Large Language Models (LLMs) have driven remarkable advancements across various Natural Language Processing (NLP) tasks. These models excel in understanding and generating human-like text, playing a pivotal role in applications such as machine translation, summarization, and more complex reasoning tasks. The progression in this field continues to transform how machines comprehend and process language, opening new avenues for research and development.
A significant challenge in this field is the gap between LLMs’ reasoning capabilities and human-level expertise. This disparity is particularly evident in complex reasoning tasks where traditional models need help consistently producing accurate results. The issue stems from the models’ reliance on majority voting mechanisms, which often fail when incorrect answers dominate the pool of generated responses.
Existing work includes Chain-of-Thought (CoT) prompting, which enhances reasoning by generating intermediate steps. Self-consistency employs multiple reasoning chains, selecting the most frequent answer. Complexity-based prompting filters reasoning chains by complexity. DiVeRSe trains verifiers to score chains, while Progressive-Hint Prompting uses previous answers as hints. These methods aim to improve LLMs’ reasoning capabilities by refining the consistency and accuracy of generated answers.
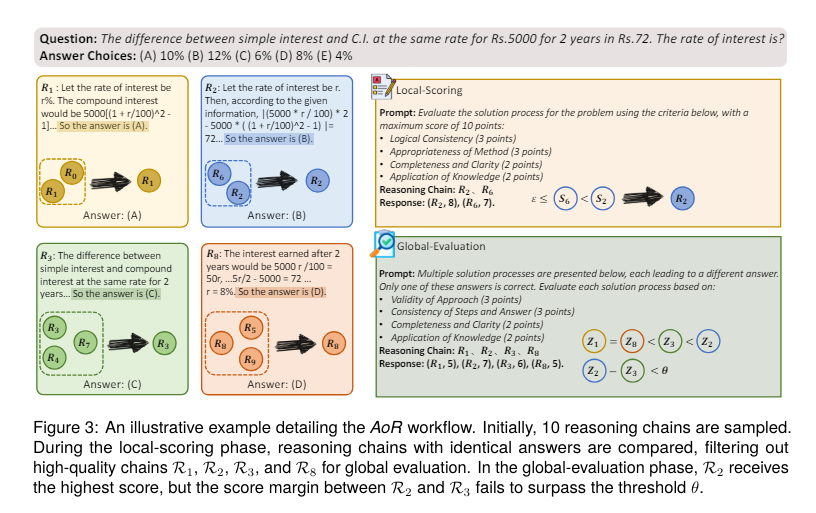
Researchers from Fudan University, the National University of Singapore, and the Midea AI Research Center have introduced a hierarchical reasoning aggregation framework called AoR (Aggregation of Reasoning). This innovative framework shifts the focus from answer frequency to evaluating reasoning chains. AoR incorporates dynamic sampling, which adjusts the number of reasoning chains based on the complexity of the task, thereby enhancing the accuracy and reliability of LLMs’ reasoning capabilities.
The AoR framework operates through a two-phase process: local scoring and global-evaluation. In the local scoring phase, reasoning chains yielding identical answers are evaluated. The emphasis is on the reasoning process’s soundness and the reasoning steps’ appropriateness. Chains that score highest in these evaluations are selected for the next phase. During the global evaluation phase, the chosen chains are assessed for their logical coherence and consistency between the reasoning process and the corresponding answers. This rigorous evaluation ensures the final answer is derived from the most logically sound reasoning chain.
