

Efficient optimization of large-scale deep learning models remains a significant challenge as the cost of training large language models (LLMs) continues to escalate. As models grow larger, the computational burden and time required for training increase substantially, creating a demand for more efficient optimizers that can reduce both training time and resources. This challenge is particularly important for reducing the overhead in real-world AI applications and making large-scale model training more feasible.
Current optimization methods include first-order optimizers like Adam and second-order methods like Shampoo. While Adam is widely used for its computational efficiency, it often converges more slowly, especially in large-batch regimes. In contrast, Shampoo offers superior performance by using layer-wise Kronecker-factored preconditioners but suffers from high computational complexity, as it requires frequent eigendecomposition and introduces several additional hyperparameters. This limits Shampoo’s scalability and efficiency, particularly in large-scale and real-time applications.
The researchers from Harvard University propose SOAP (ShampoO with Adam in the Preconditioner’s eigenbasis) to overcome Shampoo’s limitations. SOAP integrates the strengths of Adam and Shampoo by running Adam on the eigenbasis of Shampoo’s preconditioners, thereby reducing computational overhead. This approach minimizes the need for frequent matrix operations and reduces the number of hyperparameters, with SOAP introducing only one additional hyperparameter—preconditioning frequency—compared to Adam. This novel method improves both training efficiency and performance without compromising on accuracy.

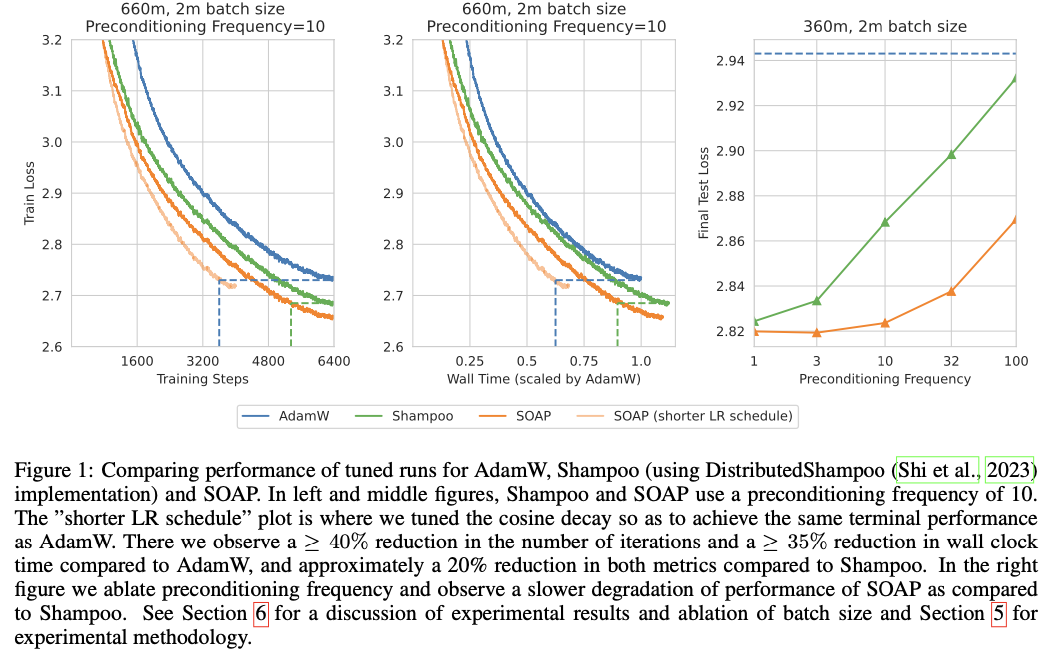
SOAP modifies the traditional Shampoo optimizer by updating preconditioners less frequently and running Adam’s updates in a rotated space defined by Shampoo’s preconditioners. It maintains two preconditioners for each layer’s weight matrix and updates these based on an optimized preconditioning frequency. In the experimental setup, SOAP was tested on models with 360M and 660M parameters in large-batch training tasks. The preconditioning frequency and other hyperparameters were optimized to ensure SOAP maximized both performance and efficiency, maintaining high accuracy while significantly reducing computational overhead.


SOAP demonstrated substantial improvements in performance and efficiency, reducing training iterations by 40% and wall-clock time by 35% compared to AdamW. Additionally, it achieved 20% better performance than Shampoo in both metrics. These improvements were consistent across different model sizes, with SOAP maintaining or exceeding the test loss scores of both AdamW and Shampoo. This highlights SOAP’s ability to balance training efficiency with model performance, making it a powerful tool for large-scale deep learning optimization.

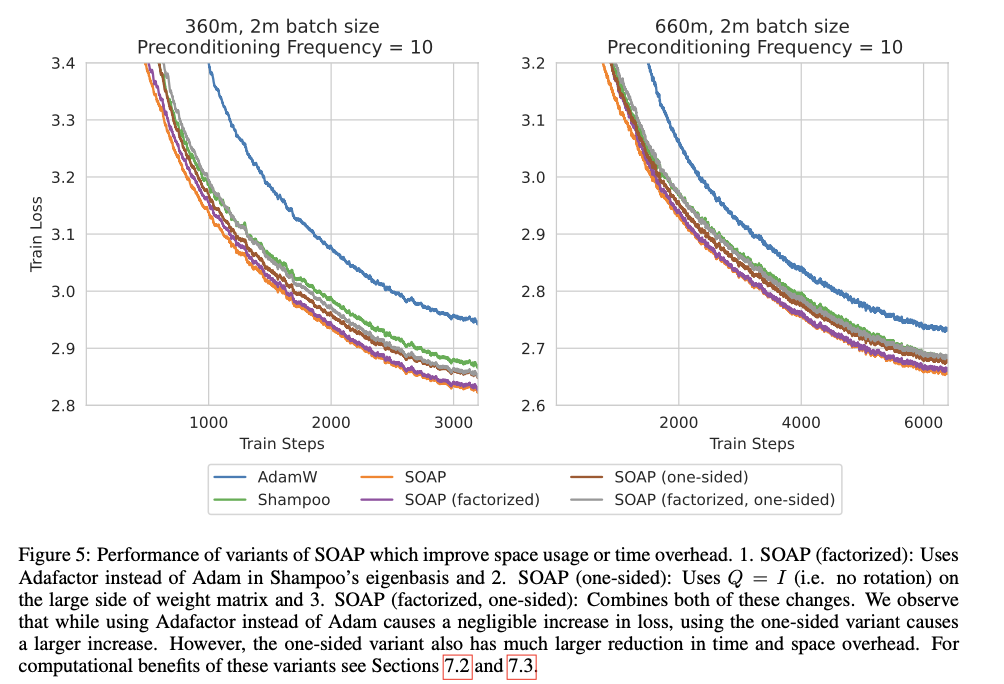
In conclusion, SOAP presents a significant advancement in deep learning optimization by combining the computational efficiency of Adam with the second-order benefits of Shampoo. By reducing computational overhead and minimizing hyperparameter complexity, SOAP offers a highly scalable and efficient solution for training large models. The method’s ability to reduce both training iterations and wall-clock time without sacrificing performance underscores its potential to become a practical standard in optimizing large-scale AI models, contributing to more efficient and feasible deep-learning training.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 50k+ ML SubReddit


Aswin AK is a consulting intern at MarkTechPost. He is pursuing his Dual Degree at the Indian Institute of Technology, Kharagpur. He is passionate about data science and machine learning, bringing a strong academic background and hands-on experience in solving real-life cross-domain challenges.