Recent advancements in healthcare AI, including medical LLMs and LMMs, show great potential for improving access to medical advice. However, these models are largely English-centric, limiting their utility for non-English-speaking populations, such as those in Arabic-speaking regions. Furthermore, many medical LMMs need help to balance advanced medical text comprehension with multimodal capabilities. While models like LLaVa-Med and MiniGPT-Med address specific tasks such as multi-turn conversations or chest X-ray analysis, others, like BiomedGPT, require fine-tuned checkpoints for different tasks, highlighting a need for more inclusive and versatile solutions in medical AI.
Researchers from MBZUAI, Linköping University, STMC, Tawam Hospital, SSMC, and Govt Medical College Kozhikode have developed BiMediX2, a bilingual (Arabic-English) Bio-Medical Expert LMM built on the Llama3.1 architecture. This advanced model integrates text and visual modalities to support medical image understanding and various medical applications. BiMediX2 is trained on a robust bilingual dataset, BiMed-V, comprising 1.6 million text and image-based medical interactions in Arabic and English. It enables seamless multi-turn conversations and advanced medical image analysis, covering diverse modalities such as chest X-rays, CT scans, MRIs, histology slides, and gross pathology. Additionally, BiMediX2 introduces a novel bilingual GPT-4o-based benchmark, BiMed-MBench, with 286 expert-verified queries across multiple imaging tasks in English and Arabic.
BiMediX2 achieves state-of-the-art performance across several evaluation benchmarks, surpassing recent models like LLaVa-Med, MiniGPT-Med, and BiomedGPT in text-based and multimodal tasks. It demonstrates significant improvements in English evaluations (over 9%) and Arabic evaluations (over 20%), addressing critical gaps in healthcare AI for non-English-speaking populations. The model excels in Visual Question Answering, Report Generation, and Report Summarization tasks, setting new standards in bilingual medical applications. Notably, it outperforms GPT-4 by over 8% on the USMLE benchmark and by more than 9% in UPHILL factual accuracy evaluations, establishing itself as a comprehensive solution for multilingual, multimodal healthcare challenges.
BiMediX2 is a bilingual, multimodal AI model tailored for medical image analysis and conversations. Its architecture integrates a Vision Encoder to process diverse medical imaging modalities and a Projector to align visual data with text inputs tokenized for Llama 3.1. The model is fine-tuned using LoRA adapters and a bilingual dataset, BiMed-V, featuring 1.6M multimodal samples, including 163k Arabic translations verified by medical experts. Training occurs in two stages: aligning visual and language embeddings and refining multimodal instruction responses. BiMediX2 generates accurate, bilingual medical insights across radiology, pathology, and clinical Q&A domains.
BiMediX2 70B consistently outperforms competing models across diverse medical benchmarks, achieving the highest scores on Medical MMLU, MedMCQA, and PubMedQA with an average of 84.6%. It excels in UPHILL OpenQA, attaining 60.6% accuracy, highlighting its ability to address misinformation in medical contexts. On the Medical VQA benchmark, BiMediX2 8B leads with an average score of 0.611, showcasing its strength in visual question answering. The top scores for report summarization (0.416) and report generation (0.235) were also achieved using the MIMIC datasets. BiMediX2 effectively analyzes complex medical images across specialties and languages and demonstrates strong multilingual and multimodal capabilities.
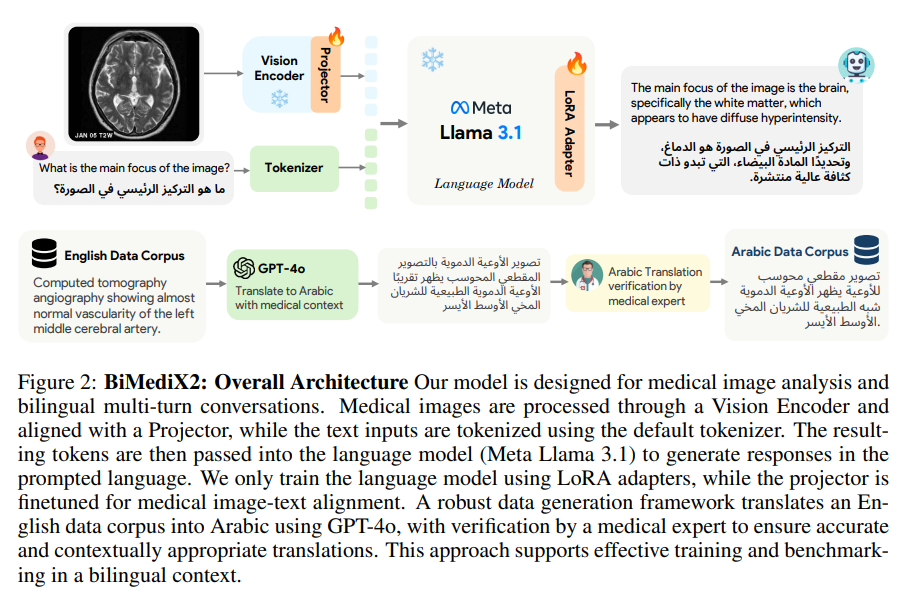
In conclusion, BiMediX2 is a bilingual (Arabic-English) biomedical LMM designed for advanced medical applications by integrating text and visual modalities. Built on the Llama3.1 architecture, it enables interactive, multi-turn conversations for tasks like medical image analysis and report generation. Trained on a bilingual dataset of 1.6 million samples, BiMediX2 achieves state-of-the-art performance across text-based and image-based medical benchmarks, including BiMed-MBench, a GPT-4o-based evaluation framework. It outperforms existing models in multimodal medical tasks, improving Arabic evaluations by over 20% and English evaluations by 9%. BiMediX2 significantly enhances accessibility to multilingual, AI-driven healthcare solutions.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. Don’t Forget to join our 60k+ ML SubReddit.
Sana Hassan, a consulting intern at Marktechpost and dual-degree student at IIT Madras, is passionate about applying technology and AI to address real-world challenges. With a keen interest in solving practical problems, he brings a fresh perspective to the intersection of AI and real-life solutions.
