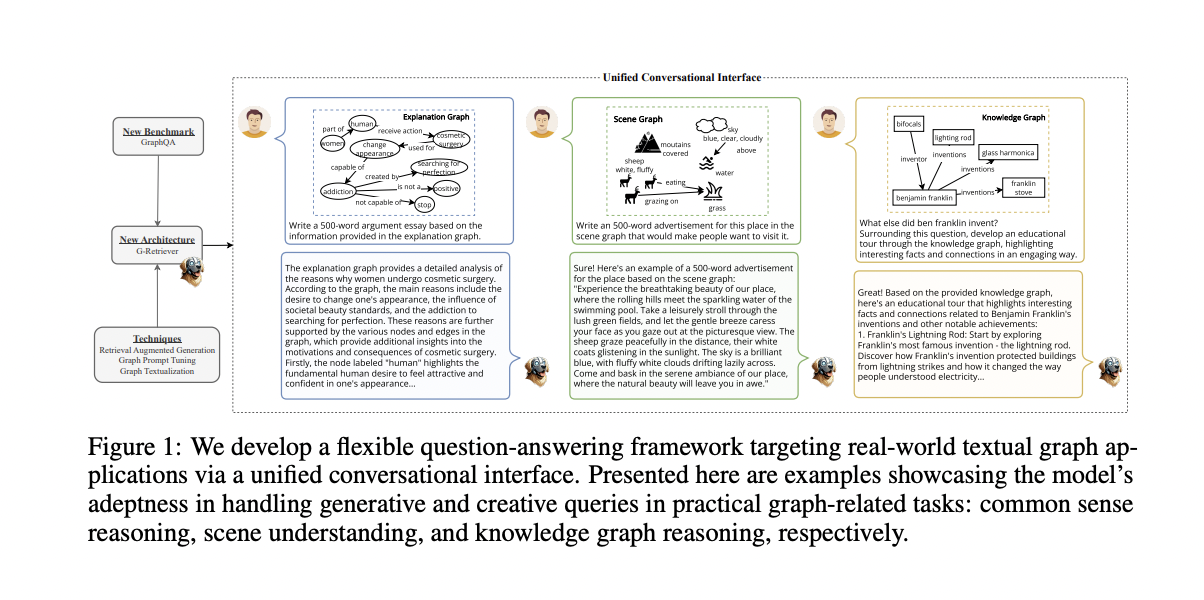
Large Language Models (LLMs) have made significant strides in artificial intelligence, but their ability to process complex structured data, particularly graphs, remains challenging. In our interconnected world, a substantial portion of real-world data inherently possesses a graph structure, including the Web, e-commerce systems, and knowledge graphs. Many of these involve textual graphs, making them suitable for LLM-centric methods. While efforts have been made to combine graph-based technologies like Graph Neural Networks (GNNs) with LLMs, they primarily focus on conventional graph tasks or simple questions on small graphs. The research aims to develop a flexible question-answering framework for complex, real-world graphs, enabling users to interact with their graph data through a unified conversational interface.
Researchers have made significant strides in combining graph-based techniques with LLMs. These efforts span various areas, including general graph models, multi-modal architectures, and practical applications such as fundamental graph reasoning, node classification, and graph classification/regression. Retrieval-augmented generation (RAG) has emerged as a promising approach to mitigate hallucination in LLMs and enhance trustworthiness. While successful in language tasks, RAG’s application to general graph tasks still needs to be explored, with most existing work focusing on knowledge graphs. Parameter-efficient fine-tuning (PEFT) techniques have also played a crucial role in refining LLMs, leading to the development of sophisticated multimodal models. However, the application of these advanced techniques to graph-specific LLMs is still in its early stages.
Researchers from the National University of Singapore, University of Notre Dame, Loyola Marymount University, New York University, and Meta AI propose G-Retriever, an innovative architecture designed for GraphQA, integrating the strengths of GNNs, LLMs, and RAG. This framework enables efficient fine-tuning while preserving the LLM’s pre-trained language capabilities by freezing the LLM and using a soft prompting approach on the GNN’s output. G-Retriever’s RAG-based design mitigates hallucinations through direct retrieval of graph information, allowing it to scale to graphs exceeding the LLM’s context window size. The architecture adapts RAG to graphs by formulating subgraph retrieval as a Prize-Collecting Steiner Tree (PCST) optimization problem, enhancing explainability by returning the retrieved subgraph.
