The advent of large language models (LLMs) has ushered in a new era in computational linguistics, significantly extending the frontier beyond traditional natural language processing to encompass a broad spectrum of general tasks. Through their deep understanding and generation capabilities, these models can revolutionize various industries by automating and enhancing tasks previously thought to be exclusively within the human domain. Despite these advancements, a critical challenge remains: accurately evaluating these models in a manner that reflects real-world usage and aligns with human preferences.
LLM evaluation methods often rely on static benchmarks, utilizing fixed datasets to measure performance against a predetermined ground truth. While practical for ensuring consistency and reproducibility, these methods fail to capture real-world applications’ dynamic nature. They need to account for the nuanced and interactive aspects of language use in everyday scenarios, leading to a gap between benchmark performance and practical utility. This gap underscores the necessity for a more adaptive and human-centric approach to evaluation.
The researchers from UC Berkeley, Stanford, and UCSD introduced Chatbot Arena, a transformative platform that redefines the evaluation of LLMs by placing human preferences at its core. Unlike conventional benchmarks, Chatbot Arena takes a dynamic approach, inviting users from diverse backgrounds to interact with different models through a structured interface. Users pose a variety of questions or prompts to which models respond. These responses are then compared side-by-side, with users voting for the one that best aligns with their expectations. This process ensures a broad spectrum of query types reflecting real-world use and places human judgment at the heart of model evaluation.
Chatbot Arena’s methodology stands out for its pairwise comparisons and crowdsourcing use to gather extensive data reflecting real-world applications. Over several months, the platform has amassed more than 240,000 votes, offering a rich dataset for analysis. By applying sophisticated statistical methods, the platform efficiently and accurately ranks models based on their performance, addressing the diversity of human queries and the nuanced preferences that characterize human evaluations. This approach offers a more relevant and dynamic assessment of LLM capabilities and facilitates a deeper understanding of how different models perform across various tasks.
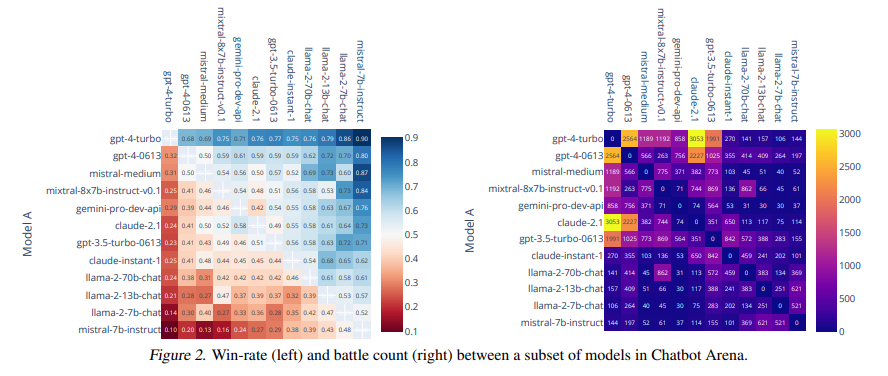
Chatbot Arena’s extensive data analysis meticulously examines crowdsourced questions and user votes, and the research confirms the diversity and discriminative power of the collected data. This analysis also reveals a significant correlation between crowdsourced human evaluations and expert judgments, establishing Chatbot Arena as a trusted and referenceable tool in the LLM community. The platform’s widespread adoption and citation by leading LLM developers and companies underscore its unique value and contribution to the field.
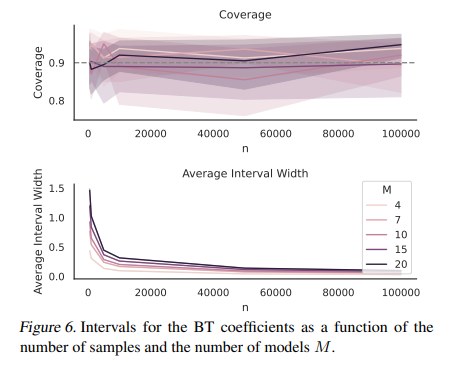
In conclusion, the contributions and findings presented underscore the significance of Chatbot Arena as a pioneering platform for LLM evaluation:
- Chatbot Arena introduces a novel, human-centric approach to evaluating LLMs, bridging the gap between static benchmarks and real-world applicability.
- The platform captures diverse user queries through its dynamic and interactive methodology, ensuring a broad and realistic assessment of model performance.
- The extensive data analysis confirms the platform’s ability to provide a nuanced evaluation of LLMs, highlighting the correlation between crowdsourced evaluations and expert judgments.
- The success and credibility of Chatbot Arena are further evidenced by its adoption and recognition within the LLM community, marking it as a key reference tool for model evaluation.
Check out the Paper and Project. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and Google News. Join our 38k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
You may also like our FREE AI Courses….
Hello, My name is Adnan Hassan. I am a consulting intern at Marktechpost and soon to be a management trainee at American Express. I am currently pursuing a dual degree at the Indian Institute of Technology, Kharagpur. I am passionate about technology and want to create new products that make a difference.
