Multimodal large language models (MLLMs) are increasingly applied in diverse fields such as medical image analysis, engineering diagnostics, and even education, where understanding diagrams, charts, and other visual data is essential. The complexity of these tasks requires MLLMs to seamlessly switch between different types of information while performing advanced reasoning.
The primary challenge researchers face in this area has been ensuring that AI models genuinely comprehend multimodal tasks rather than relying on simple statistical patterns to derive answers. Previous benchmarks for evaluating MLLMs allowed models to take shortcuts, sometimes arriving at correct answers by exploiting predictable question structures or correlations without understanding the visual content. This has raised concerns about the actual capabilities of these models in handling real-world multimodal problems effectively.
To address this issue, existing tools for testing AI models must be deemed insufficient. Current benchmarks failed to differentiate between models that used true multimodal understanding and those that relied on text-based patterns. As a result, the research team highlighted the need for a more robust evaluation system to test the depth of reasoning and understanding in multimodal contexts. These shortcomings indicated the necessity of a more challenging and rigorous approach to assessing MLLMs.
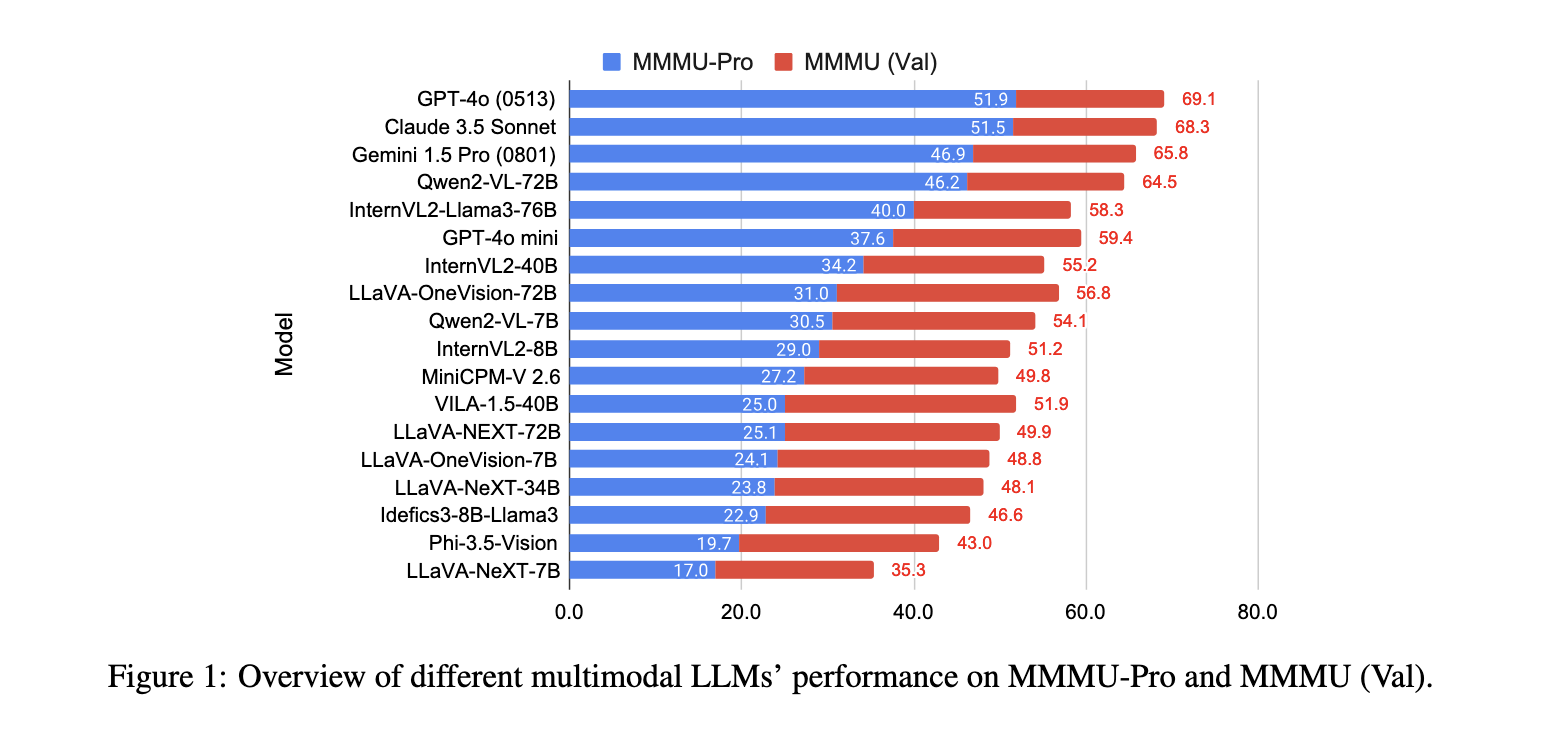
Researchers from Carnegie Mellon University and other institutions introduced a new benchmark called MMMU-Pro, specifically designed to push the limits of AI systems’ multimodal understanding. This improved benchmark targets the weaknesses in previous tests by filtering out questions solvable by text-only models and increasing the difficulty of multimodal questions. The benchmark was developed with leading companies, including OpenAI, Google, and Anthropic. It introduces features like vision-only input scenarios and multiple-choice questions with augmented options, making it significantly more challenging for models to exploit simple patterns for answers.
