
The protein design and prediction are crucial in advancing synthetic biology and therapeutics. Despite significant progress with deep learning models like AlphaFold and ProteinMPNN, there is a gap in accessible educational resources that integrate foundational machine learning concepts with advanced protein engineering methods. This gap hinders the broader understanding and application of these cutting-edge technologies. The challenge is developing practical, hands-on tools that enable researchers, educators, and students to effectively apply deep learning techniques to protein design tasks, bridging theoretical knowledge and real-world applications in computational protein engineering.
DL4Proteins notebook series is a Jupyter notebook series designed by Graylab researchers to make deep learning for protein design and prediction accessible to a broad audience. Inspired by the groundbreaking work of David Baker, Demis Hassabis, and John Jumper—recipients of the 2024 Nobel Prize in Chemistry—this resource provides practical introductions to tools like AlphaFold, RFDiffusion, and ProteinMPNN. Aimed at researchers, educators, and students, DL4Proteins integrates foundational machine learning concepts with advanced protein engineering methods, fostering innovation in synthetic biology and therapeutics. With topics ranging from neural networks to graph models, these open-source notebooks enable hands-on learning and bridge the gap between research and education.
The notebook “Neural Networks with NumPy” introduces the foundational concepts of neural networks and demonstrates their implementation using NumPy. It provides a hands-on approach to understanding how basic neural network components, such as forward and backward propagation, are constructed from scratch. The notebook demystifies the mathematical framework underlying neural networks by focusing on core operations like matrix multiplication and activation functions. This resource is ideal for beginners seeking to build an intuitive understanding of machine learning fundamentals without relying on advanced libraries. Through practical coding exercises, users gain essential insights into the mechanics of deep learning in a simplified yet effective way.
The notebook “Neural Networks with PyTorch” introduces building neural networks using a popular deep learning framework. It simplifies implementing neural networks by leveraging PyTorch’s high-level abstractions, such as tensors, autograd, and modules. The notebook guides users through creating, training, and evaluating models, highlighting how PyTorch automates key tasks like gradient computation and optimization. By transitioning from NumPy to PyTorch, users gain exposure to modern tools for scaling machine learning models. This resource enables a deeper understanding of neural networks through practical examples while showcasing PyTorch’s versatility in streamlining deep learning workflows.
The CNNs notebook introduces the foundational concepts of CNNs, focusing on their application in handling image-like data. It explains how CNNs utilize convolutional layers to extract spatial features from input data. The notebook demonstrates key components such as convolution, pooling, and fully connected layers while covering how to construct and train CNN models using PyTorch. Through step-by-step implementation and visualization, users learn how CNNs process input data hierarchically, enabling efficient feature extraction and representation for diverse deep-learning applications.
The “Language Models for Shakespeare and Proteins” notebook explores the use of LMs in understanding sequences, such as text and proteins. Drawing parallels between predicting words in Shakespearean texts and amino acids in protein sequences highlights the versatility of LMs. Using PyTorch, the notebook provides a hands-on guide to building and training simple language models for sequence prediction tasks. Additionally, it explains concepts like tokenization, embeddings, and the generation of sequential data, demonstrating how these techniques can be applied to both natural language and protein design, bridging the gap between computational linguistics and biological insights.
The “Language Model Embeddings: Transfer Learning for Downstream Tasks” notebook delves into applying language model embeddings in solving real-world problems. It demonstrates how embeddings, generated from pre-trained language models, capture meaningful patterns in sequences, whether in text or protein data. These embeddings are repurposed for downstream tasks like classification or regression, showcasing the power of transfer learning. The notebook provides a hands-on approach to extracting embeddings and training models for specific applications, such as protein property prediction. This approach accelerates learning and improves performance in specialized tasks by leveraging pre-trained models, bridging foundational knowledge and practical implementations.