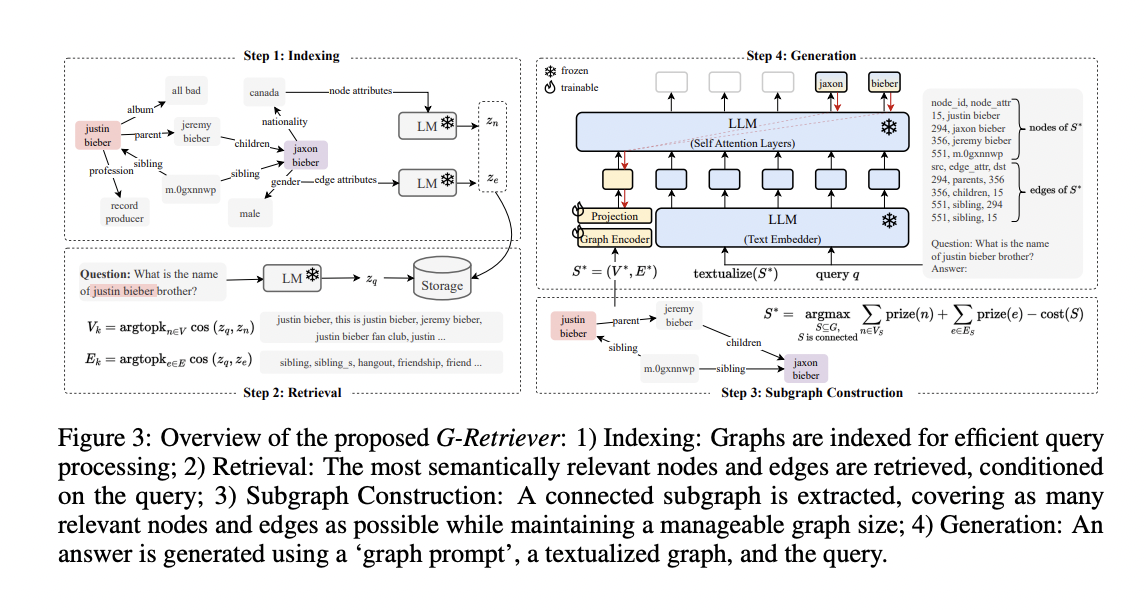
G-Retriever’s architecture comprises four main steps: indexing, retrieval, subgraph construction, and generation. In the indexing step, node and graph embeddings are generated using a pre-trained language model and stored in a nearest-neighbor data structure. The retrieval step uses k-nearest neighbors to identify the most relevant nodes and edges for a given query. Subgraph construction employs the Prize-Collecting Steiner Tree algorithm to create a manageable, relevant subgraph. The generation step involves a Graph Attention Network for encoding the subgraph, a projection layer to align the graph token with the LLM’s vector space, and a text embedder to transform the subgraph into a textual format. Finally, the LLM generates an answer using graph prompt tuning, combining the graph token and text embedder output.
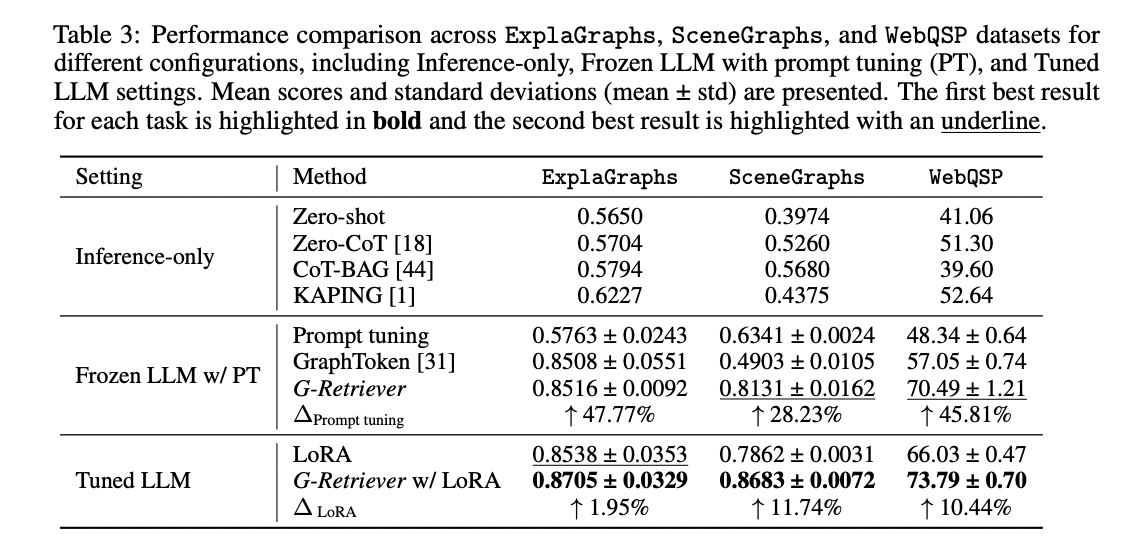
G-Retriever demonstrates superior performance across three datasets in various configurations, outperforming baselines in inference-only settings and showing significant improvements with prompt tuning and LoRA fine-tuning. The method greatly enhances efficiency by reducing token and node counts, leading to faster training times. It effectively mitigates hallucination by 54% compared to baselines. An ablation study reveals the importance of all components, particularly the graph encoder and textualized graph. G-Retriever proves robust to different graph encoders and benefits from larger LLM scales, showcasing its effectiveness in graph question-answering tasks.
This work introduces a new GraphQA benchmark for real-world graph question answering and presents G-Retriever, an architecture designed for complex graph queries. Unlike previous approaches focusing on conventional graph tasks or simple queries, G-Retriever targets real-world textual graphs across multiple applications. The method implements a RAG approach for general textual graphs, using soft prompting for enhanced graph understanding. G-Retriever employs Prize-Collecting Steiner Tree optimization to perform RAG over graphs, enabling resistance to hallucination and handling of large-scale graphs. Experimental results demonstrate G-Retriever’s superior performance over baselines in various textual graph tasks, effective scaling with larger graphs, and significant reduction in hallucination.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter.
Join our Telegram Channel and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 46k+ ML SubReddit
Asjad is an intern consultant at Marktechpost. He is persuing B.Tech in mechanical engineering at the Indian Institute of Technology, Kharagpur. Asjad is a Machine learning and deep learning enthusiast who is always researching the applications of machine learning in healthcare.
