The study investigates the emergence of intelligent behavior in artificial systems by examining how the complexity of rule-based systems influences the capabilities of models trained to predict those rules. Traditionally, AI development has focused on training models using datasets that reflect human intelligence, such as language corpora or expert-annotated data. This method assumes that intelligence can only emerge from exposure to inherently intelligent data. However, this study explores an alternative theory, suggesting that intelligence might emerge from models trained on simple systems that generate complex behaviors, even if the underlying process lacks inherent intelligence.
The concept of complexity emerging from simple systems has been explored in foundational studies on cellular automata (CA), where even minimal rules can produce intricate patterns. Research by Wolfram and others demonstrated that systems operating at the edge of chaos—where order and disorder meet—exhibit higher computational capabilities. Studies have shown that complex behaviors can arise from simple rules, providing a framework for understanding how intelligence might develop from exposure to complexity rather than intelligent data alone. Recent advancements in LLMs also highlight the importance of training on complex data for the emergence of new capabilities, underscoring that both model size and the complexity of the data play a significant role in intelligence development.
Researchers from Yale, Columbia, Northwestern, and Idaho State Universities explored how complexity in rule-based systems influences the intelligence of models trained to predict these rules. Using elementary cellular automata (ECA), simple one-dimensional systems with varying degrees of complexity, they trained separate GPT-2 models on data generated by ECAs. The study revealed a strong link between the complexity of ECA rules and the models’ intelligence, demonstrated through improved performance on reasoning and chess prediction tasks. Their findings suggest that intelligence may emerge from the ability to predict complex systems, particularly those on the “edge of chaos.”
The study explored the link between system complexity and intelligence by training modified GPT-2 models on binary data generated from ECA. The ECAs were simulated over 1,000 time steps, producing sequences of binary vectors. The models were pretrained on next-token prediction for up to 10,000 epochs, using a modified architecture to handle binary inputs and outputs. Training sequences were randomly sampled, and the Adam optimizer with gradient clipping and learning rate scheduling was used to ensure efficient training. After pretraining, the models were evaluated on reasoning and chess move prediction tasks.
The study examines how system complexity affects the intelligence of LLMs. Results indicate that models pretrained on more complex ECA rules perform better on tasks like reasoning and chess move prediction, but excessive complexity, such as chaotic rules, can reduce performance. Models trained on complex rules integrate past information for forecasts, as their attention patterns show. Surprisingly, models predicting the next state outperformed those predicting five steps, suggesting that complex models learn nontrivial patterns. Overall, there appears to be an optimal level of complexity that enhances model intelligence and generalization abilities.
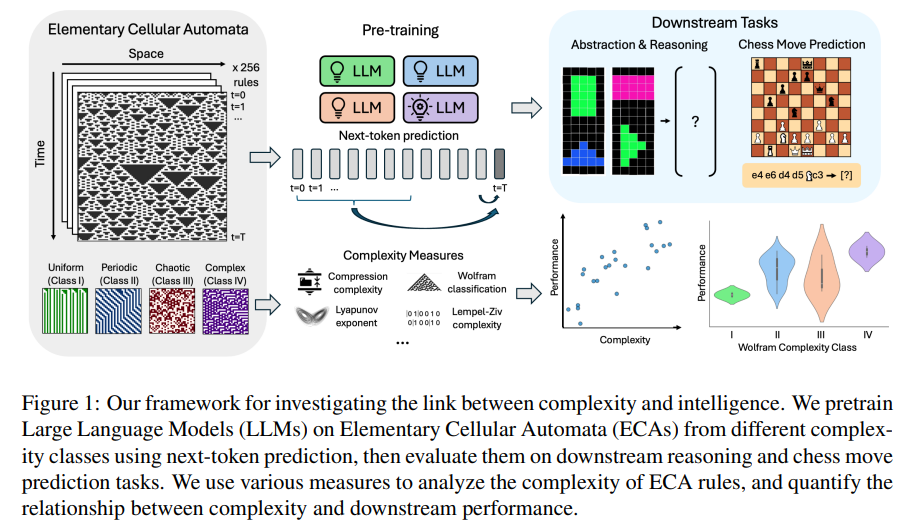
In conclusion, the study explores how intelligence emerges in LLMs trained on ECA with varying rule complexity. The results show that models trained on rules with moderate complexity—neither too simple nor too chaotic—perform better on tasks like reasoning and chess predictions. This supports the “edge of chaos” theory, where intelligence develops in systems balancing predictability and complexity. The study suggests that models learn better by leveraging historical information in complex tasks and that intelligence may emerge from exposure to systems with just the right level of complexity.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 50k+ ML SubReddit.
[Upcoming Live Webinar- Oct 29, 2024] The Best Platform for Serving Fine-Tuned Models: Predibase Inference Engine (Promoted)
Sana Hassan, a consulting intern at Marktechpost and dual-degree student at IIT Madras, is passionate about applying technology and AI to address real-world challenges. With a keen interest in solving practical problems, he brings a fresh perspective to the intersection of AI and real-life solutions.
