
Reinforcement learning (RL) has been pivotal in advancing artificial intelligence by enabling models to learn from their interactions with the environment. Traditionally, reinforcement learning relies on rewards for positive actions and penalties for negative ones. A recent approach, Reinforcement Learning from Human Feedback (RLHF), has brought remarkable improvements to large language models (LLMs) by incorporating human preferences into the training process. RLHF ensures that AI systems behave in ways aligned with human values. However, gathering and processing this feedback is resource-intensive, requiring large datasets of human-labeled preferences. With AI systems growing in scale and complexity, researchers are exploring more efficient ways to improve model performance without relying solely on human input.
Models trained using RLHF need vast amounts of preference data to make decisions that align with user expectations. As human data collection is expensive, the process creates a bottleneck, slowing down model development. Also, reliance on human feedback limits models’ generalizability to new tasks they have yet to encounter during training. This can lead to poor performance when models are deployed in real-world environments that need to handle unfamiliar or out-of-distribution (OOD) scenarios. Addressing this issue requires a method that reduces the dependency on human data and improves model generalization.
Current approaches like RLHF have proven useful, but they have limitations. In RLHF, models are refined based on human-provided feedback, which involves ranking outputs according to user preferences. While this method improves alignment, it can be inefficient. A recent alternative, Reinforcement Learning from AI Feedback (RLAIF), seeks to overcome this using AI-generated feedback. A model uses predefined guidelines, or a “constitution,” to evaluate its outputs. Though RLAIF reduces reliance on human input, recent studies show that AI-generated feedback can misalign with actual human preferences, resulting in suboptimal performance. This misalignment is particularly evident in out-of-distribution tasks where the model needs to understand nuanced human expectations.
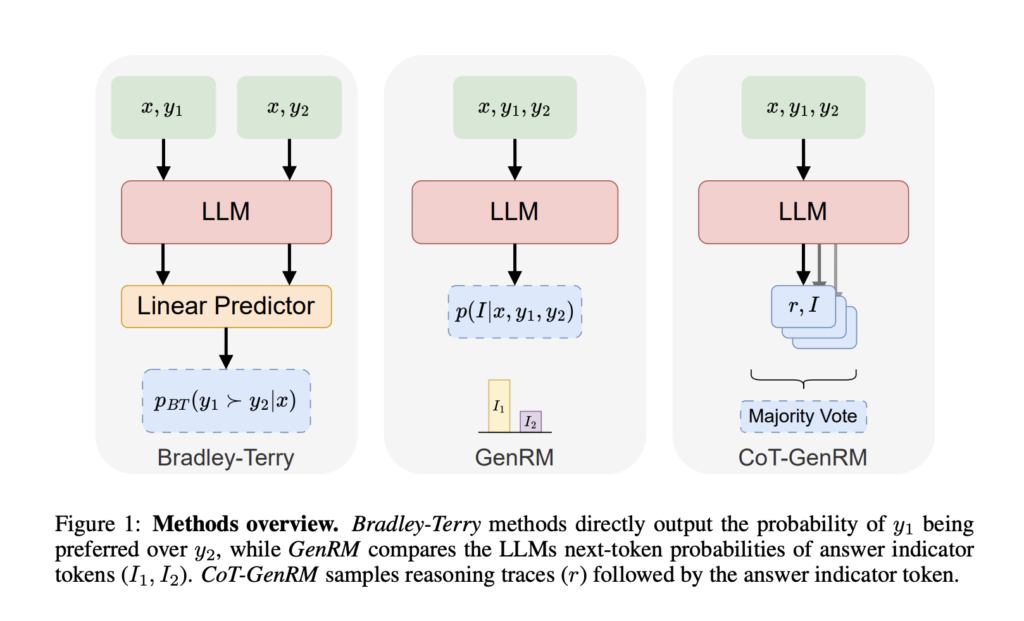
SynthLabs and Stanford University researchers introduced a hybrid solution: Generative Reward Models (GenRM). This new method combines the strengths of both approaches to train models more effectively. GenRM uses an iterative process to fine-tune LLMs by generating reasoning traces, which act as synthetic preference labels. These labels better reflect human preferences while eliminating the need for extensive human feedback. The GenRM framework bridges the gap between RLHF and RLAIF by allowing AI to generate its input and continuously refine itself. The introduction of reasoning traces helps the model mimic the detailed human thought process that improves decision-making accuracy, particularly in more complex tasks.
GenRM leverages a large pre-trained LLM to generate reasoning chains that help decision-making. Chain-of-Thought (CoT) reasoning is incorporated into the model’s workflow, where the AI generates step-by-step reasoning before concluding. This self-generated reasoning serves as feedback for the model, which is further refined in iterative cycles. The GenRM model compares favorably against traditional methods like Bradley-Terry reward models and DPO (Direct Preference Optimization), surpassing them in accuracy by 9-31% in in-distribution tasks and 10-45% on out-of-distribution tasks. These iterative refinements reduce the resource load and improve the model’s ability to generalize across tasks.

