
LLMs have advanced significantly, showcasing their capabilities across various domains. Intelligence, a multifaceted concept, involves multiple cognitive skills, and LLMs have pushed AI closer to achieving general intelligence. Recent developments, such as OpenAI’s o1 model, integrate reasoning techniques like Chain-of-Thought (CoT) prompting to enhance problem-solving. While o1 performs well in general tasks, its effectiveness in specialized areas like medicine remains uncertain. Current benchmarks for medical LLMs often focus on limited aspects, such as knowledge, reasoning, or safety, complicating a comprehensive evaluation of these models in complex medical tasks.
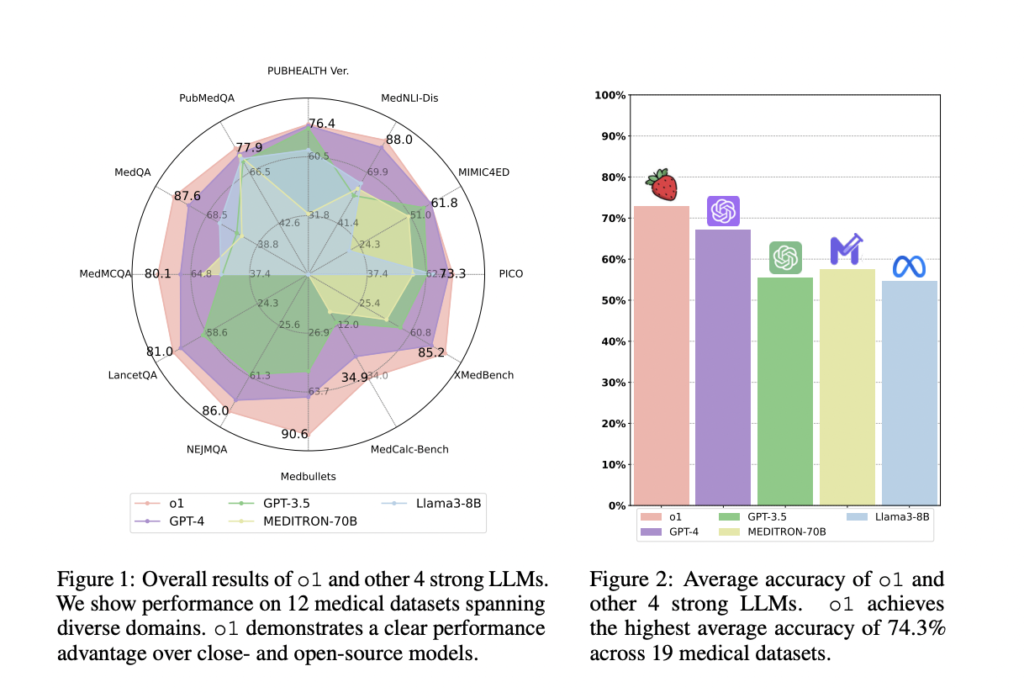
Researchers from UC Santa Cruz, the University of Edinburgh, and the National Institutes of Health evaluated OpenAI’s o1 model, the first LLM using CoT techniques with reinforcement learning. This study explored o1’s performance in medical tasks, assessing understanding, reasoning, and multilinguality across 37 medical datasets, including two new QA benchmarks. The o1 model outperformed GPT-4 in accuracy by 6.2% but still exhibited issues like hallucination and inconsistent multilingual ability. The study emphasizes the need for consistent evaluation metrics and improved instruction templates.


LLMs have shown notable progress in language understanding tasks through next-token prediction and instruction fine-tuning. However, they often struggle with complex logical reasoning tasks. To overcome this, researchers introduced CoT prompting, guiding models to emulate human reasoning processes. OpenAI’s o1 model, trained with extensive CoT data and reinforcement learning, aims to enhance reasoning capabilities. LLMs like GPT-4 have demonstrated strong performance in the medical domain, but domain-specific fine-tuning is necessary for reliable clinical applications. The study investigates o1’s potential for clinical use, showing improvements in understanding, reasoning, and multilingual capabilities.
The evaluation pipeline focuses on three key aspects of model capabilities: understanding, reasoning, and multilinguality, aligning with clinical needs. These aspects are tested across 37 datasets, covering tasks such as concept recognition, summarization, question answering, and clinical decision-making. Three prompting strategies—direct prompting, chain-of-thought, and few-shot learning—guide the models. Metrics such as accuracy, F1-score, BLEU, ROUGE, AlignScore, and Mauve assess model performance by comparing generated responses to ground-truth data. These metrics measure accuracy, response similarity, factual consistency, and alignment with human-written text, ensuring a comprehensive evaluation.
The experiments compare o1 with models like GPT-3.5, GPT-4, MEDITRON-70B, and Llama3-8B across medical datasets. o1 excels in clinical tasks such as concept recognition, summarization, and medical calculations, outperforming GPT-4 and GPT-3.5. It achieves notable accuracy improvements on benchmarks like NEJMQA and LancetQA, surpassing GPT-4 by 8.9% and 27.1%, respectively. o1 also delivers higher F1 and accuracy scores in tasks like BC4Chem, highlighting its superior medical knowledge and reasoning abilities and positioning it as a promising tool for real-world clinical applications.
The o1 model demonstrates significant progress in general NLP and the medical field but has certain drawbacks. Its longer decoding time—more than twice that of GPT-4 and nine times that of GPT-3.5—can lead to delays in complex tasks. Additionally, o1’s performance is inconsistent across different tasks, underperforming in simpler tasks like concept recognition. Traditional metrics like BLEU and ROUGE may not adequately assess its output, especially in specialized medical fields. Future evaluations require improved metrics and prompting techniques to capture its capabilities better and mitigate limitations like hallucination and factual accuracy.
Check out the Paper and Project. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 50k+ ML SubReddit


Sana Hassan, a consulting intern at Marktechpost and dual-degree student at IIT Madras, is passionate about applying technology and AI to address real-world challenges. With a keen interest in solving practical problems, he brings a fresh perspective to the intersection of AI and real-life solutions.