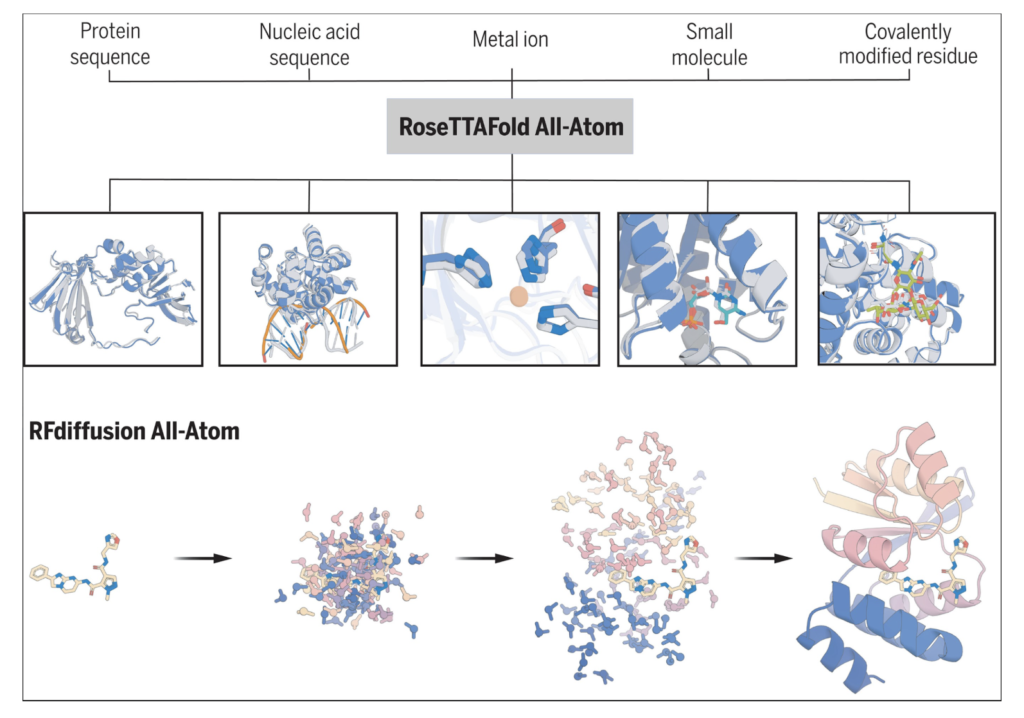
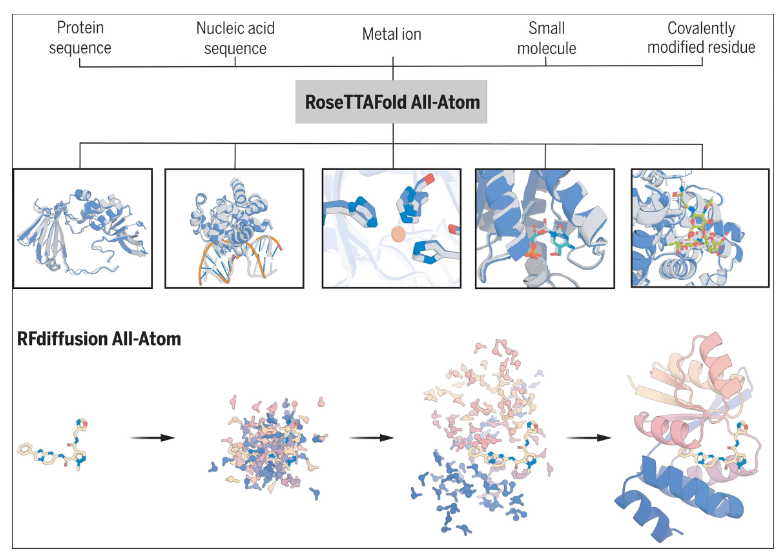
The “Introduction to AlphaFold” notebook provides an accessible overview of AlphaFold, a breakthrough tool for predicting protein structures with high accuracy. It explains the core principles behind AlphaFold, including its reliance on deep learning and the use of multiple sequence alignments (MSAs) to predict protein folding. The notebook offers practical insights into how AlphaFold generates 3D protein structures from amino acid sequences, showcasing its transformative impact on structural biology. Users are guided through real-world applications, enabling them to understand and apply this powerful tool in research, from exploring protein functions to advancing drug discovery and synthetic biology innovations.
The “Graph Neural Networks for Proteins” notebook introduces the use of GNNs in protein research, emphasizing their ability to model the complex relationships between amino acids in protein structures. It explains how GNNs treat proteins as graphs, where nodes represent amino acids, and edges capture interactions or spatial proximity. By leveraging GNNs, researchers can predict properties like protein functions or binding affinities. The notebook provides a practical guide to implementing GNNs for protein-related tasks, offering insights into their architecture and training process. This approach opens new possibilities in protein engineering, drug discovery, and understanding protein dynamics.
The “Denoising Diffusion Probabilistic Models” notebook explores the application of diffusion models in protein structure prediction and design. These models generate data by gradual denoising a noisy input, enabling the prediction of intricate molecular structures. The notebook explains the foundational concepts of diffusion processes and reverse sampling, guiding users through their application to protein modeling tasks. By simulating stepwise denoising, diffusion models can capture complex distributions, making them suitable for generating accurate protein conformations. This method provides a cutting-edge approach to tackling challenges in protein engineering, offering powerful tools for creating and refining protein structures in various scientific applications.
The “Putting It All Together: Designing Proteins” notebook combines advanced tools like RFdiffusion, ProteinMPNN, and AlphaFold to guide users through the complete protein design process. This workflow begins with RFdiffusion to generate backbone structures, followed by ProteinMPNN to design optimal sequences that stabilize the generated structures. Finally, AlphaFold is used to predict and refine the 3D structures of the designed proteins. By integrating these tools, the notebook provides a streamlined approach to protein engineering, enabling users to tackle real-world challenges in synthetic biology and therapeutics through the iterative design, validation, and refinement of protein structures.
The “RFDiffusion: All-Atom” notebook introduces RFdiffusion for generating high-fidelity protein structures, focusing on the full atomistic level of detail. It leverages a denoising diffusion model to iteratively refine and generate accurate atomic representations of protein structures from initial coarse backbones. This process allows for precisely predicting atomic positions and interactions within a protein, which is critical for understanding protein folding and function. The notebook guides users through setting up and running the RFdiffusion model, emphasizing its application in protein design and its potential to advance the field of structural biology and drug discovery.

In conclusion, integrating deep learning tools with protein design and prediction holds immense potential in advancing synthetic biology and therapeutics. The notebooks offer practical, hands-on resources for understanding and applying cutting-edge technologies like AlphaFold, RFDiffusion, ProteinMPNN, and graph-based models. These tools empower researchers, educators, and students to explore protein structure prediction, design, and optimization by bridging foundational machine-learning concepts with real-world applications.
Check out the GitHub Page. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. Don’t Forget to join our 60k+ ML SubReddit.


Sana Hassan, a consulting intern at Marktechpost and dual-degree student at IIT Madras, is passionate about applying technology and AI to address real-world challenges. With a keen interest in solving practical problems, he brings a fresh perspective to the intersection of AI and real-life solutions.