One of the major hurdles in AI-driven image modeling is the inability to account for the diversity in image content complexity effectively. The tokenization methods so far used are static compression ratios where all images are treated equally, and the complexities of images are not considered. Due to this reason, complex images get over-compressed and lead to the loss of crucial information, while simple images remain under-compressed, wasting valuable computational resources. These inefficiencies hinder the performance of subsequent operations such as reconstruction and generation of images, in which accurate and efficient representation plays a critical role.
Current techniques for tokenizing images do not address the variation in complexity appropriately. Fixed ratio tokenization approaches resize images to standard sizes without considering the varying complexity of contents. Vision Transformers adapt patch size dynamically but rely on image input and do not have flexibility with text-to-image applications. Other compression techniques include JPEG, which is designed specifically for traditional media but lacks optimization for deep learning-based tokenization. Current work, ElasticTok, has offered random token length strategies but lacked consideration of the intrinsic content complexity during training time; this leads to inefficiencies regarding quality and the computational cost associated.
Researchers from Carnegie Mellon University and Meta propose Content-Adaptive Tokenization (CAT), a pioneering framework for content-aware image tokenization that introduces a dynamic approach by allocating representation capacity based on content complexity. This innovation enables large language models to test the complexity of images from captions and perception-based queries while classifying images into three compression levels: 8x, 16x, and 32x. In addition, it uses a nested VAE architecture that generates variable-length latent features by dynamically routing intermediate outputs based on the complexity of the images. The adaptive design reduces training overhead and optimizes image representation quality to overcome the inefficiencies of fixed-ratio methods. CAT enables adaptive and efficient tokenization using text-based complexity analysis without requiring image inputs at inference.
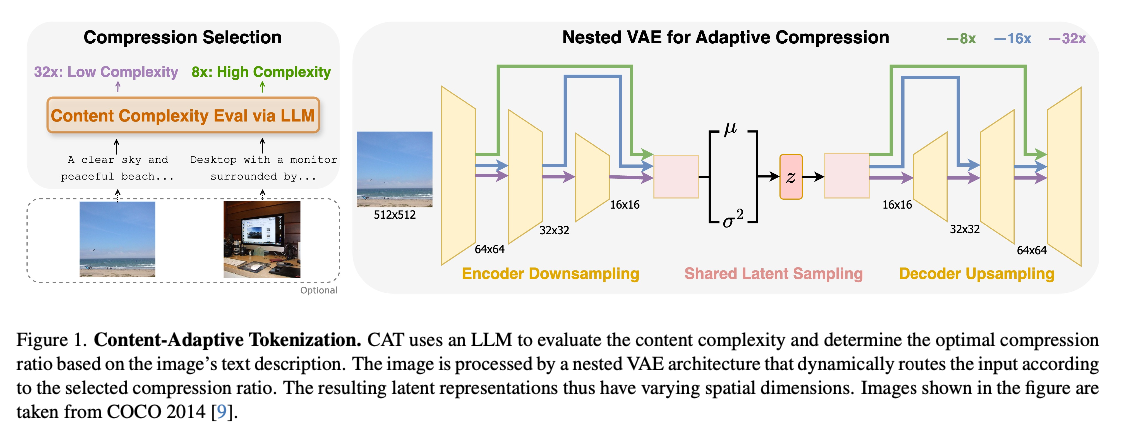
CAT evaluates complexity with captions produced from LLMs that consider both semantic, visual, and perceptual features while determining compression ratios. Such a caption-based system is seen to be greater than traditional methods, including JPEG size and MSE in its ability to mimic human perceived importance. This adaptive nested VAE design does so with the channel-matched skip connections dynamically altering latent space across various compression levels. Shared parameterization guarantees consistency across scales, while training is performed by a combination of reconstruction error, perceptual loss (for example, LPIPS), and adversarial loss to reach optimal performance. CAT was trained on a dataset of 380 million images and tested on the benchmarks of COCO, ImageNet, CelebA, and ChartQA, thus showing its applicability to different image types.

