
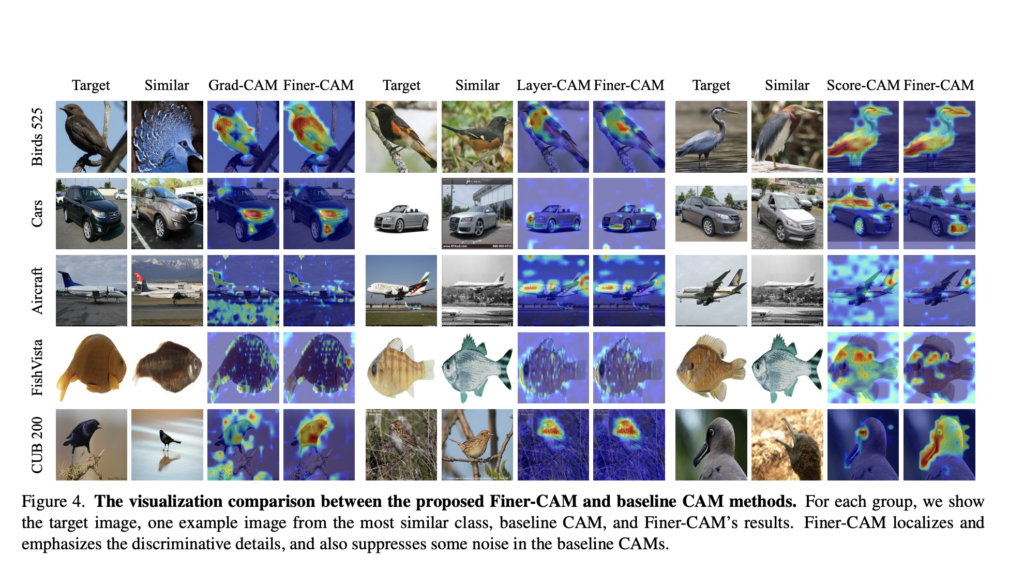
Researchers at The Ohio State University have introduced Finer-CAM, an innovative method that significantly improves the precision and interpretability of image explanations in fine-grained classification tasks. This advanced technique addresses key limitations of existing Class Activation Map (CAM) methods by explicitly highlighting subtle yet critical differences between visually similar categories.
Current Challenge with Traditional CAM
Conventional CAM methods typically illustrate general regions influencing a neural network’s predictions but frequently fail to distinguish fine details necessary for differentiating closely related classes. This limitation poses significant challenges in fields requiring precise differentiation, such as species identification, automotive model recognition, and aircraft type differentiation.
Finer-CAM: Methodological Breakthrough
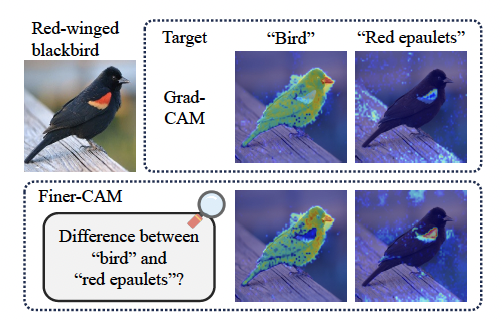
The central innovation of Finer-CAM lies in its comparative explanation strategy. Unlike traditional CAM methods that focus solely on features predictive of a single class, Finer-CAM explicitly contrasts the target class with visually similar classes. By calculating gradients based on the difference in prediction logits between the target class and its similar counterparts, it reveals unique image features, enhancing the clarity and accuracy of visual explanations.
Finer-CAM Pipeline