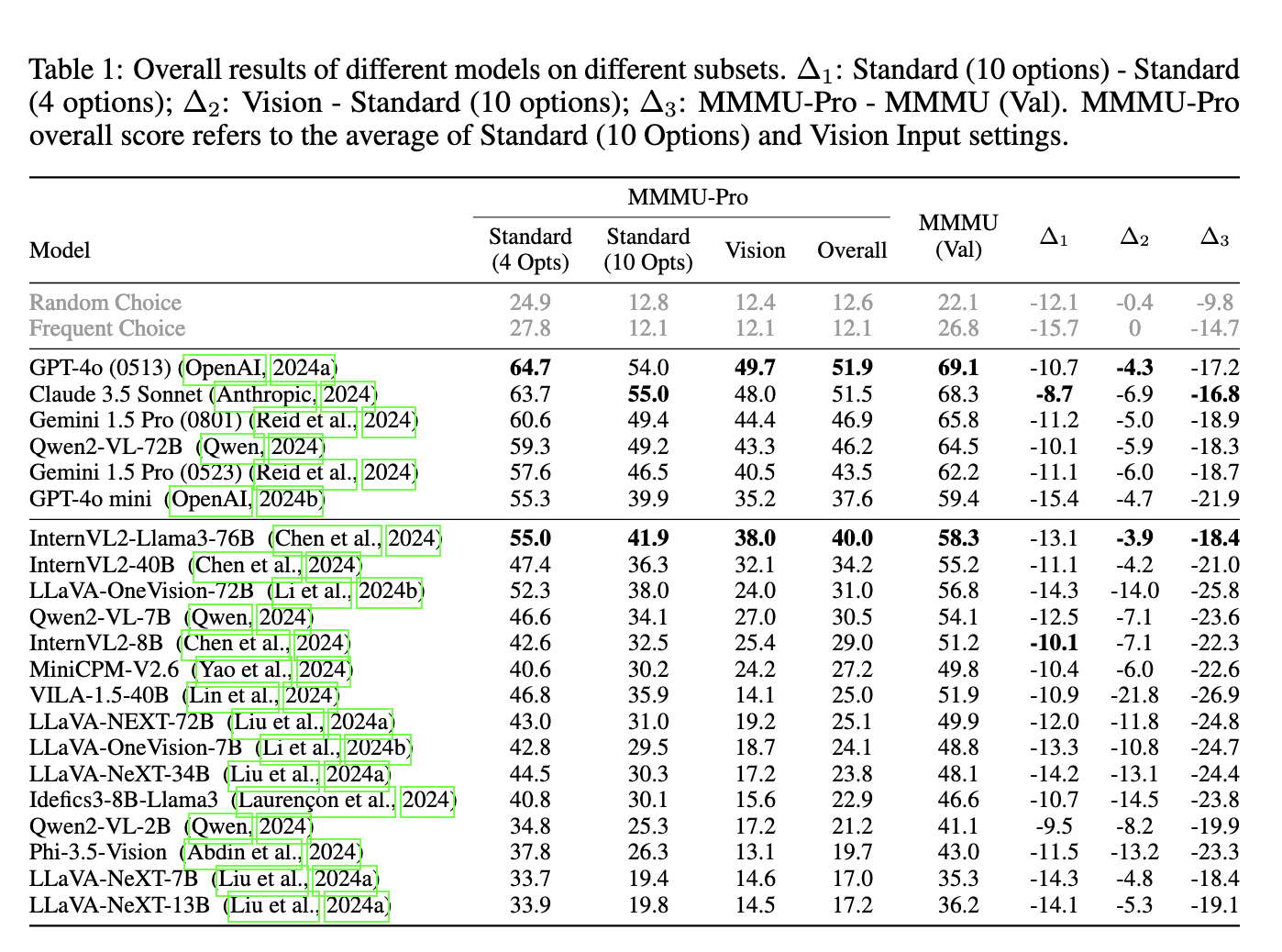
The methodology behind MMMU-Pro is thorough and multilayered. The benchmark’s construction involved three primary steps: first, researchers filtered out questions answerable by text-only models by utilizing multiple language models to test each question. Any question that could be consistently answered without visual input was removed. Second, they increased the number of answer options from four to ten in many questions, reducing the effectiveness of random guessing. Finally, they introduced a vision-only input setting, where models were presented with images or screenshots containing the question-and-answer options. This step is crucial as it mimics real-world situations where text and visual information are intertwined, challenging models to understand both modalities simultaneously.

In terms of performance, MMMU-Pro revealed the limitations of many state-of-the-art models. The average accuracy for models like GPT-4o, Claude 3.5 Sonnet, and Gemini 1.5 Pro dropped significantly when tested against this new benchmark. For example, GPT-4o saw a drop from 69.1% on the original MMMU benchmark to 54.0% on MMMU-Pro when evaluated using ten candidate options. Meanwhile, Claude 3.5 Sonnet, developed by Anthropic, experienced a performance reduction of 16.8%, while Gemini 1.5 Pro, from Google, saw a decrease of 18.9%. The most drastic decline was observed in VILA-1.5-40B, which experienced a 26.9% drop. These numbers underscore the benchmark’s ability to highlight the models’ deficiencies in true multimodal reasoning.
