Generating versatile and high-quality text embeddings across various tasks is a significant challenge in natural language processing (NLP). Current embedding models, despite advancements, often struggle to handle unseen tasks and complex retrieval operations effectively. These limitations hinder their ability to adapt dynamically to diverse contexts, a critical requirement for real-world applications. Addressing this challenge is essential for advancing the field of AI, enabling the development of more robust and adaptable systems capable of performing well across a wide range of scenarios.
Current methods for text embedding rely heavily on sophisticated modifications to large language model (LLM) architectures, such as bidirectional attention mechanisms and various pooling strategies. While these approaches have led to performance improvements in specific scenarios, they often come with significant drawbacks. These include increased computational complexity and a lack of flexibility when adapting to new tasks. Moreover, many of these models require extensive pre-training on large datasets, which can be both resource-intensive and time-consuming. Despite these efforts, models like NV-Embed and GritLM still fall short in their ability to generalize effectively across different tasks, particularly when they encounter scenarios that were not part of their training data.
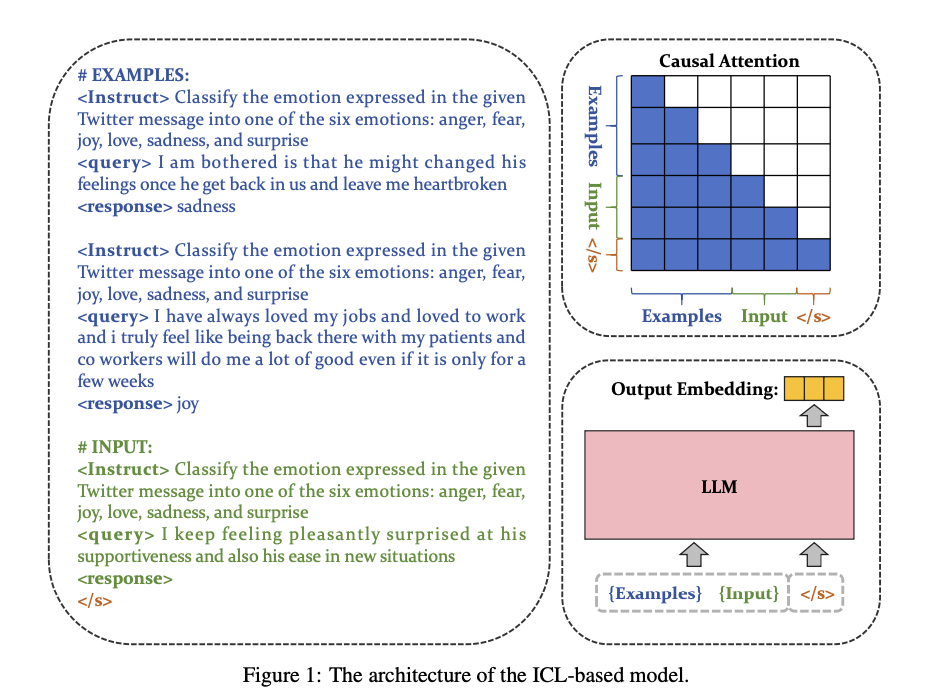
The researchers from Beijing Academy of Artificial Intelligence, Beijing University of Posts and Telecommunications, Chinese Academy of Sciences and University of Science, and Technology of China introduce a novel model, bge-en-icl, which enhances the generation of text embeddings by leveraging the in-context learning (ICL) capabilities of LLMs. This approach addresses the limitations of existing models by integrating task-specific examples directly into the query input, enabling the model to generate embeddings that are more relevant and generalizable across various tasks. The innovation lies in maintaining the simplicity of the original LLM architecture while incorporating ICL features, avoiding the need for extensive architectural modifications or additional pre-training. This method proves highly effective, setting new performance benchmarks across diverse tasks without sacrificing the model’s ability to adapt to new contexts.
