

Mathematical formula recognition has progressed significantly, driven by deep learning techniques and the Transformer architecture. Traditional OCR methods prove insufficient due to the complex structures of mathematical expressions, requiring models to understand spatial and structural relationships. The field faces challenges in representational diversity, as formulas can have multiple valid representations. Recent advancements, including commercial tools like Mathpix and models such as UniMERNet, demonstrate the potential of deep learning in real-world applications.
Despite these advancements, current evaluation metrics for formula recognition exhibit significant limitations. Commonly used metrics like BLEU and Edit Distance focus primarily on text-based character matching, failing to accurately reflect recognition quality due to diverse formula representations. This leads to low reliability, unfair model comparisons, and a lack of intuitive scoring. The need for improved evaluation methods that account for the unique challenges of formula recognition has become evident, prompting the development of new approaches, such as the Character Detection Matching (CDM) metric proposed.
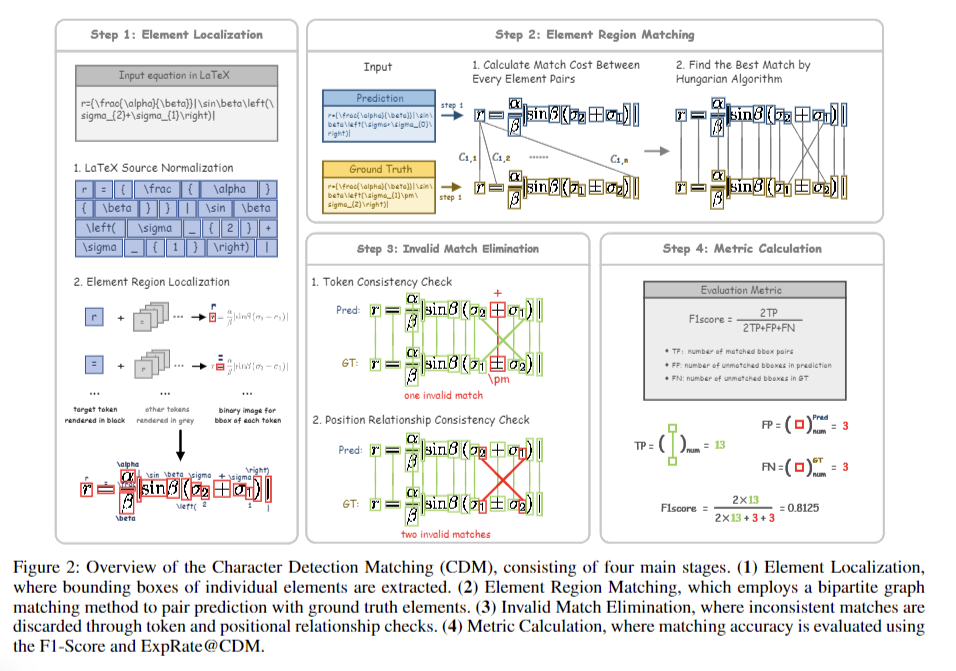
Mathematical formula recognition faces unique challenges due to complex structures and varied notations. Despite advancements in recognition models, existing evaluation metrics like BLEU and Edit Distance exhibit limitations in handling diverse formula representations. This paper introduces CDM, a novel evaluation metric that treats formula recognition as an image-based object detection task. CDM renders predicted and ground-truth LaTeX formulas into images, employing visual feature extraction and localization for precise character-level matching. This spatially-aware approach offers more accurate and equitable evaluation, aligning closely with human standards and providing fairer model comparisons. CDM addresses the need for improved evaluation methods in formula recognition, enhancing objectivity and reliability in assessment.


