

Recent advancements in Large Language Models (LLMs) have reshaped the Artificial intelligence (AI)landscape, paving the way for the creation of Multimodal Large Language Models (MLLMs). These advanced models expand AI capabilities beyond text, allowing understanding and generation of content like images, audio, and video, signaling a significant leap in AI development. Despite the remarkable progress of MLLMs, current open-source solutions exhibit many deficiencies, particularly in multimodal capabilities and the quality of user interaction experiences. The impressive multimodal abilities and interactive experience of new AI models like GPT-4o highlight its critical role in practical applications, yet it needs a high-performing open-source counterpart.
Open-source MLLMs have shown increasingly powerful abilities, with efforts from both academia and industry fueling the rapid development of models. LLMs such as LLaMA, MAP-Neo, Baichuan, Qwen, and Mixtral are trained on large amounts of text data, exhibiting strong capacities in natural language processing and task resolution through text generation capacity. Vision-Language Models (VLMs) have shown great potential in addressing vision-focused issues, with models including LLaVA, DeepSeek-VL], the Qwen-VL series, InternVL families, and MiniCPM. Similarly, audio-language models (ALMs) work with audio and text data, using audio data to understand sounds and vocals, and they use models such as Qwen-Audio, SALMONN, and SpeechGPT.
However, open-source models are still behind privately owned models like GPT-4o when it comes to handling different types of data like images, text, etc., and very few open-source models do this well. To solve this problem, researchers introduced Baichuan-Omni, an open-source model that can handle data like audio, images, videos, and text all at once.
Researchers from Westlake University and Zhejiang University introduced an omni-modal LLM Baichuan-Omni alongside a multimodal training scheme designed to facilitate advanced multimodal processing and better user interactions. It also provides multilingual support for languages such as English and Chinese. The training framework features a comprehensive pipeline that includes the construction of omni-modal training data, multimodal alignment pre-training, and multimodal supervised fine-tuning, with a particular focus on enhancing omni-modal instruction-following capabilities. The model first learns to interconnect the different data types and features, like images with captions, text from documents (OCR), and audio that matches the text. This step helps the model understand and work with both visuals and sounds. Then, the model is trained on more than 200 tasks to improve its ability to follow detailed instructions that involve multiple types of information and data.

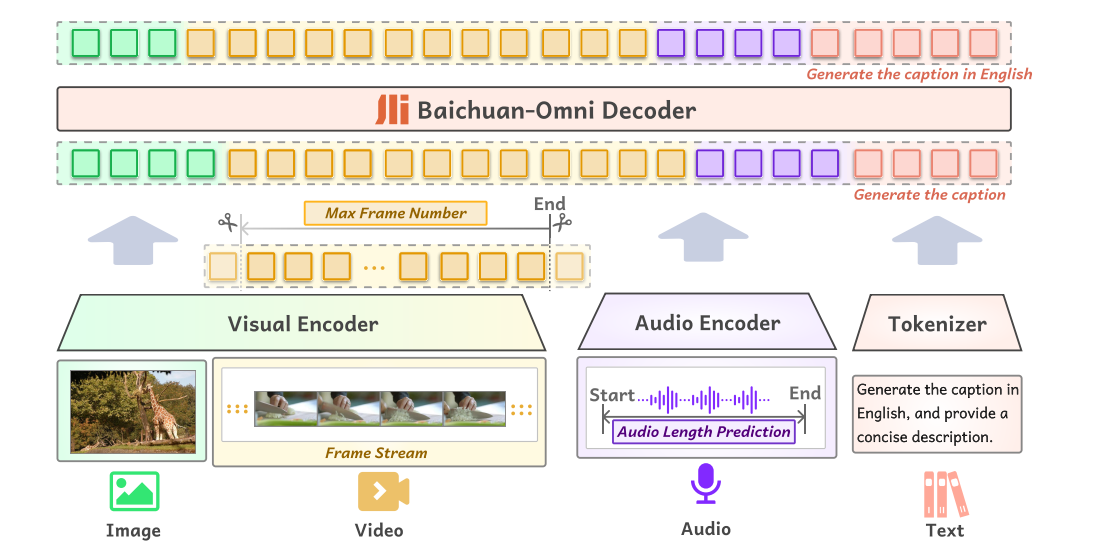
The training of the omni-modal model uses a variety of datasets that include text, images, videos, and audio from both open-source and synthetic sources. For images, data like captions, OCR, and charts are used, while video data comes from tasks such as classification and motion recognition, with some captions generated by GPT-4. Audio data collected from various environments, accents, and languages is processed through speech recognition and quality checks, refining multiple transcripts for better accuracy. Text data comes from sources like websites, blogs, and books, focusing on variety and quality. Cross-modal data combines image, audio, and text, using text-to-speech technology to enhance the model’s ability to understand interactions between different types of data. The multimodal alignment pre-training process merges images, videos, and audio with language to enhance the model’s understanding. For the image-language branch, the model is trained in stages to improve image-text tasks like captioning and visual question answering (VQA). The video-language branch builds on this by aligning video frames with text, while the audio-language branch uses advanced techniques to preserve audio information when mapping it to text. Finally, the “Omni-Alignment” stage combines image, video, and audio data for comprehensive multimodal learning. The research also delves into the performance of advanced AI models designed to process various media types, with a particular focus on the Baichuan-Omni model. This model demonstrates impressive capabilities in tasks ranging from Automatic Speech Recognition (ASR) to video understanding, outperforming other leading models in areas like Chinese language transcription and speech-to-text translation. The research highlights the importance of factors such as visual encoder resolution and frame count in video processing, noting significant improvements when using adaptive resolutions. To enhance the models’ versatility, the training data was expanded to cover a wider range of tasks, including mathematical reasoning and video descriptions, etc.



