Large language models (LLMs) have made significant success in various language tasks, but steering their outputs to meet specific properties remains a challenge. Researchers are attempting to solve the problem of controlling LLM generations to satisfy desired characteristics across a wide range of applications. This includes reinforcement learning from human feedback (RLHF), red-teaming techniques, reasoning tasks, and enforcing specific response properties. Current methodologies face challenges in effectively guiding model outputs while maintaining coherence and quality. The complexity lies in balancing the model’s learned knowledge with the need to generate responses that align with targeted attributes or constraints, necessitating innovative approaches to language model steering.
Prior attempts to solve language model steering challenges include diverse decoding methods, controlled generation techniques, and reinforcement learning-based approaches. Diverse decoding methods like best-of-K sampling aim to generate varied outputs, while controlled generation techniques such as PPLM and GeDi focus on guiding the model’s output towards specific attributes. Reinforcement learning methods, particularly those using Proximal Policy Optimization (PPO), have been employed to train models that balance between policy and value networks. Some researchers have explored Monte Carlo Tree Search (MCTS) techniques, either based on PPO value estimates or driven by discriminators, to improve decoding processes. However, these methods often lack a unified probabilistic framework and may not align perfectly with the desired target distribution, leaving room for more principled approaches to language model steering.
Researchers from the University of Toronto and Vector Institute utilize Twisted Sequential Monte Carlo (SMC), a powerful framework for probabilistic inference in language models. This approach addresses the challenge of sampling from non-causal target distributions by learning twist functions that modulate the base model to match target marginals. The method focuses language model generation on promising partial sequences, improving the quality and relevance of outputs. Twisted SMC not only enables effective sampling but also provides tools for evaluating inference techniques through log partition function estimates. This probabilistic perspective offers a unified approach to language model steering, bridging the gap between sampling, evaluation, and fine-tuning methods. By utilizing concepts from energy-based modeling and density ratio estimation, the framework introduces unique techniques like contrastive twist learning (CTL) and adapts existing twisted SMC methods to the language modeling context.

Twisted SMC in language models focuses on defining intermediate targets that align with the true marginals of the target distribution. Unlike traditional SMC methods that rely on per-token or few-step-ahead statistics, twisted SMC considers the full target information up to the terminal time T. This approach is particularly useful for target distributions determined by a terminal potential only. The key innovation lies in the introduction of twist functions ψt that modulate the base language model to approximate the target marginals at each intermediate step. These twist functions effectively summarize future information relevant to sampling at time t, enabling the method to generate partial sequences that are distributed according to the desired intermediate marginals. This approach allows for more accurate and efficient sampling from complex target distributions, improving the overall quality of language model outputs in tasks requiring specific terminal characteristics.
Twisted SMC introduces the concept of twist functions to represent intermediate target distributions in language model sampling. These twist functions ψt modulate the base model p0 to approximate the target marginals σ(s1:t) at each step. The method allows for flexibility in choosing proposal distributions, with options including the base model, a twist-induced proposal, or variational proposals.
A key innovation is the twist-induced proposal, which minimizes the variance of importance weights. This proposal is tractable to sample in transformer architectures for all but the final timestep, where an approximation is used. The resulting incremental weights are independent of the sampled token for all but the final step, enhancing efficiency.
The framework extends to conditional target distributions, accommodating scenarios where the generation is conditioned on an observation. This generalization allows for exact target sampling on simulated data using a technique called the Bidirectional Monte Carlo trick.
Twisted SMC shares connections with reinforcement learning, particularly soft RL with KL regularization. In this context, twist functions correspond to state-action Q-values, and the proposal plays a role analogous to an actor in actor-critic methods. This probabilistic perspective offers advantages over traditional RL approaches, including more principled resampling and unique evaluation techniques for language models.
