
Large Language Models (LLMs) have gained significant attention due to their impressive performance, with the release of Llama 3.1 in July 2024 being a notable example. However, deploying these models in resource-constrained environments poses significant challenges due to their huge parameter count. Low-bit quantization has emerged as a popular technique to compress LLMs, reducing memory and computational demands during inference. Existing research on quantization algorithms has been limited in scope, focusing mainly on pre-trained models rather than the more widely used instruction-tuned models. Understanding the impact of using these quantization methods efficiently on accuracy across various datasets, model sizes, and training approaches is important.
Existing methods to address LLM quantization challenges include Quantization Aware Training (QAT) and Post-Training Quantization (PTQ), where QAT is difficult to apply, and hence PTQ is more widely adopted for LLMs despite potential accuracy reduction. Other methods include LLM.int8(), which uses 8-bit weights and activations, and GPTQ, a layer-wise quantization technique utilizing inverse Hessian information. For evaluating LLMs, aspects like weight and activation quantization in language modeling tasks, emergent abilities of quantized LLMs, and trustworthiness dimensions have been explored. However, most research depends heavily on accuracy as the primary evaluation metric, which has left gaps in understanding quantization impacts on crucial tasks like trustworthiness, dialogue, and long-context scenarios.
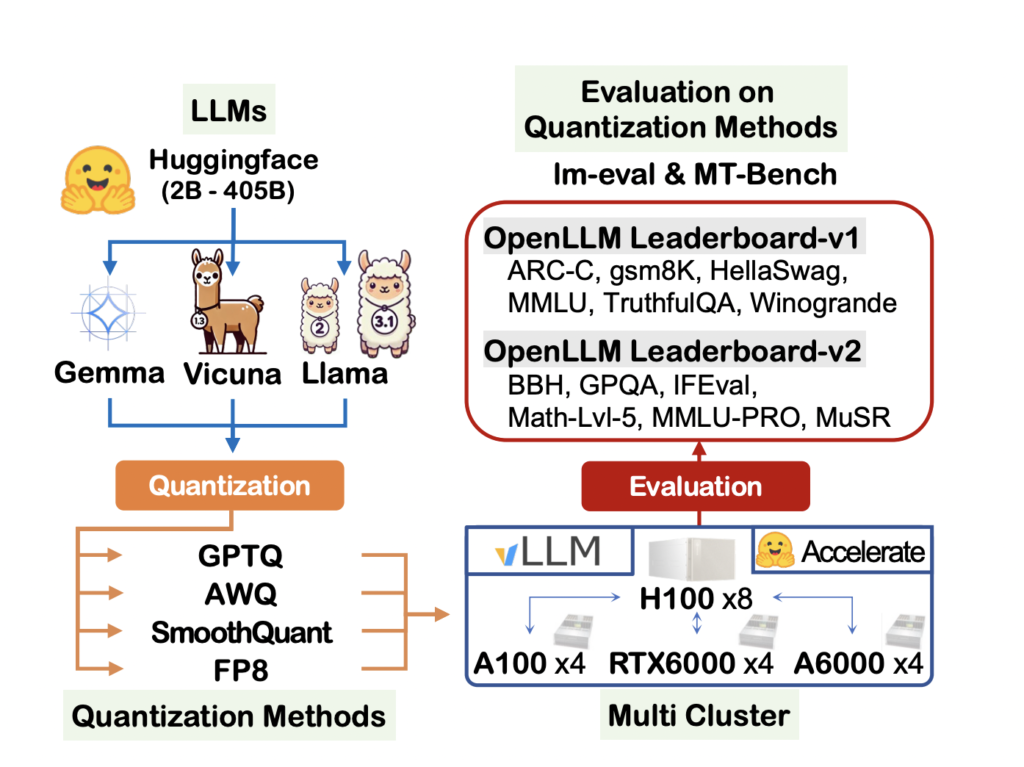
A team from ETRI, KETI, and Neubla have proposed a comprehensive evaluation of instruction-tuned LLMs across various quantization methods. Their study encompasses models ranging from 7B to 405B parameters, utilizing GPTQ, AWQ, SmoothQuant, and FP8 quantization techniques. This approach provides a detailed understanding of how different quantization methods affect LLM performance across diverse tasks and model sizes. It also addresses the limitations of previous studies by including the latest models and a wider range of parameters, offering insights into the effectiveness of quantization techniques on cutting-edge LLMs.
The study includes a comprehensive evaluation framework, utilizing 13 widely used datasets and benchmarks across 6 task types. For CommonSenseQA, datasets like ARC, HellaSwag, and Winogrande are used to evaluate the ability of AI to handle human-like reasoning and elementary knowledge. Moreover, activation quantization (SmoothQuant) and weight-only quantization methods like GPTQ and AWQ are implemented using tools like AutoGPTQ, llmcompressor, and AutoAWQ. GPTQ uses layer-wise quantization, and utilizes inverse Hessian information to mitigate accuracy loss, while AWQ is designed to preserve the precision of critical weights in LLMs. Both methods used a group size of 128 for quantization.
The experimental results show that the quantized larger LLMs generally outperform smaller models across most benchmarks, except for hallucination and instruction-following tasks. For example, a 4-bit quantized Llama-2-13B (6.5 GB) outperformed an FP16 Llama-2-7B (14 GB) on most benchmarks, with 4.66% and 1.16% higher accuracy on OpenLLM Leaderboard-v1 and v2 datasets, respectively. Further, the comparison of quantization methods showed little difference between weight-only (GPTQ and AWQ) and activation quantization (SmoothQuant) in most cases. However, SmoothQuant caused accuracy drops, up to -2.93% and -9.23% on average for large models like Llama3.1-405B compared to FP8 on OpenLLM Leaderboard-v1 and v2 datasets, respectively.


In this paper, a team from ETRI, KETI, and Neubla presented a comprehensive evaluation of instruction-tuned LLMs across various quantization methods across a wide range of 13 datasets and 6 task types. The paper covers models ranging from 7B to 405B parameters and uses four quantization methods: GPTQ, AWQ, SmoothQuant, and FP8. The findings revealed that quantized LLMs outperformed smaller models in most tasks, with notable exceptions in hallucination detection and instruction following. The weight-only (GPTQ and AWQ) quantization showed superior results in the 405B model. The study also highlighted the limitations of the MT-Bench evaluation method in differentiating between high-performing LLMs.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 50k+ ML SubReddit


Sana Hassan, a consulting intern at Marktechpost and dual-degree student at IIT Madras, is passionate about applying technology and AI to address real-world challenges. With a keen interest in solving practical problems, he brings a fresh perspective to the intersection of AI and real-life solutions.