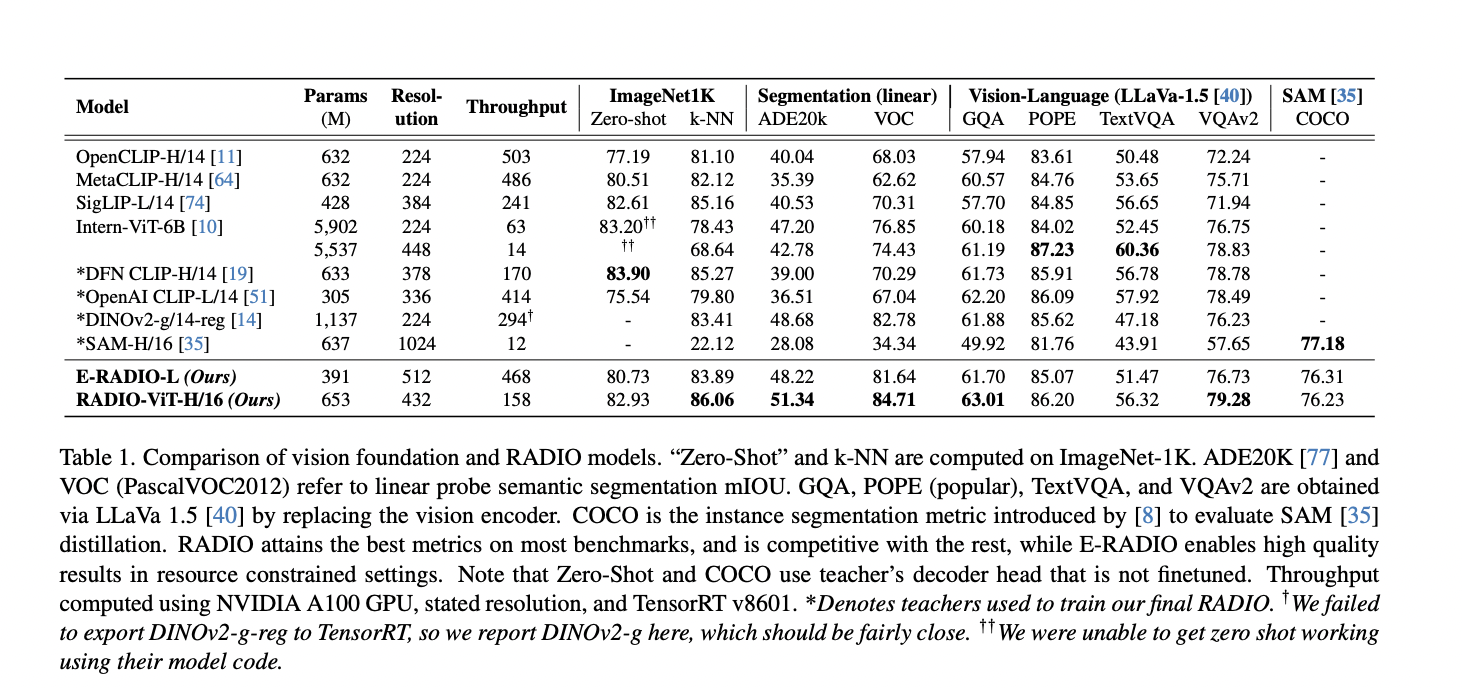
E-RADIO surpasses original teachers like CLIP, DINOv2, and SAM in various tasks including vision question answering. E-RADIO demonstrates superior performance across multiple benchmarks, exhibiting higher throughput and improved efficiency. Also, it outperforms ViT models in dense tasks such as semantic segmentation and instance segmentation. The framework’s flexibility is highlighted by its successful integration into visual question-answering setups, underscoring its potential for diverse applications.
To recapitulate, Knowledge Distillation has become a prominent technique for transferring knowledge from a “teacher” to a smaller “student” model, surpassing the teacher’s performance. This approach has extended to ensemble distillation and Foundation Models (FMs) like CLIP and DINOv2, known for their zero-shot capabilities and instance segmentation prowess. NVIDIA introduces AM-RADIO, utilizing multiple foundational models simultaneously, outperforming original teachers like CLIP and DINOv2. E-RADIO, a novel hybrid architecture, emerges to address the challenge of distilling FMs with CNN-like architectures. Through multi-teacher distillation, AM-RADIO trains a vision foundation model from scratch, demonstrating superior performance in various tasks, including vision question answering and instance segmentation.
Check out the Paper and GitHub. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 42k+ ML SubReddit
Asjad is an intern consultant at Marktechpost. He is persuing B.Tech in mechanical engineering at the Indian Institute of Technology, Kharagpur. Asjad is a Machine learning and deep learning enthusiast who is always researching the applications of machine learning in healthcare.