Chain of Thought (CoT) reasoning prompts were introduced as part of the evaluation to improve model performance by encouraging step-by-step reasoning. While this strategy showed some improvements, the extent of success varied across models. For instance, Claude 3.5 Sonnet’s accuracy increased to 55.0% with CoT, but models like LLaVA-OneVision-72B showed minimal improvements, and some models even faced performance drops. This highlights the complexity of MMMU-Pro and its challenges to current multimodal models.
The MMMU-Pro benchmark provides critical insights into multimodal AI model performance gaps. Despite advances in OCR (Optical Character Recognition) and CoT reasoning, the models still struggled with integrating text and visual elements meaningfully, particularly in vision-only settings where no explicit text was provided. This further emphasizes the need for improved AI systems to handle the full spectrum of multimodal challenges.
In conclusion, MMMU-Pro marks a significant advancement in evaluating multimodal AI systems. It successfully identifies the limitations in existing models, such as their reliance on statistical patterns, and presents a more realistic challenge for assessing true multimodal understanding. This benchmark opens new directions for future research, pushing the development of better-equipped models to integrate complex visual and textual data. The research team’s work represents an important step forward in the quest for AI systems capable of performing sophisticated reasoning in real-world applications.
Check out the Paper and Leaderboard. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and LinkedIn. Join our Telegram Channel.
If you like our work, you will love our newsletter..
Don’t Forget to join our 50k+ ML SubReddit
Nikhil is an intern consultant at Marktechpost. He is pursuing an integrated dual degree in Materials at the Indian Institute of Technology, Kharagpur. Nikhil is an AI/ML enthusiast who is always researching applications in fields like biomaterials and biomedical science. With a strong background in Material Science, he is exploring new advancements and creating opportunities to contribute.