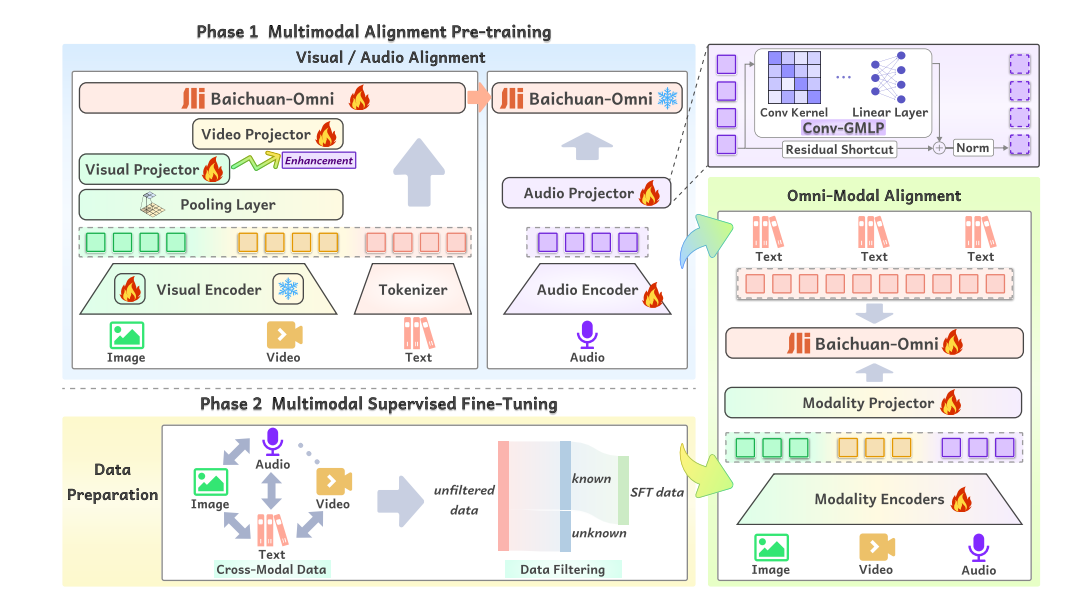
As conclusion the open-sourced Baichuan-Omni is a step toward developing a truly omni-modal LLM that encompasses all human senses. With omni-modal pretraining and fine-tuning using high-quality omni-modal data, this version of Baichuan-Omni achieved leading levels in integrating comprehension across video, image, text, and audio.
Despite its promising performance, there remains significant room for improvement in the foundational capabilities across each modality. This includes enhancing text extraction capabilities, supporting longer video understanding, developing an end-to-end TTS system integrated with LLMs, and improving the ability to understand not only human voices but also natural environmental sounds, such as flowing water, bird calls, and collision noises, among others. Demonstrating strong performance across various omni-modal and multimodal benchmarks, this paper can serve as a competitive baseline for the open-source community in advancing multimodal understanding and real-time interaction and as the base for incoming advancement!
Check out the Paper and GitHub. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 50k+ ML SubReddit.
[Upcoming Live Webinar- Oct 29, 2024] The Best Platform for Serving Fine-Tuned Models: Predibase Inference Engine (Promoted)


Divyesh is a consulting intern at Marktechpost. He is pursuing a BTech in Agricultural and Food Engineering from the Indian Institute of Technology, Kharagpur. He is a Data Science and Machine learning enthusiast who wants to integrate these leading technologies into the agricultural domain and solve challenges.