
Artificial Intelligence (AI) continues to evolve rapidly, but with that evolution comes a host of technical challenges that need to be overcome for the technology to truly flourish. One of the most pressing challenges today lies in inference performance. Large language models (LLMs), such as those used in GPT-based applications, demand a high volume of computational resources. The bottleneck occurs during inference—the stage where trained models generate responses or predictions. This stage often faces constraints due to the limitations of current hardware solutions, making the process slow, energy-intensive, and cost-prohibitive. As models become larger, traditional GPU-based solutions are increasingly falling short in terms of both speed and efficiency, limiting the transformative potential of AI in real-time applications. This situation creates a need for faster, more efficient solutions to keep pace with the demands of modern AI workloads.
Cerebras Systems Inference Gets 3x Faster! Llama 3.1-70B at 2,100 Tokens per Second


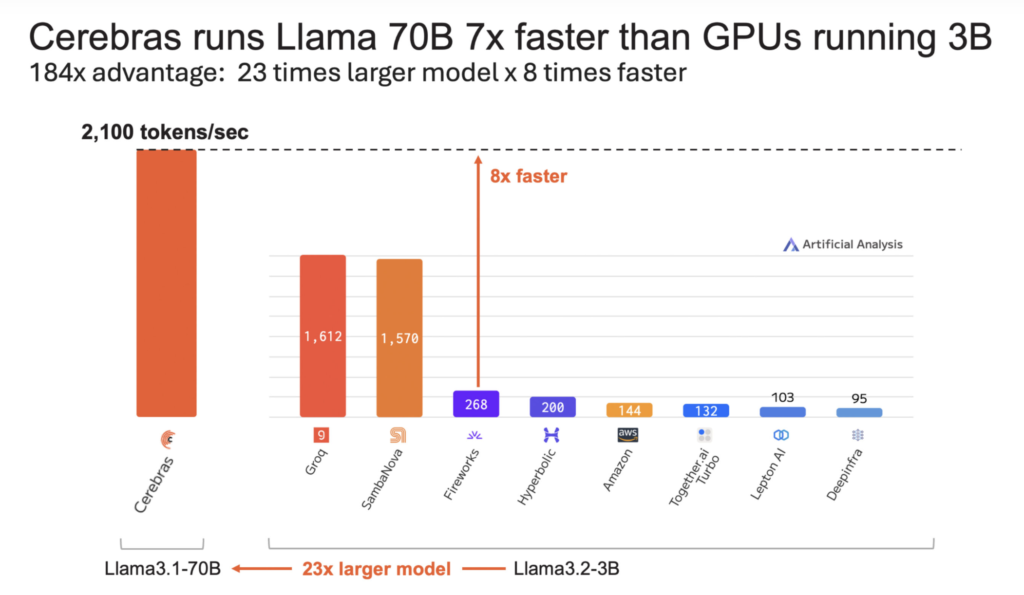
Cerebras Systems has made a significant breakthrough, claiming that its inference process is now three times faster than before. Specifically, the company has achieved a staggering 2,100 tokens per second with the Llama 3.1-70B model. This means that Cerebras Systems is now 16 times faster than the fastest GPU solution currently available. This kind of performance leap is akin to an entire generation upgrade in GPU technology, like moving from the NVIDIA A100 to the H100, but all accomplished through a software update. Moreover, it is not just larger models that benefit from this increase—Cerebras is delivering 8 times the speed of GPUs running the much smaller Llama 3.1-3B, which is 23 times smaller in scale. Such impressive gains underscore the promise that Cerebras brings to the field, making high-speed, efficient inference available at an unprecedented rate.
Technical Improvements and Benefits
The technical innovations behind Cerebras’ latest leap in performance include several under-the-hood optimizations that fundamentally enhance the inference process. Critical kernels such as matrix multiplication (MatMul), reduce/broadcast, and element-wise operations have been entirely rewritten and optimized for speed. Cerebras has also implemented asynchronous wafer I/O computation, which allows for overlapping data communication and computation, ensuring the maximum utilization of available resources. In addition, advanced speculative decoding has been introduced, effectively reducing latency without sacrificing the quality of generated tokens. Another key aspect of this improvement is that Cerebras maintained 16-bit precision for the original model weights, ensuring that this boost in speed does not compromise model accuracy. All of these optimizations have been verified through meticulous artificial analysis to guarantee they do not degrade the output quality, making Cerebras’ system not only faster but also trustworthy for enterprise-grade applications.
Transformative Potential and Real-World Applications
The implications of this performance boost are far-reaching, especially when considering the practical applications of LLMs in sectors like healthcare, entertainment, and real-time communication. GSK, a pharmaceutical giant, has highlighted how Cerebras’ improved inference speed is fundamentally transforming their drug discovery process. According to Kim Branson, SVP of AI/ML at GSK, Cerebras’ advances in AI are enabling intelligent research agents to work faster and more effectively, providing a critical edge in the competitive field of medical research. Similarly, LiveKit—a platform that powers ChatGPT’s voice mode—has seen a drastic improvement in performance. Russ d’Sa, CEO of LiveKit, remarked that what used to be the slowest step in their AI pipeline has now become the fastest. This transformation is enabling instantaneous voice and video processing capabilities, opening new doors for advanced reasoning, real-time intelligent applications, and enabling up to 10 times more reasoning steps without increasing latency. The data shows that the improvements are not just theoretical; they are actively reshaping workflows and reducing operational bottlenecks across industries.
Conclusion
Cerebras Systems has once again proven its dedication to pushing the boundaries of AI inference technology. With a threefold increase in inference speed and the ability to process 2,100 tokens per second with the Llama 3.1-70B model, Cerebras is setting a new benchmark for what’s possible in AI hardware. By focusing on both software and hardware optimizations, Cerebras is helping AI transcend the limits of what was previously achievable—not only in speed but also in efficiency and scalability. This latest leap means more real-time, intelligent applications, more robust AI reasoning, and a smoother, more interactive user experience. As we move forward, these kinds of advancements are critical in ensuring that AI remains a transformative force across industries. With Cerebras leading the charge, the future of AI inference looks faster, smarter, and more promising than ever.
Check out the Details. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 55k+ ML SubReddit.
[AI Magazine/Report] Read Our Latest Report on ‘SMALL LANGUAGE MODELS‘


Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is committed to harnessing the potential of Artificial Intelligence for social good. His most recent endeavor is the launch of an Artificial Intelligence Media Platform, Marktechpost, which stands out for its in-depth coverage of machine learning and deep learning news that is both technically sound and easily understandable by a wide audience. The platform boasts of over 2 million monthly views, illustrating its popularity among audiences.