Graph Neural Networks GNNs are advanced tools for graph classification, leveraging neighborhood aggregation to update node representations iteratively. This process captures local and global graph structure, facilitating node classification and link prediction tasks. Effective graph pooling is essential for downsizing and learning representations, categorized into global and hierarchical pooling. Hierarchical methods, such as TopK-based and cluster-based strategies, aim to retain structural features but face challenges like potential information loss and over-smoothing. Recent approaches incorporate self-attention mechanisms to address these issues, though challenges like computational expense and edge importance remain.
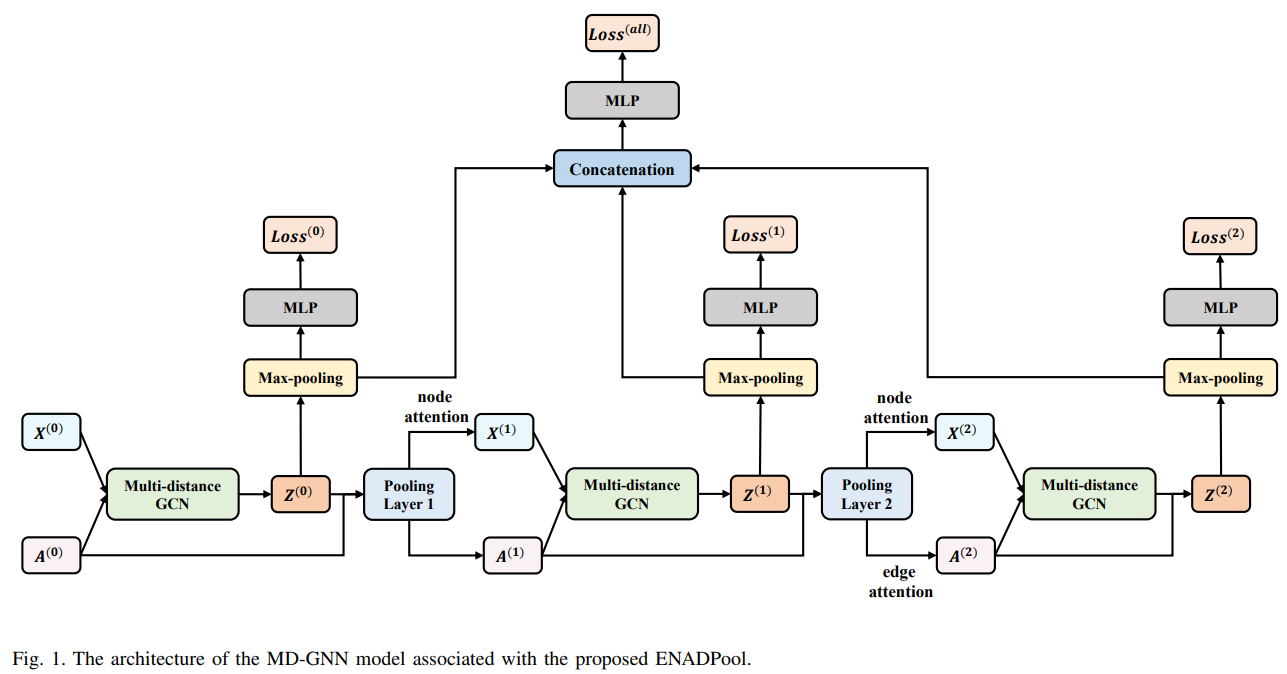
Researchers from Beijing Normal University, Central University of Finance and Economics, Zhejiang Normal University, and the University of York have developed a new hierarchical pooling method for GNNs called Edge-Node Attention-based Differentiable Pooling (ENADPool). Unlike traditional methods, ENADPool uses hard clustering and attention mechanisms to compress node features and edge strengths, addressing issues with uniform aggregation. Additionally, they introduced a Multi-distance GNN (MD-GNN) model to reduce over-smoothing by allowing nodes to receive information from neighbors at various distances. ENADPool’s design eliminates the need for separate attention computations, improving efficiency. Experiments show that the MD-GNN combined with ENADPool effectively enhances graph classification performance.
The study reviews existing works related to GNNs, including graph convolutional networks, pooling operations, and attention mechanisms. GNNs, classified into spectral-based and spatial-based, excel in graph data analysis. Spectral methods, like ChebNet, use the Laplacian matrix, while spatial methods, like GraphSAGE, aggregate local node information. Both face over-smoothing issues, addressed by models like MixHop and N-GCN. For graph-level classification, pooling operations, categorized into global and hierarchical methods, are crucial. Hierarchical pooling, like DiffPool, clusters nodes but has limitations addressed by ABDPool, which uses attention mechanisms. Graph attention, used in GAT and GaAN, assigns weights to nodes based on their importance.
ENADPool is a cluster-based hierarchical pooling method that assigns nodes to unique clusters, calculates node importance using attention mechanisms, and compresses node features and edge connectivity for subsequent layers. It involves three steps: hard node assignment, node-based attention, and edge-based attention, resulting in weighted compressed node features and adjacency matrices. The MD-GNN model mitigates over-smoothing by aggregating node information from different distances and reconstructing graph topology to capture comprehensive structural details. This approach enhances the effectiveness of ENADPool and improves graph representation.
The study compares the ENADPool and MD-GNN model against other graph deep learning methods using benchmark datasets like D&D, PROTEINS, NCI1/NCI109, FRANKENSTEIN, and REDDIT-B. Baselines include hierarchical methods (e.g., SAGPool(H), ASAPool, DiffPool, ABDPool) and global pooling methods (e.g., DGCNN, SAGPool(G), KerGNN, GCKN). Using 10-fold cross-validation, the researchers assess the models and report average accuracy and standard deviation. Their architecture employs two pooling layers with MD-GNNs for embeddings and node assignments, optimized with ReLU activation, dropout, and auxiliary classifiers during training. The method performs superior due to hard node assignment, attention-based importance for nodes and edges, MD-GNN integration, and effective feature representation.
In conclusion, ENADPool compresses node features and edge connectivity into hierarchical structures using attention mechanisms after each pooling step, effectively identifying the importance of nodes and edges. This approach addresses the shortcomings of traditional pooling methods that use unclear node assignments and uniform feature aggregation. Additionally, the MD-GNN model mitigates the over-smoothing problem by allowing nodes to receive information from neighbors at various distances.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 42k+ ML SubReddit
Sana Hassan, a consulting intern at Marktechpost and dual-degree student at IIT Madras, is passionate about applying technology and AI to address real-world challenges. With a keen interest in solving practical problems, he brings a fresh perspective to the intersection of AI and real-life solutions.
