We have long been intrigued by the challenge of understanding how our brain functions. The field of neuroscience has developed a lot, but we still lack solid information about how our brains work in detail. We are working hard to find it out, but we still have a long way to go.
One topic that neuroscience has been busy with was deciphering the complex relationship between brain activity and cognitive states. A deeper understanding of how environmental inputs are encoded in neural processes holds great potential for advancing our knowledge of the brain and its mechanisms. Recent advancements in computational approaches have opened up new opportunities for unraveling these mysteries, with functional magnetic resonance imaging (fMRI) emerging as a powerful tool in this domain. By detecting changes in blood oxygenation levels, fMRI enables the measurement of neural activity and has already found applications in real-time clinical settings.
One particularly promising application of fMRI is its potential for mind reading in brain-computer interfaces. By decoding neural activity patterns, it becomes possible to infer information about a person’s mental state and even reconstruct images from their brain activity. Previous studies in this area have predominantly employed simple mappings, such as ridge regression, to relate fMRI activity to image generation models.
However, as with all other domains, the emergence of successful AI models has caused huge leaps in brain image reconstruction. We have seen some methods that try to reconstruct what we saw using fMRI scans and diffusion models. Today, we have another method to talk about that tries to tackle brain scan decoding using AI models. Time to meet MindEye.
MindEye aims to decode environmental inputs and cognitive states from brain activity. It maps fMRI activity to the image embedding latent space of a pre-trained CLIP model using a combination of large-scale MLPs, contrastive learning, and diffusion models. The model consists of two pipelines: a high-level (semantic) pipeline and a low-level (perceptual) pipeline.
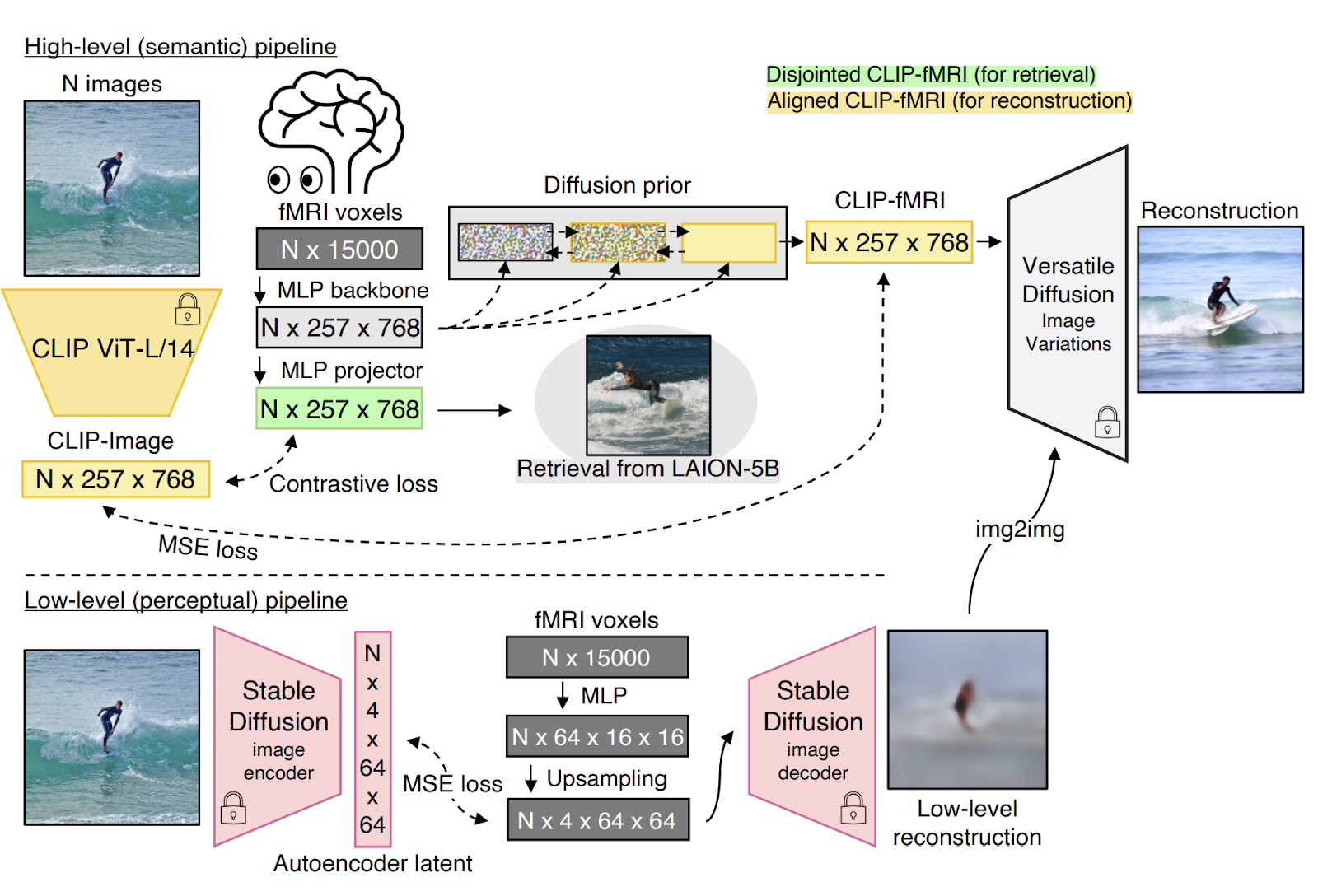
In the high-level pipeline, fMRI voxels are mapped to the CLIP image space, which is more semantic in nature. Then contrastive learning is used to train the model and introduce fMRI as an additional modality to the pre-trained CLIP model’s embedding space. A bidirectional version of mixup contrastive data augmentation is used to improve model performance.
The low-level pipeline, on the other hand, maps fMRI voxels to the embedding space of Stable Diffusion’s variational autoencoder (VAE). The output of this pipeline can be used to reconstruct blurry images that exhibit state-of-the-art low-level image metrics. Since the output is not of high quality, the img2img method is used at the end to improve the image reconstructions further while preserving high-level metrics.

MindEye achieves state-of-the-art results in both image reconstruction and retrieval tasks. It produces high-quality reconstructions that match the low-level features of the original images and perform well on low- and high-level image metrics. The disjointed CLIP fMRI embeddings obtained by MindEye also show excellent performance in image and brain retrieval tasks.
Check Out The Paper and Code. Don’t forget to join our 23k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more. If you have any questions regarding the above article or if we missed anything, feel free to email us at Asif@marktechpost.com
🚀 Check Out 100’s AI Tools in AI Tools Club
Ekrem Çetinkaya received his B.Sc. in 2018, and M.Sc. in 2019 from Ozyegin University, Istanbul, Türkiye. He wrote his M.Sc. thesis about image denoising using deep convolutional networks. He received his Ph.D. degree in 2023 from the University of Klagenfurt, Austria, with his dissertation titled “Video Coding Enhancements for HTTP Adaptive Streaming Using Machine Learning.” His research interests include deep learning, computer vision, video encoding, and multimedia networking.
