Advances in vision-language models (VLMs) have shown impressive common sense, reasoning, and generalization abilities. This means that developing a fully independent digital AI assistant, that can perform daily computer tasks through natural language is possible. However, better reasoning and common-sense abilities don’t automatically lead to intelligent assistant behavior. AI assistants are used to complete tasks, behave rationally, and recover from mistakes, not just provide plausible responses based on pre-training data. So, a method is required to turn pre-training abilities into practical AI “agents.” Even the best VLMs, like GPT-4V and Gemini 1.5 Pro, still struggle to perform the right actions when completing device tasks.
This paper discusses three existing methods. The first method is training multi-modal digital agents, which face challenges like device control being done directly at the pixel level in a coordinate-based action space, and the stochastic and unpredictable nature of device ecosystems and the internet. The second method is Environments for device control agents. These environments are designed for evaluation, and offer a limited range of tasks in fully deterministic and stationary settings. The last method is Reinforcement learning (RL) for LLM/VLMs, where research with RL for foundation models focuses on single-turn tasks like preference optimization, but optimizing for single-turn interaction from expert demonstrations can lead to sub-optimal strategies for multi-step problems.
Researchers from UC Berkeley, UIUC, and Google DeepMind have introduced DigiRL (RL for Digital Agents), a novel autonomous RL method for training device control agents. The resulting agent attains state-of-the-art performance on several Android device-control tasks. The training process involves two phases: first, an initial offline RL phase to initialize the agent using existing data, followed by an offline-to-online RL phase, that is used for fine-tuning the model obtained from offline RL on online data. To train online RL a scalable and parallelizable Android learning environment was developed that includes a robust general-purpose evaluator (average error rate 2.8% against human judgment) based on VLM.
Researchers carried out experiments to evaluate the performance of DigiRL on challenging Android device control problems. It is important to understand if DigiRL has the potential to produce agents that can learn effectively through autonomous interaction, while still being able to utilize offline data for learning. So, a comparative analysis was performed on DigiRL against the following:
- State-of-the-art agents built around proprietary VLMs using several prompting and retrieval-style techniques.
- Running imitation learning on static human demonstrations with the same instruction distribution
- A filtered Behavior Cloning approach.
An agent trained using DigiRL was tested on various tasks from the Android in the Wild dataset (AitW) with real Android device emulators. The agent achieved a 28.7% improvement over the existing state-of-the-art agents (raising the success rate from 38.5% to 67.2%) 18B CogAgent. It also outperformed the previous top autonomous learning method based on Filtered Behavior Cloning by more than 9%. Moreover, despite having only 1.3B parameters, the agent performed better than advanced models like GPT-4V and Gemini 1.5 Pro (17.7% success rate). This makes it the first agent to achieve state-of-the-art performance in device control using an autonomous offline-to-online RL approach.
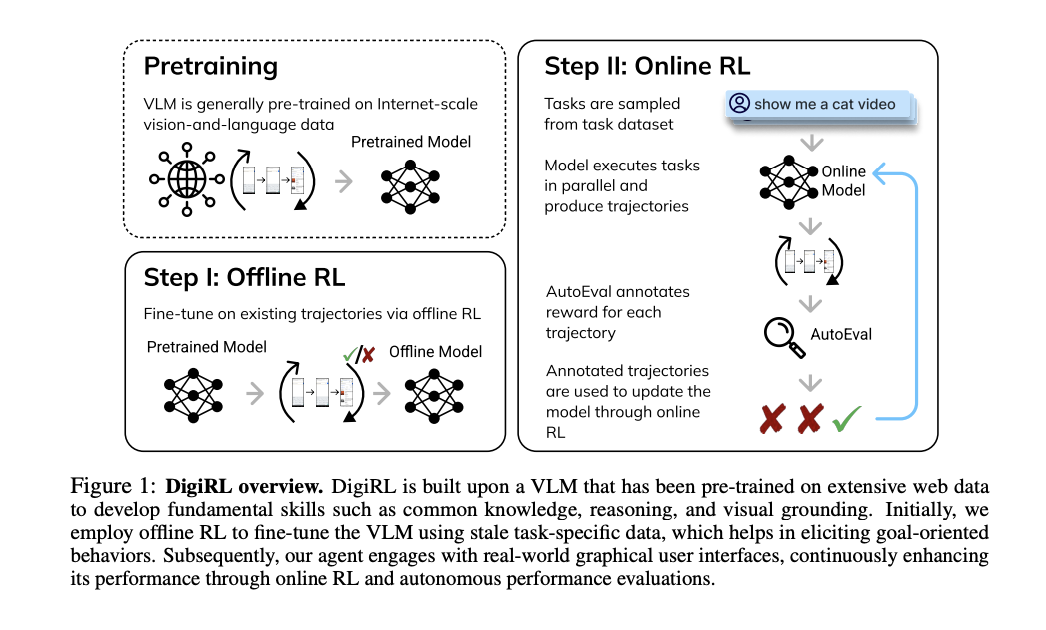
In summary, researchers proposed DigiRL, a novel autonomous RL approach for training device-control agents that sets a new state-of-the-art performance on several Android control tasks from AitW. A scalable and parallelizable Android environment was developed to achieve this with a robust VLM-based general-purpose evaluator for quick online data collection. The agent trained on DigiRL achieved a 28.7% improvement over the existing state-of-the-art agents 18B CogAgent. However, the training was limited to tasks from the AitW dataset instead of all possible device tasks. So, future work includes building algorithmic research and expanding the task space, making DigiRL the base algorithm.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter.
Join our Telegram Channel and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 45k+ ML SubReddit

Sajjad Ansari is a final year undergraduate from IIT Kharagpur. As a Tech enthusiast, he delves into the practical applications of AI with a focus on understanding the impact of AI technologies and their real-world implications. He aims to articulate complex AI concepts in a clear and accessible manner.