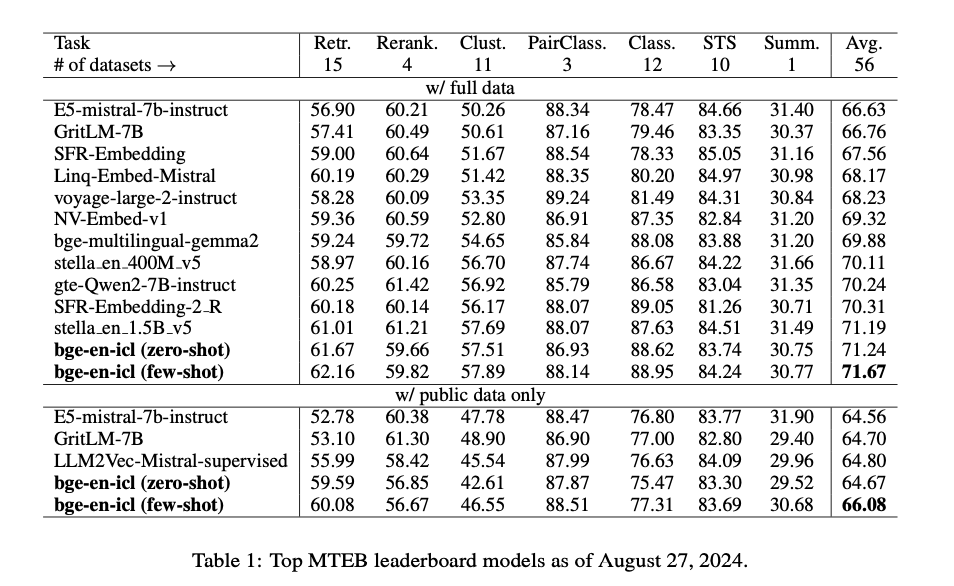
The bge-en-icl model is based on the Mistral-7B backbone, known for its effectiveness in NLP tasks. A key aspect of this method is the use of in-context learning during training, where task-specific examples are integrated into the query input. This allows the model to learn embeddings that are both task-specific and generalizable. The model is fine-tuned using a contrastive loss function, designed to maximize the similarity between relevant query-passage pairs while minimizing it for irrelevant ones. The training process involves a diverse set of tasks, such as retrieval, reranking, and classification, ensuring broad applicability. The bge-en-icl model is tested on benchmarks like MTEB and AIR-Bench, consistently outperforming other models, particularly in few-shot learning scenarios.
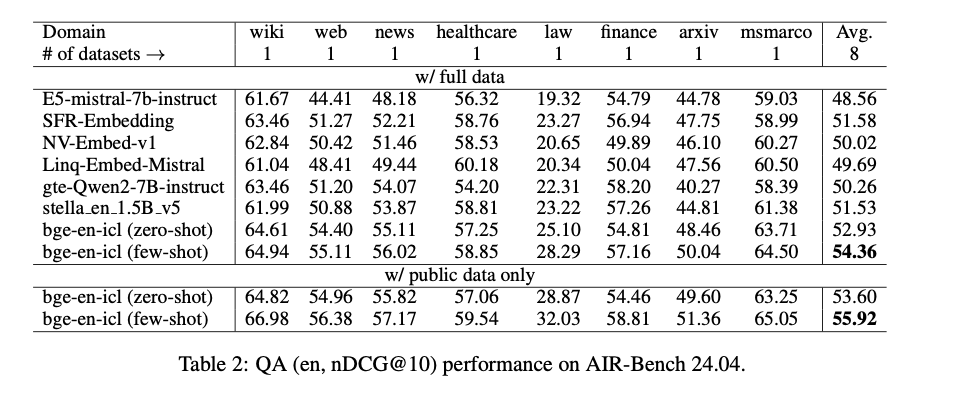
The bge-en-icl model demonstrates significant advancements in text embedding generation, achieving state-of-the-art performance across various tasks on the MTEB and AIR-Bench benchmarks. Notably, the model excels in few-shot learning scenarios, outperforming several leading models in retrieval, classification, and clustering tasks. For instance, it achieves high scores in both retrieval and classification, highlighting its capability to generate relevant and generalizable embeddings. These results underscore the effectiveness of incorporating in-context learning (ICL) into the embedding process, allowing the model to adapt dynamically to diverse tasks while maintaining simplicity in its architectural design. This innovative approach not only improves performance but also broadens the applicability of text embeddings in real-world scenarios.
In conclusion, the researchers have made a substantial contribution to the field of text embedding by developing the bge-en-icl model, which effectively leverages in-context learning to improve the adaptability and performance of LLMs. By integrating task-specific examples directly into the query input, this method overcomes the limitations of existing models, enabling the generation of high-quality embeddings across a wide range of tasks. The bge-en-icl model sets new benchmarks on MTEB and AIR-Bench, demonstrating that simplicity combined with ICL can lead to highly effective and versatile AI systems. This approach has the potential to significantly impact AI research, offering a path forward for creating more adaptable and efficient models for real-world applications.
Check out the Paper and GitHub. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 50k+ ML SubReddit
Aswin AK is a consulting intern at MarkTechPost. He is pursuing his Dual Degree at the Indian Institute of Technology, Kharagpur. He is passionate about data science and machine learning, bringing a strong academic background and hands-on experience in solving real-life cross-domain challenges.