Researchers from Shanghai AI Laboratory and Shanghai Jiao Tong University developed a comprehensive methodology for evaluating formula recognition. Their approach begins with converting PDF pages to images for model input, followed by formula extraction using tailored regular expressions. The process compiles recognized formulas into text files for each PDF, facilitating subsequent matching. The methodology employs extraction algorithms to identify displayed formulas from model outputs, which are then matched against ground truth formulas. This systematic approach enables the computation of evaluation metrics, including BLEU and the newly introduced CDM metric.
Extensive experiments were conducted to validate the effectiveness of the CDM metric. Results from the Tiny-Doc-Math evaluation demonstrated CDM’s reliability in 96% of cases, with the remaining discrepancies attributed to LaTeX issues. The experimentation critically analyzed existing image-based evaluation methods, illustrating specific cases where traditional metrics fail to accurately reflect recognition errors. Comprehensive testing across various mainstream models and datasets highlighted CDM’s superiority in providing fair and intuitive assessments of formula recognition performance. This extensive validation positions CDM as a promising alternative for future research and improvements in the field.

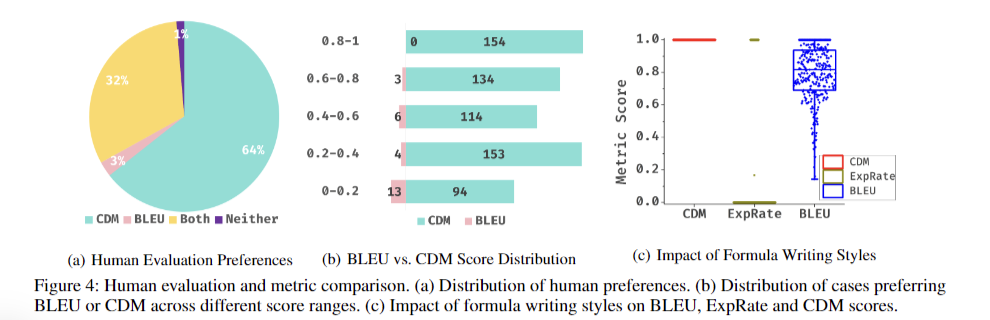
The Tiny-Doc-Math evaluation revealed users preferred the CDM score over BLEU in 64% of cases, reflecting CDM’s superior accuracy in assessing prediction quality. Analysis of user preferences showed CDM excelled when predictions were entirely correct but BLEU scores were unexpectedly low. Both metrics performed equally well in 32% of cases, while BLEU outperformed CDM in 3% of instances where token representation inconsistencies were detected. Experiments demonstrated satisfactory model performance with just 10% of training data, suggesting potential redundancy in the full dataset. Hard case selection identified an additional 9,734 samples, improving model performance to levels comparable with full dataset training.
Traditional metrics like BLEU and Edit Distance exhibited significant limitations, particularly with domain gaps between training and testing data distributions. These metrics struggled with the non-unique nature of LaTeX representations for formulas, complicating accurate evaluation. In contrast, CDM demonstrated enhanced reliability and effectiveness in providing fair assessments of model performance across various scenarios. The results underscore CDM’s potential to significantly improve formula recognition evaluation, addressing the shortcomings of existing metrics and offering a more robust approach to assessing model accuracy in diverse contexts.

In conclusion, the CDM metric addresses the critical limitations of traditional evaluation methods in formula recognition. By converting predicted and ground-truth LaTeX formulas into images for character-level matching, CDM offers a more reliable and objective assessment that incorporates spatial information. Experimental results demonstrate CDM’s superior alignment with human evaluations compared to BLEU and Edit Distance, providing fairer comparisons across models and effectively capturing nuances in formula rendering. The research advocates for CDM’s adoption as a standard metric in formula recognition, potentially driving advancements in model development. CDM’s ability to eliminate discrepancies caused by diverse formula representations marks a significant step toward more accurate and equitable evaluation in this field.
Check out the Paper and GitHub. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group.
📨 If you like our work, you will love our Newsletter..
Don’t Forget to join our 50k+ ML SubReddit


Shoaib Nazir is a consulting intern at MarktechPost and has completed his M.Tech dual degree from the Indian Institute of Technology (IIT), Kharagpur. With a strong passion for Data Science, he is particularly interested in the diverse applications of artificial intelligence across various domains. Shoaib is driven by a desire to explore the latest technological advancements and their practical implications in everyday life. His enthusiasm for innovation and real-world problem-solving fuels his continuous learning and contribution to the field of AI