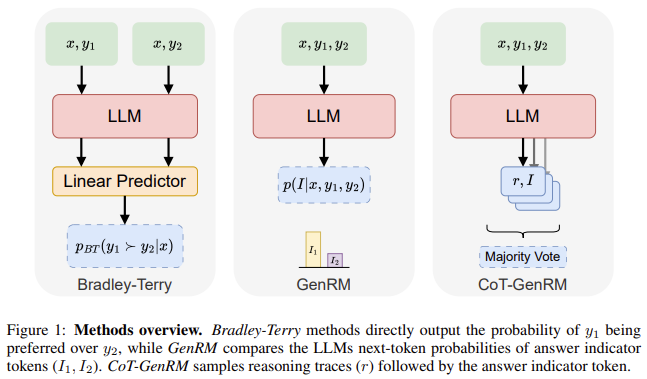
In in-distribution tasks, where models are tested on problems they’ve seen before, GenRM performs similarly to the Bradley-Terry reward model, maintaining high accuracy rates. However, the true advantage of GenRM is apparent in OOD tasks. For instance, GenRM outperforms traditional models by 26% in generalization tasks, making it better suited for real-world applications where AI systems are required to handle new or unexpected scenarios. Also, models using GenRM showed improvements in reducing errors in decision-making and providing more accurate outputs aligned with human values, demonstrating between 9% and 31% improved performance in tasks requiring complex reasoning. The model also outperformed LLM-based judges, which rely solely on AI feedback, showcasing a more balanced approach to feedback optimization.

Key Takeaways from the Research:
- Increased Performance: GenRM improves in-distribution task performance by 9-31% and OOD tasks by 10-45%, showing superior generalization abilities.
- Reduced Dependency on Human Feedback: AI-generated reasoning traces replace the need for large human-labeled datasets, speeding up the feedback process.
- Improved Out-of-Distribution Generalization: GenRM performs 26% better than traditional models in unfamiliar tasks, enhancing robustness in real-world scenarios.
- Balanced Approach: The hybrid use of AI and human feedback ensures that AI systems stay aligned with human values while reducing training costs.
- Iterative Learning: Continuous refinement through reasoning chains enhances decision-making in complex tasks, improving accuracy and reducing errors.


In conclusion, the introduction of Generative Reward Models presents a powerful step forward in reinforcement learning. Combining human feedback with AI-generated reasoning allows for more efficient model training without sacrificing performance. GenRM solves two critical issues: it reduces the need for labor-intensive human data collection while improving the model’s ability to handle new, untrained tasks. By integrating RLHF and RLAIF, GenRM represents a scalable and adaptable solution for advancing AI alignment with human values. The hybrid system boosts in-distribution accuracy and significantly enhances out-of-distribution performance, making it a promising framework for the next generation of intelligent systems.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 50k+ ML SubReddit.
[Upcoming Live Webinar- Oct 29, 2024] The Best Platform for Serving Fine-Tuned Models: Predibase Inference Engine (Promoted)


Sana Hassan, a consulting intern at Marktechpost and dual-degree student at IIT Madras, is passionate about applying technology and AI to address real-world challenges. With a keen interest in solving practical problems, he brings a fresh perspective to the intersection of AI and real-life solutions.