Understanding how LLMs comprehend natural language plans, such as instructions and recipes, is crucial for their dependable use in decision-making systems. A critical aspect of plans is their temporal sequencing, which reflects the causal relationships between steps. Planning, integral to decision-making processes, has been extensively studied across domains like robotics and embodied environments. Effective utilization, revision, or customization of plans necessitates the ability to reason about the steps involved and their causal connections. While evaluation in domains like Blocksworld and simulated environments is common, real-world natural language plans pose unique challenges due to their inability to be physically executed for testing correctness and reliability.
Researchers from Stony Brook University, the US Naval Academy, and the University of Texas at Austin have developed CAT-BENCH, a benchmark to evaluate advanced language models’ ability to predict the sequence of steps in cooking recipes. Their study reveals that current state-of-the-art language models need help with this task, even with techniques like few-shot learning and explanation-based prompting, achieving low F1 scores. While these models can generate coherent plans, the research emphasizes significant challenges in comprehending causal and temporal relationships within instructional texts. Evaluations indicate that prompting models to explain their predictions after generating them improves performance compared to traditional chain-of-thought prompting, highlighting inconsistencies in model reasoning.
Early research emphasized understanding plans and goals. Generating plans involves temporal reasoning and tracking entity states. NaturalPlan focuses on a few real-world tasks that involve natural language interaction. PlanBench demonstrated challenges in developing effective plans under strict syntax—goal-oriented Script Construction task models to produce step sequences for specific goals. ChattyChef uses conversational settings to refine step ordering. CoPlan revises steps to meet constraints. Studies like entity states, action linking, and next-event prediction explore plan understanding. Various datasets address dependencies in instructions and decision branching. However, more datasets need to focus on predicting and explaining temporal order constraints in instructional plans.
CAT-BENCH evaluates models’ ability to recognize temporal dependencies between steps in cooking recipes. Based on causal relationships within the recipe’s directed acyclic graph (DAG), it poses questions about whether one step must occur before or after another. For instance, determining if placing dough on a baking tray must precede removing a baked cake for cooling relies on understanding preconditions and step effects. CAT-BENCH contains 2,840 questions across 57 recipes, evenly split between questions testing “before” and “after” temporal relations. Models are evaluated on their precision, recall, and F1 score for predicting these dependencies, alongside their ability to provide valid explanations for their judgments.
Various models were evaluated on CAT-BENCH for their performance in predicting step dependencies. In the zero-shot setting, GPT-4-turbo and GPT-3.5-turbo showed the highest F1 scores, with GPT-4o performing unexpectedly worse. Adding explanations alongside answers generally improved model performance, notably enhancing GPT-4o’s F1 score significantly. However, models were biased toward predicting dependence, impacting their overall precision and recall balance. Human evaluation of model-generated explanations indicated varied quality, with larger models generally outperforming smaller ones. Models needed consistency in predicting step order, particularly when explanations were added. Further analysis revealed common errors like misunderstanding multi-hop dependencies and failing to identify causal relationships between steps.
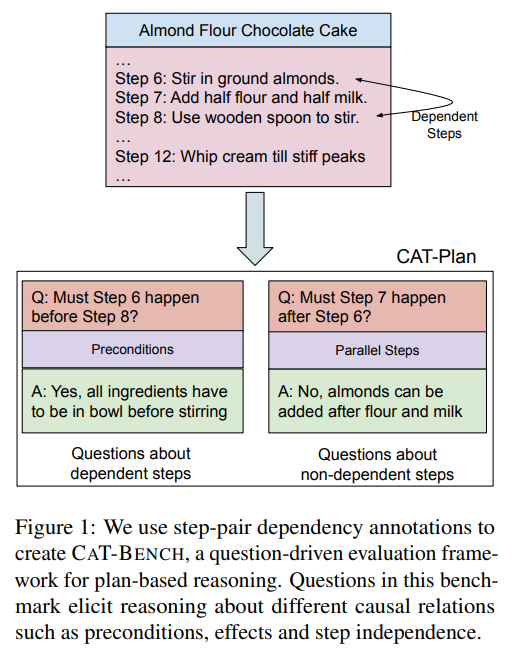
CAT-BENCH introduces a new benchmark for evaluating the causal and temporal reasoning abilities of language models in understanding procedural texts like cooking recipes. Despite advancements in state-of-the-art models (LLMs), none accurately determine whether one step in a plan must precede or succeed another, particularly in recognizing non-dependencies. Models also exhibit inconsistency in their predictions. Prompting LLMs to provide an answer followed by an explanation improves their performance significantly compared to reasoning followed by answering. However, human evaluation of these explanations reveals substantial room for improvement in the models’ understanding of step dependencies. These findings underscore current limitations in LLMs for plan-based reasoning applications.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter.
Join our Telegram Channel and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 45k+ ML SubReddit
Sana Hassan, a consulting intern at Marktechpost and dual-degree student at IIT Madras, is passionate about applying technology and AI to address real-world challenges. With a keen interest in solving practical problems, he brings a fresh perspective to the intersection of AI and real-life solutions.