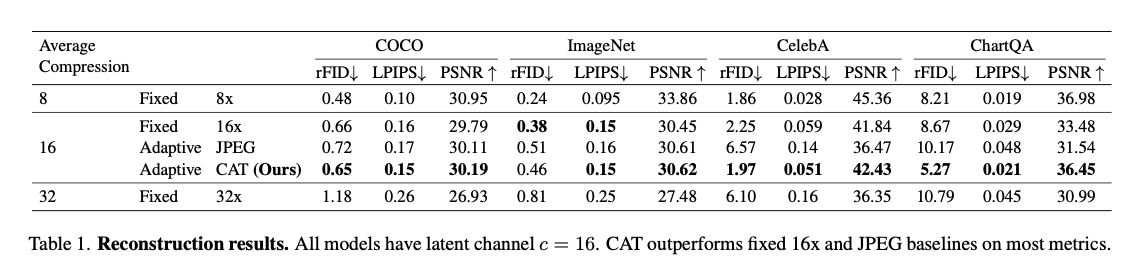
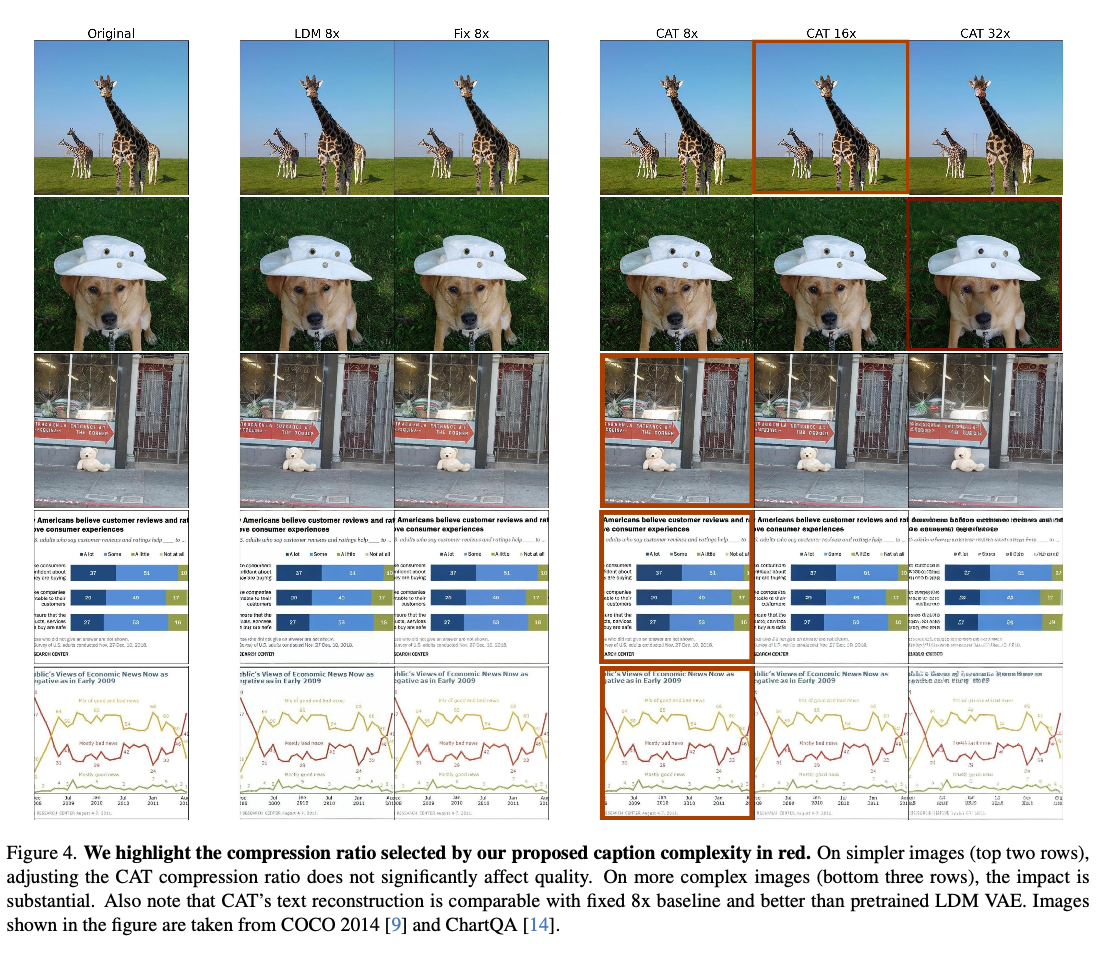
This achieves highly significant performance improvements over both image reconstruction and generation by adapting compression based on content complexity. For reconstruction tasks, it significantly improves the rFID, LPIPS, and PSNR metrics. It delivers 12% quality improvement for the reconstruction of CelebA and 39% enhancement for ChartQA, all while keeping the quality comparable to those of datasets such as COCO and ImageNet with fewer tokens and efficiency. For class-conditional ImageNet generation, CAT outperforms the fixed-ratio baselines with an FID of 4.56 and improves inference throughput by 18.5%. This adaptive tokenization framework is the new benchmark for further improvement.

CAT is a new approach to image tokenization by dynamically modulating compression levels based on the complexity of the content. It integrates LLM-based assessments with an adaptive nested VAE, eliminating persistent inefficiencies associated with fixed-ratio tokenization, thereby significantly improving performance in reconstruction and generation tasks. The adaptability and effectiveness of CAT make it a revolutionary asset in AI-oriented image modeling, with potential applications extending to video and multi-modal domains.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. Don’t Forget to join our 60k+ ML SubReddit.
🚨 FREE UPCOMING AI WEBINAR (JAN 15, 2025): Boost LLM Accuracy with Synthetic Data and Evaluation Intelligence–Join this webinar to gain actionable insights into boosting LLM model performance and accuracy while safeguarding data privacy.
Aswin AK is a consulting intern at MarkTechPost. He is pursuing his Dual Degree at the Indian Institute of Technology, Kharagpur. He is passionate about data science and machine learning, bringing a strong academic background and hands-on experience in solving real-life cross-domain challenges.
