Large Language Models (LLMs) have significantly impacted software engineering, primarily in code generation and bug fixing. These models leverage vast training data to understand and complete code based on user input. However, their application in requirement engineering, a crucial aspect of software development, remains underexplored. Software engineers have shown reluctance to use LLMs for higher-level design tasks due to concerns about complex requirement comprehension. Despite this, LLMs’ use in requirement engineering has gradually increased, driven by advancements in contextual analysis and reasoning through prompt engineering and Chain-of-Thought techniques.
The field of LLM-based agents lacks standardized benchmarks, impeding effective performance evaluation. Previous research inadequately differentiated between LLMs and LLM-based agents’ contributions. This study addresses these gaps by providing a comparative analysis of their applications and effectiveness across various software engineering domains, aiming to elucidate the potential of LLM-based agents in software engineering practices.
Large Language Models (LLMs) have shown remarkable success in software engineering tasks like code generation and vulnerability detection but exhibit limitations in autonomy and self-improvement. LLM-based agents address these limitations by combining LLMs for decision-making and action-taking. This study emphasizes the need to distinguish between LLMs and LLM-based agents, investigating their applications in requirement engineering, code generation, autonomous decision-making, software design, test generation, and software maintenance. It provides a comprehensive analysis of tasks, benchmarks, and evaluation metrics for both technologies, aiming to elucidate their potential in advancing software engineering practices and potentially progressing towards Artificial General Intelligence.
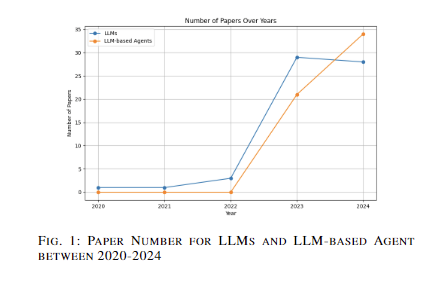
The study tackles crucial challenges in applying Large Language Models (LLMs) to software engineering tasks, focusing on their inherent limitations in autonomy and self-improvement. It identifies a significant gap in existing literature regarding clear distinctions between LLMs and LLM-based agents. The research highlights the absence of unified standards and benchmarks for evaluating LLM solutions as agents. It provides a comprehensive analysis of LLMs and LLM-based agents across six key software engineering topics: requirement engineering, code generation, autonomous decision-making, software design, test generation, and software maintenance. The paper aims to highlight gaps and propose future directions for LLM-based agents in software engineering, pushing the boundaries of these technologies.
A systematic literature review methodology examined LLMs and LLM-based agents in software engineering. DBLP and arXiv databases were searched for studies from late 2023 to May 2024. Papers were filtered based on relevance and length using specific software engineering keywords. A snowballing technique enhanced comprehensiveness. The final selection included 117 relevant papers, some categorized under multiple topics. The analysis focused on experimental models and frameworks, examining performance across various domains. Visual representations illustrated model usage frequency. This structured approach provided a robust analysis of LLMs and LLM-based agents in software engineering, highlighting applications and challenges.

The study examined LLMs and LLM-based agents across six key software engineering areas: requirement engineering, code generation, autonomous decision-making, software design and evaluation, test generation, and maintenance. Performance metrics included Pass@k, BLEU scores, and success rates. HumanEval and MBPP served as primary benchmark datasets for code generation tasks, while many studies used customized datasets. The research identified 79 unique LLMs across 117 papers.
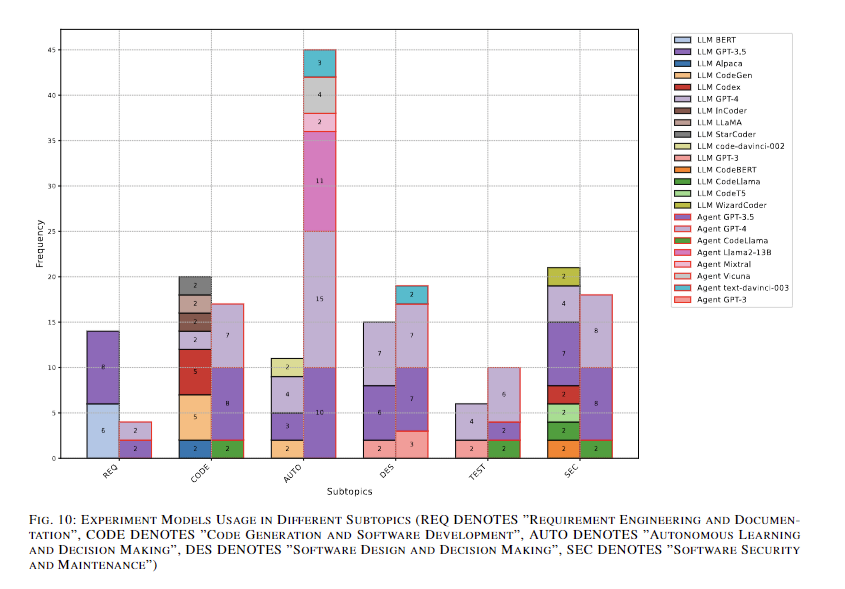
Results indicated growing interest in LLM-based agents, combining LLMs with decision-making capabilities to enhance autonomy and self-improvement in software development. User feedback from developers and requirements engineers was crucial for evaluating the accuracy, usability, and completeness of generated outputs. The findings highlight significant advancements in AI for software engineering while also identifying areas for further research and development.
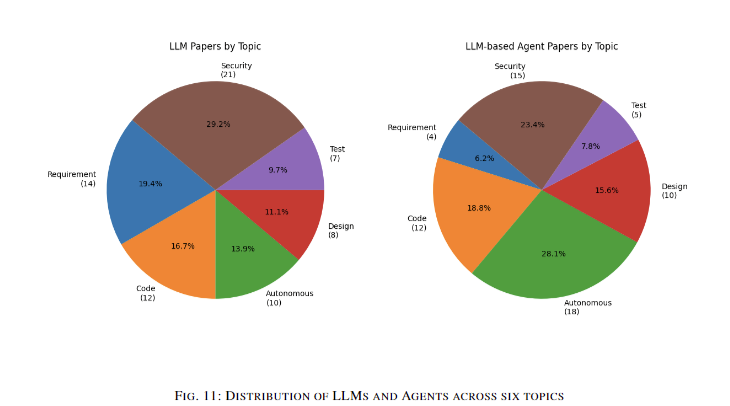
In conclusion, the study provides a comprehensive analysis of Large Language Models and LLM-based agents in software engineering. It categorizes software engineering into six key topics, offering insights into diverse LLM applications. The research establishes a clear distinction between traditional LLMs and LLM-based agents, emphasizing their differing capabilities and performance metrics. LLM-based agents demonstrate potential enhancements to existing processes across various software engineering domains. Statistical analysis of datasets and evaluation metrics highlights performance differences between LLMs and LLM-based agents. The paper suggests future research directions, emphasizing the need for unified standards and benchmarking. It concludes that LLM-based agents represent a promising evolution in addressing the limitations of traditional models, potentially leading to more autonomous and effective software engineering solutions.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 48k+ ML SubReddit
Find Upcoming AI Webinars here

Shoaib Nazir is a consulting intern at MarktechPost and has completed his M.Tech dual degree from the Indian Institute of Technology (IIT), Kharagpur. With a strong passion for Data Science, he is particularly interested in the diverse applications of artificial intelligence across various domains. Shoaib is driven by a desire to explore the latest technological advancements and their practical implications in everyday life. His enthusiasm for innovation and real-world problem-solving fuels his continuous learning and contribution to the field of AI