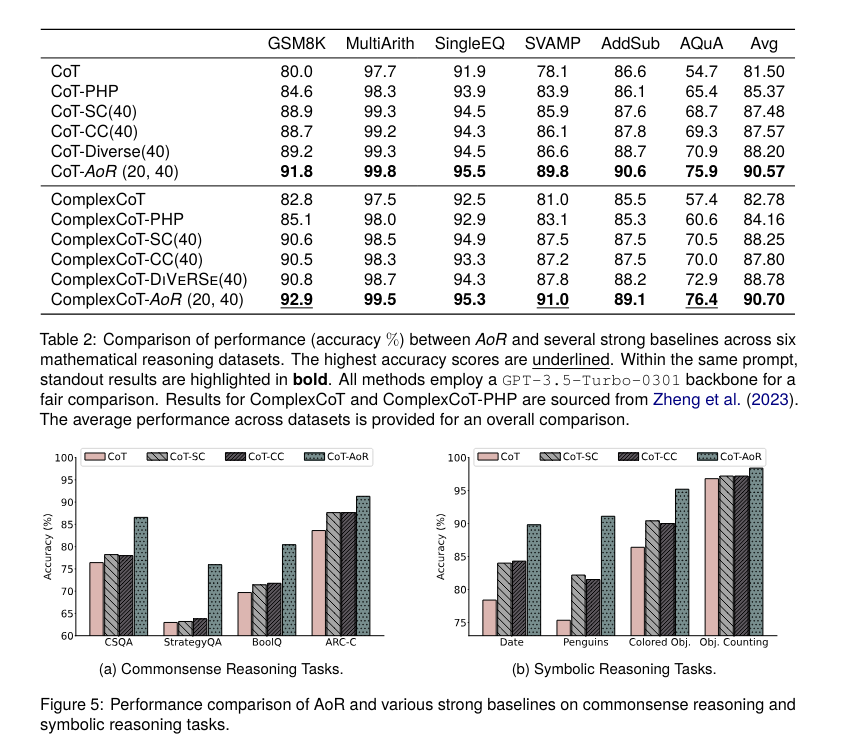
Experimental results demonstrate that AoR significantly outperforms traditional ensemble methods in complex reasoning tasks. For instance, in a series of challenging reasoning tasks, AoR achieved an accuracy improvement of up to 7.2% on the AQuA dataset compared to the Self-Consistency method. The framework also adapts well to various LLM architectures, including GPT-3.5-Turbo-0301, and shows a superior performance ceiling. Notably, AoR’s dynamic sampling capability effectively balances the performance with computational cost, reducing the overhead by 20% compared to existing methods while maintaining high accuracy.
To illustrate, in mathematical reasoning tasks, AoR outperformed all baseline approaches across six datasets. Under the Chain-of-Thought (CoT) prompting, AoR achieved an average performance boost of 2.37% compared to the DiVeRSe method. Specifically, the average performance improved by 3.09% compared to the Self-Consistency method, with significant gains in datasets like GSM8K and MultiArith. Furthermore, AoR demonstrated substantial improvements in commonsense reasoning tasks, achieving an average performance increase of 8.45% over the Self-Consistency method.
Dynamic sampling plays a crucial role in AoR’s success. By leveraging evaluation scores from the global evaluation phase, AoR dynamically adjusts the sampling of reasoning chains based on the model’s confidence. This approach not only enhances accuracy but also optimizes computational efficiency. For example, in the AQuA dataset, the dynamic sampling process reduced the number of samples needed, focusing computational efforts on more complex queries and ensuring precise results.

In conclusion, the AoR framework addresses a critical limitation in LLMs’ reasoning capabilities by introducing a method that evaluates and aggregates reasoning processes. This innovative approach improves the accuracy and efficiency of LLMs in complex reasoning tasks, making significant strides in bridging the gap between machine and human reasoning. The research team from Fudan University, the National University of Singapore, and the Midea AI Research Center has provided a promising solution that enhances the performance and reliability of LLMs, setting a new benchmark in natural language processing.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 42k+ ML SubReddit
Nikhil is an intern consultant at Marktechpost. He is pursuing an integrated dual degree in Materials at the Indian Institute of Technology, Kharagpur. Nikhil is an AI/ML enthusiast who is always researching applications in fields like biomaterials and biomedical science. With a strong background in Material Science, he is exploring new advancements and creating opportunities to contribute.
