Synthetic data generation is gaining prominence in the field of machine learning. This technique creates vast datasets when real-world data is limited and expensive. Researchers can train machine learning models more effectively by generating synthetic data, enhancing their performance across various applications. The generated data is crafted to exhibit specific characteristics beneficial for the models’ learning process.
However, integrating synthetic data into machine learning models presents several challenges, particularly regarding the biases and attributes the synthetic data may introduce. Understanding how these inherited characteristics impact the behavior and performance of large language models (LLMs) is crucial. The primary concern is whether the synthetic data can introduce unintended biases or other attributes that might affect the model’s outputs. This understanding is vital for ensuring that models trained with synthetic data are effective and fair, avoiding perpetuating negative traits from the data generation process.
Current methods for optimizing the data space involve data augmentation, pseudo-labeling, data weighting, data pruning, and curriculum learning. Data augmentation expands datasets by creating modified versions of existing data. Pseudo-labeling involves generating labels for unlabeled data, effectively expanding the dataset. Data weighting assigns different importance to various data points, and data pruning removes less useful data, enhancing the quality of the remaining dataset. Curriculum learning structures the training process by gradually introducing more complex data. Despite their utility, these methods are limited by the properties inherent in the initial datasets. They often need to be able to introduce new, desirable attributes, restricting their effectiveness in optimizing models for specific characteristics.
Researchers from Cohere for AI and Cohere have proposed a novel concept called “active inheritance.” This method aims to intentionally steer synthetic data generation towards specific non-differentiable objectives, such as high lexical diversity and low toxicity. By guiding the data generation process, researchers can directly influence the characteristics of the resulting models. Active inheritance involves selecting proxy labels based on desired characteristics, generating multiple samples for each prompt, and choosing the sample that maximizes the desired attribute. This approach, known as targeted sampling, allows for fine-tuning models towards specific goals using synthetic datasets curated to enhance these attributes.
The active inheritance method has shown significant promise. For instance, targeted sampling effectively steers model behavior towards desirable attributes, resulting in substantial improvements. Models demonstrated up to 116% improvement in length and 43% enhancement in linguistic diversity. Moreover, the method reduced toxicity by up to 40%. These results highlight the potential of active inheritance to enhance the quality and safety of language models. By focusing on specific characteristics, researchers can ensure that the models exhibit desirable traits while minimizing negative ones.

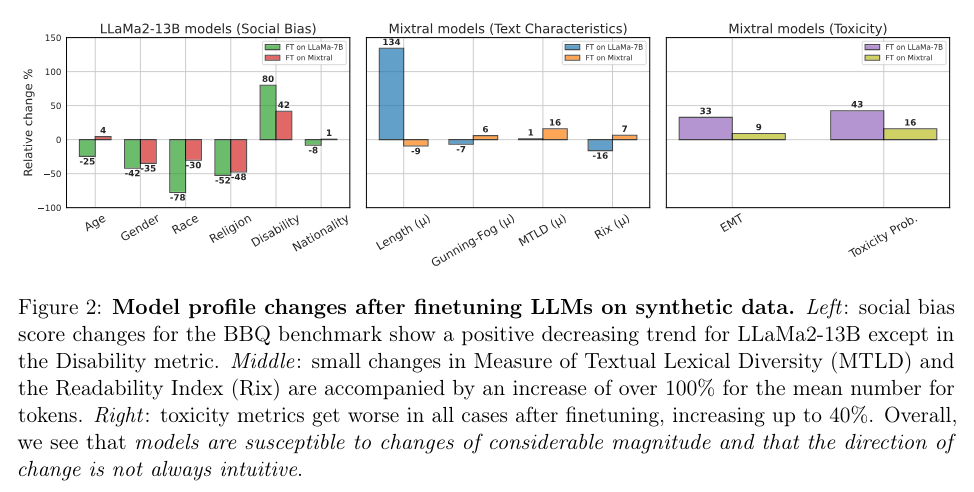
The study also examined how passive inheritance, where models inherit properties from the synthetic data without explicit guidance, impacts model performance. The research highlighted that models are sensitive to the properties of the artificial data they are trained on, even when the data prompts appear neutral. This sensitivity raises concerns about the potential for introducing unintended biases and attributes into the models. The findings underscore the importance of carefully curating synthetic data to avoid undesirable outcomes.

In conclusion, the research underscores the significant impact of synthetic data on the attributes of large language models. By introducing the concept of active inheritance, researchers from Cohere have provided a robust framework for steering synthetic data generation towards desirable characteristics. This method enhances specific attributes, such as lexical diversity and reduced toxicity, ensuring that models trained with synthetic data are effective and safe. The study’s results demonstrate that it is possible to successfully and efficiently instill desired attributes into a model’s generation with minimal effort. Active inheritance represents a promising approach to optimizing machine learning models, offering a pathway to more sophisticated and reliable AI systems.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter.
Join our Telegram Channel and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 46k+ ML SubReddit
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is committed to harnessing the potential of Artificial Intelligence for social good. His most recent endeavor is the launch of an Artificial Intelligence Media Platform, Marktechpost, which stands out for its in-depth coverage of machine learning and deep learning news that is both technically sound and easily understandable by a wide audience. The platform boasts of over 2 million monthly views, illustrating its popularity among audiences.