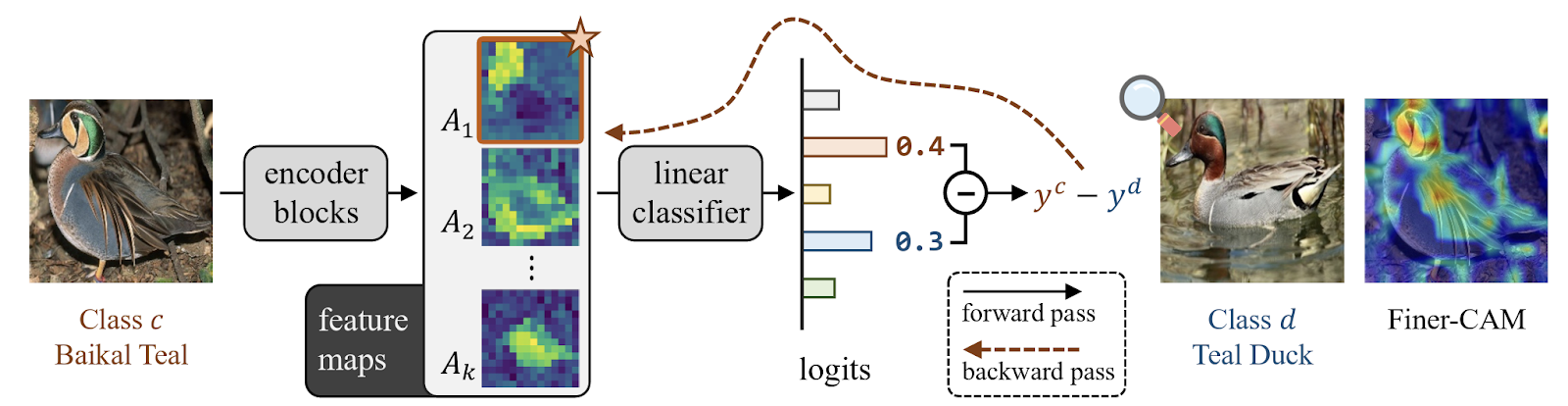
The methodological pipeline of Finer-CAM involves three main stages:
- Feature Extraction:
- An input image first passes through neural network encoder blocks, generating intermediate feature maps.
- A subsequent linear classifier uses these feature maps to produce prediction logits, which quantify the confidence of predictions for various classes.
- Gradient Calculation (Logit Difference):
- Standard CAM methods calculate gradients for a single class.
- Finer-CAM computes gradients based on the difference between the prediction logits of the target class and a visually similar class.
- This comparison identifies the subtle visual features specifically discriminative to the target class by suppressing commonly shared features.
- Activation Highlighting:
- The gradients calculated from the logit difference are used to produce enhanced class activation maps that emphasize discriminative visual details crucial for distinguishing between similar categories.

Experimental Validation
B.1. Model Accuracy
Researchers evaluated Finer-CAM across two popular neural network backbones, CLIP and DINOv2. Experiments demonstrated that DINOv2 generally produces higher-quality visual embeddings, achieving superior classification accuracy compared to CLIP across all tested datasets.


B.2. Results on FishVista and Aircraft
Quantitative evaluations on the FishVista and Aircraft datasets further demonstrate Finer-CAM’s effectiveness. Compared to baseline CAM methods (Grad-CAM, Layer-CAM, Score-CAM), Finer-CAM consistently delivered improved performance metrics, notably in relative confidence drop and localization accuracy, underscoring its ability to highlight discriminative details crucial for fine-grained classification.
B.3. Results on DINOv2
Additional evaluations using DINOv2 as the backbone showed that Finer-CAM consistently outperformed baseline methods. These results indicate that Finer-CAM’s comparative method effectively enhances localization performance and interpretability. Due to DINOv2’s high accuracy, more pixels need to be masked to significantly impact predictions, resulting in larger deletion AUC values and occasionally smaller relative confidence drops compared to CLIP.
Visual and Quantitative Advantages
- Highly Precise Localization: Clearly pinpoints discriminative visual features, such as specific coloration patterns in birds, detailed structural elements in cars, and subtle design variations in aircraft.
- Reduction of Background Noise: Significantly reduces irrelevant background activations, increasing the relevance of explanations.
- Quantitative Excellence: Outperforms traditional CAM approaches (Grad-CAM, Layer-CAM, Score-CAM) in metrics including relative confidence drop and localization accuracy.


Extendable to multi-modal zero-shot learning scenarios
Finer-CAM is extendable to multi-modal zero-shot learning scenarios. By intelligently comparing textual and visual features, it accurately localizes visual concepts within images, significantly expanding its applicability and interpretability.


Researchers have made Finer-CAM’s source code and colab demo available.
Check out the Paper, Github and Colab demo. All credit for this research goes to the researchers of this project. Also, feel free to follow us on Twitter and don’t forget to join our 80k+ ML SubReddit.


Jean-marc is a successful AI business executive .He leads and accelerates growth for AI powered solutions and started a computer vision company in 2006. He is a recognized speaker at AI conferences and has an MBA from Stanford.