The study evaluated the effectiveness of Twisted SMC and various inference methods across different language modelling tasks, including toxic story generation, sentiment-controlled review generation, and text infilling. Key findings include:
1. Log partition function estimation: Twisted SMC significantly improved sampling efficiency compared to simple importance sampling, especially when using the twist-induced proposal distribution.
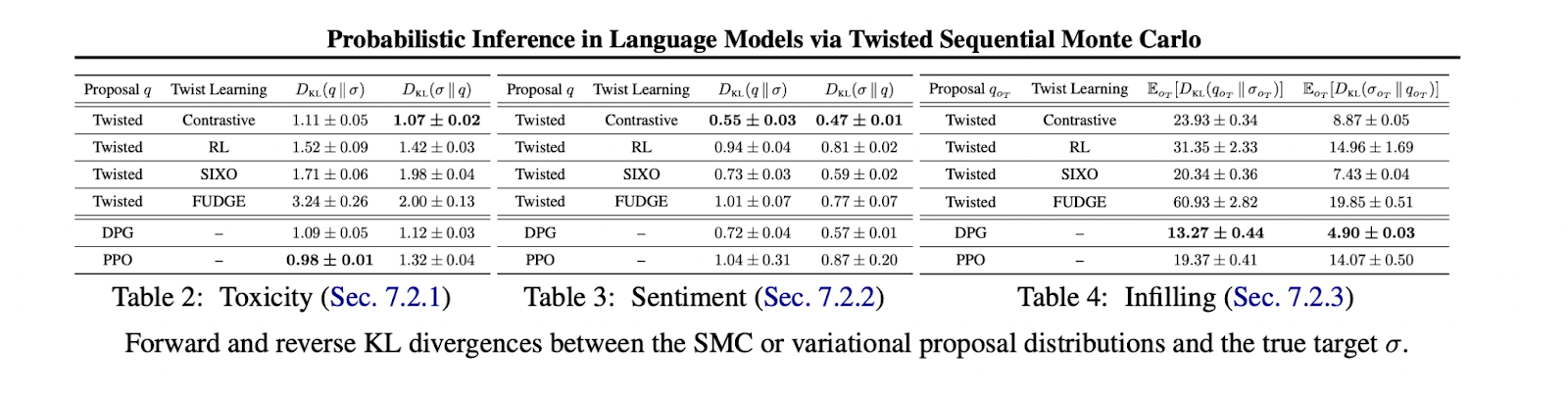
2. Toxicity task: CTL performed best in minimizing the reverse KL divergence, while PPO excelled in minimizing the forward KL divergence.
3. Sentiment control: CTL achieved the lowest KL divergences in both directions, outperforming other methods in generating reviews with varied sentiments.
4. Infilling task: Distributional Policy Gradient (DPG) showed the best performance, likely due to its ability to utilize exact positive samples. CTL and SIXO performed comparably, while PPO lagged.
5. Overall, the results demonstrated that the choice of inference method depends on the specific task and available sampling strategies. CTL proved effective with approximate positive sampling, while DPG excelled when exact target samples were available.
These findings highlight the versatility of the Twisted SMC framework in both improving sampling efficiency and evaluating various inference methods across different language modelling tasks.
This study introduces Twisted Sequential Monte Carlo, a powerful probabilistic inference framework for language models, addressing various capability and safety tasks. This approach introduces robust design choices and a contrastive method for twist learning, enhancing sampling efficiency and accuracy. The proposed bidirectional SMC bounds offer a robust evaluation tool for language model inference methods. Experimental results across diverse settings demonstrate the effectiveness of Twisted SMC in both sampling and evaluation tasks. This framework represents a significant advancement in probabilistic inference for language models, offering improved performance and versatility in handling complex language tasks.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 50k+ ML SubReddit
Asjad is an intern consultant at Marktechpost. He is persuing B.Tech in mechanical engineering at the Indian Institute of Technology, Kharagpur. Asjad is a Machine learning and deep learning enthusiast who is always researching the applications of machine learning in healthcare.
