
Code Large Language Models (CodeLLMs) have predominantly focused on open-ended code generation tasks, often neglecting the critical aspect of code understanding and comprehension. Traditional evaluation methods might need to be updated and susceptible to data leakage, leading to unreliable assessments. Moreover, practical applications of CodeLLMs reveal limitations such as bias and hallucination.
To resolve these problems, a group of researchers from FPT Software AI Center, Vietnam, Hanoi University of Science and Technology, VNU-HCM- University of Science has proposed CodeMMLU, a comprehensive multiple-choice question-answer benchmark designed to evaluate the depth of software and code understanding in LLMs. Unlike traditional benchmarks, CodeMMLU assesses models’ ability to reason about code rather than merely generate it, providing deeper insights into their grasp of complex software concepts and systems. By underscoring the crucial relationship between code understanding and effective generation, CodeMMLU is a vital resource for advancing AI-assisted software development, aiming to create more reliable and capable coding assistants.
CodeMMLU offers a robust and easily evaluable methodology with two key features:
- Comprehensiveness: CodeMMLU comprises over 10,000 questions curated from many resources. CodeMMLU is not biased as the dataset is wide, and there is no scope for favoritism.
- Diversity in task, domain, and language: The dataset covers a wide spectrum of software knowledge, including general QA, code generation, defect detection, and code repair across domains and more than 10 programming languages.
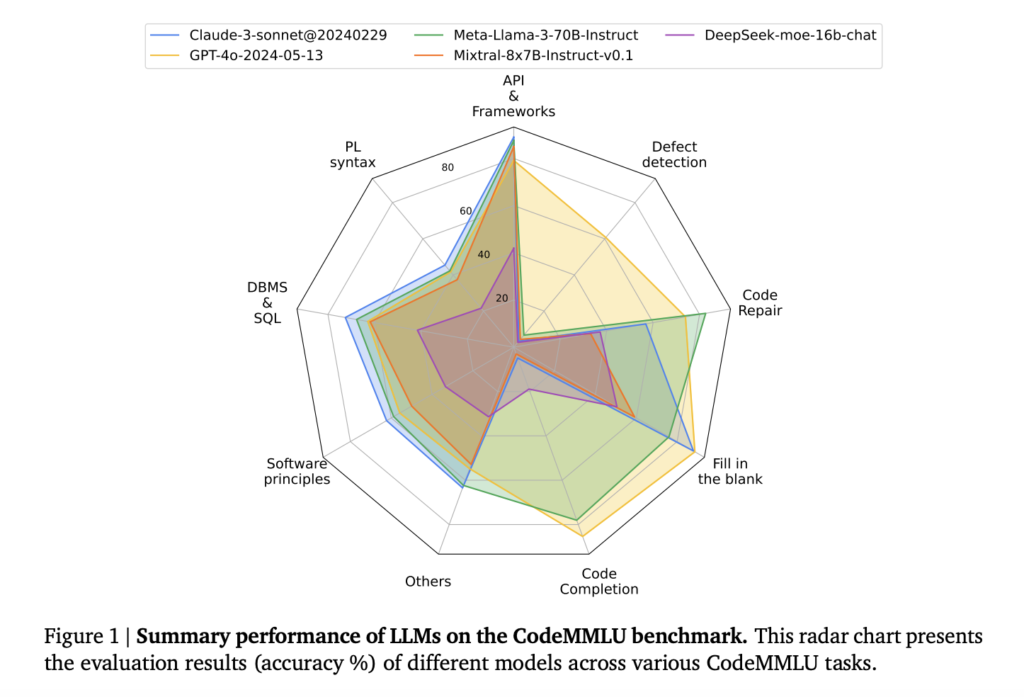
CodeMMLU highlights the impact of factors such as model size, model family, and prompting techniques. It provides essential information to the community on effectively utilizing LLMs for specific tasks and domains in software engineering.
It is divided into two primary categories. First are knowledge-based test sets containing syntactic and semantic tasks, and second are real-world programming problems. The knowledge-based subset covers many topics, from high-level software principles concepts to low-level programming language grammar. Several programming-related MCQs are collected from high-quality platforms, like GeeksforGeeks W3Schools.


It is further categorized into a Syntactic set, which focuses on programming language grammar like iteration format common library use. At the same time, the Semantic one is more targeted at algorithms, OOPS, and data structures. A deep learning model filters out low-quality or irrelevant questions, such as duplicates or trivial questions. The remaining questions were further refined using manual and deep learning methods.
The benchmark includes five multiple-choice question types that test essential coding skills: Code completion, Code repair, Defect Detection, and Fill in the blank.
Certain experiments revealed a strong correlation between performance on knowledge-based tasks and real-world coding challenges. Specifically, the Pearson correlation score r = 0.61 between model rankings on the knowledge test set and their performance on real-world problems, derived from the accuracy of 43 LLMs across 10 model families, indicated a moderate alignment and demonstrated that a deeper understanding of software principles consistently excel in real-world coding tasks. Also, The LLM accuracy fluctuates between different permutations ( Δ𝜎 = 36.66), demonstrating how sensitive it can be to the structure and order of answers.
In conclusion, CodeMMLUs strongly correlate software knowledge and real-world task performance. CodeMMLU provides more accurate and detailed rankings of LLMs, particularly in open-source models. Focusing on understanding rather than mere generation, gives a more nuanced and comprehensive assessment of model capabilities across a wide range of software knowledge and real-world programming tasks. However, there are limitations, such as the Multiple Choice Questions not being fully able to test the model’s ability to create code creatively. Also, the benchmark could still include more specialized areas of software development to assess the model’s versatility. In future work, the researchers plan to focus on adding more complex tasks and refining the balance between real-world scenarios and theoretical knowledge.


Check out the Paper and GitHub. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 50k+ ML SubReddit
[Upcoming Event- Oct 17 202] RetrieveX – The GenAI Data Retrieval Conference (Promoted)


Nazmi Syed is a consulting intern at MarktechPost and is pursuing a Bachelor of Science degree at the Indian Institute of Technology (IIT) Kharagpur. She has a deep passion for Data Science and actively explores the wide-ranging applications of artificial intelligence across various industries. Fascinated by technological advancements, Nazmi is committed to understanding and implementing cutting-edge innovations in real-world contexts.