Machine learning research has advanced toward models that can autonomously design and discover data structures tailored to specific computational tasks, such as nearest neighbor (NN) search. This shift in methodology allows models to learn not only the structure of data but also how to optimize query responses, minimizing storage needs and computation time. Machine learning now moves beyond traditional data processing, tackling structural optimization in data to create adaptable frameworks that exploit distribution patterns and data characteristics. Such adaptability is valuable across fields where efficient data retrieval is crucial, especially in domains where speed and storage are constrained.
Designing efficient data structures remains a significant challenge. Existing structures, like binary search trees and k-d trees, are typically designed with worst-case scenarios in mind. While this ensures reliable performance, it also means they do not leverage potential patterns in the data for more efficient querying. Consequently, many traditional data structures cannot capitalize on characteristics unique to each dataset, resulting in suboptimal performance for queries that could otherwise benefit from custom, adaptive structures. As a result, there is growing interest in data structures that can adapt to specific data distributions, offering faster query times and reduced memory usage tailored to particular applications.
Methods developed to improve data structure efficiency have primarily focused on learning-augmented algorithms, where traditional data structures are modified with machine learning predictions to speed up queries. However, even these methods are limited by their reliance on predefined structures that may need to be optimally suited to the dataset. For example, while learning-augmented trees and locality-sensitive hashing improve search efficiency by combining algorithmic principles with predictive models, they are constrained by human-defined structures. These models still depend on initial data structures, limiting their ability to adapt to unique data distributions autonomously.
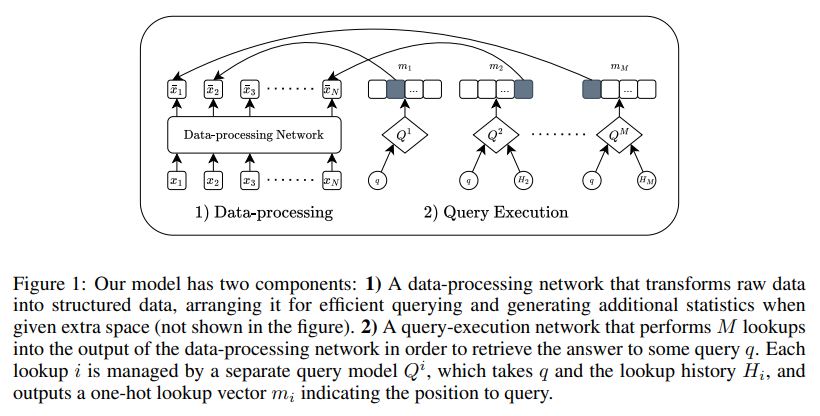
The researchers from Universite de Montreal Mila, HEC Montreal Mila, Microsoft Research, University of Southern California, and Stanford University proposed an innovative framework that leverages machine learning to discover data structures suited for specific tasks autonomously. This framework includes two core components:
- A data-processing network that arranges raw data into optimized structures
- A query-execution network that efficiently navigates the structured data for retrieval
Both networks undergo joint end-to-end training, allowing them to adapt to varying data distributions. By eliminating the need for predefined structures, the framework autonomously designs optimized configurations that outperform traditional methods across different data and query types, including NN search and frequency estimation in streaming data.
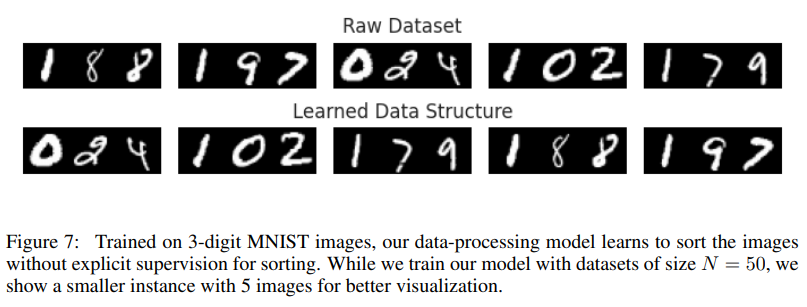
The methodology involves an 8-layer transformer model, where the data-processing network ranks elements within a dataset, organizing them into efficient configurations. This ranking is refined through a differentiable sorting function, which orders the data based on their ranks. Meanwhile, the query-execution network, comprising multiple independent models, learns an optimal search strategy for retrieving specific data points based on historical query patterns. This joint training customizes the data structure and enhances query accuracy. For instance, the model demonstrates high precision in correctly ordering 99.5% of 1D NN search data despite needing to be explicitly programmed. This level of precision exemplifies how data-driven structures, once designed, can enhance both storage efficiency and retrieval speed.
The framework excelled across several test scenarios in evaluations. In 1D NN search, the model displayed accuracy levels higher than traditional binary search methods. For example, the model outperformed binary search by strategically initiating queries closer to the target location when tested on data with a uniform distribution over (-1, 1) with 100 elements and limited to seven lookups. In high-dimensional contexts, such as 30-dimensional hyperspheres, the model used projections that closely resembled locality-sensitive hashing, achieving results comparable to specialized algorithms. Notably, in a challenging setup where query accuracy must be completed within a limited space, the model utilized additional space effectively, trading memory for query precision. The model’s accuracy increased when given seven extra vectors for storage, demonstrating its adaptability to varying spatial constraints.
The research presents several key takeaways that illustrate the framework’s capabilities and innovations:
- Autonomous Structure Discovery: The model independently learns the most effective data structure configurations, removing the need for predefined, human-designed structures.
- High Precision in Simple and Complex Data Settings: Achieved 99.5% accuracy in ordered ranking for 1D NN search and successfully navigated uniform and high-dimensional data with minimal supervision.
- Efficient Use of Extra Space for Enhanced Accuracy: The framework demonstrated a clear performance boost as additional memory was allocated, showing adaptability in constrained environments.
- Broad Applicability Beyond NN Search: The framework’s flexibility was further highlighted in frequency estimation tasks, where it exceeded the performance of CountMin sketch models in data with Zipfian distributions, indicating potential for other high-demand applications.

In conclusion, this research illustrates a promising step toward the future of machine learning-driven data structure discovery. By harnessing adaptive end-to-end training, this framework efficiently addresses the storage and query challenges that traditional data structures face, especially when working within real-world data constraints. This approach enhances the speed and accuracy of data retrieval and opens avenues for autonomous discovery in data processing, marking a significant advancement in machine learning’s application to structural optimization.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 55k+ ML SubReddit.
[Sponsorship Opportunity with us] Promote Your Research/Product/Webinar with 1Million+ Monthly Readers and 500k+ Community Members
Sana Hassan, a consulting intern at Marktechpost and dual-degree student at IIT Madras, is passionate about applying technology and AI to address real-world challenges. With a keen interest in solving practical problems, he brings a fresh perspective to the intersection of AI and real-life solutions.
