Global-MMLU🌍 by researchers from Cohere For AI, EPFL, Hugging Face, Mila, McGill University & Canada CIFAR AI Chair, AI Singapore, National University of Singapore, Cohere, MIT, KAIST, Instituto de Telecomunicações, Instituto Superior Técnico, Universidade de Lisboa, MIT, MIT-IBM Watson AI Lab, Carnegie Mellon University, CONICET & Universidad de Buenos Aires emerges as a transformative benchmark designed to overcome the limitations of traditional multilingual datasets, particularly the Massive Multitask Language Understanding (MMLU) dataset.
The motivations for Global-MMLU🌍 stem from critical observations about the shortcomings of existing datasets. These datasets often reflect Western-centric cultural paradigms and depend heavily on machine translations, which can distort meaning and introduce biases. For example, MMLU datasets are predominantly aligned with Western knowledge systems, with 28% of the dataset requiring culturally sensitive insights, of which 86.5% are rooted in Western cultural contexts. Also, 84.9% of geographic knowledge questions are North America- or Europe-centric, underscoring the dataset’s need for global inclusivity.

Global-MMLU🌍 seeks to correct these imbalances by introducing a dataset spanning 42 languages, encompassing both high- and low-resource languages. Including culturally sensitive (CS) and culturally agnostic (CA) subsets allows for a more granular evaluation of multilingual capabilities. CS subsets demand cultural, geographic, or dialect-specific knowledge, while CA subsets focus on universal, non-contextual tasks. The creation of Global-MMLU🌍 involved a rigorous data curation process. It combined professional translations, community contributions, and improved machine translation techniques. Notably, professional annotators worked on high-accuracy translations for key languages like Arabic, French, Hindi, and Spanish. Community-driven efforts further enriched the dataset by addressing linguistic nuances in less-resourced languages.
A critical innovation of Global-MMLU🌍 lies in its evaluation methodology. By separately analyzing CS and CA subsets, researchers can assess the true multilingual capabilities of LLMs. For instance, cultural sensitivity significantly impacts model rankings, with average shifts of 5.7 ranks and 7.3 positions on CS datasets, compared to 3.4 ranks and 3.7 positions on CA datasets. These findings highlight the variability in model performance when handling culturally nuanced versus universal knowledge tasks. The evaluation of 14 state-of-the-art models, including proprietary systems like GPT-4o and Claude Sonnet 3.5, revealed critical insights. Closed-source models generally outperformed open-weight counterparts, particularly in culturally sensitive tasks. However, they also exhibited greater variability in low-resource language evaluations, underscoring the challenges of creating robust multilingual systems.
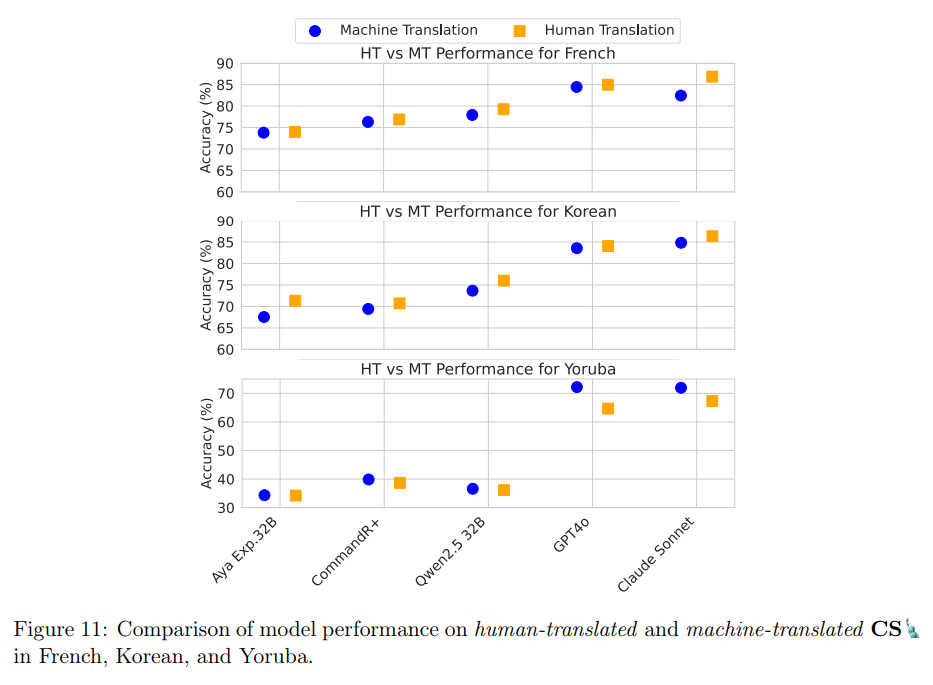
Global-MMLU🌍 dataset builds on professional translations, community contributions, and state-of-the-art machine translation techniques, emphasizing addressing translation artifacts and cultural biases. Unlike traditional methods that rely heavily on automated translations, Global-MMLU🌍 incorporates human-verified translations for improved accuracy and cultural relevance. These efforts focused on four “gold-standard” languages, Arabic, French, Hindi, and Spanish, where professional annotators ensured the translations adhered to both linguistic fluency and cultural appropriateness. Also, community contributions enriched the dataset for eleven other languages, requiring at least fifty samples to be verified by native speakers to ensure quality.
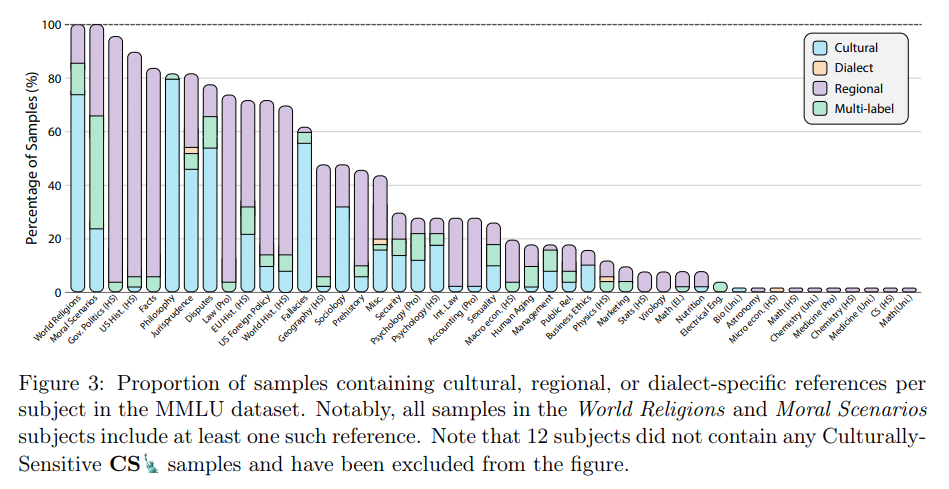
A key challenge addressed in Global-MMLU🌍 is the inherent variability in culturally sensitive tasks. The annotation process involved categorizing questions based on their reliance on cultural knowledge, regional specificity, and dialectal understanding. For instance, questions requiring cultural knowledge often reflected Western-centric paradigms, which dominate 86.5 percent of the culturally sensitive subset. In contrast, regions like South Asia and Africa were significantly underrepresented, accounting for a mere four percent and one percent, respectively. Geographic biases were also apparent, with 64.5 percent of questions requiring regional knowledge focused on North America and 20.4 percent on Europe. Such imbalances highlighted the necessity of re-evaluating model capabilities on more inclusive datasets.
Closed-source models like GPT-4o and Claude Sonnet 3.5 demonstrated strong performance across both subsets, yet their rankings showed greater variability when handling culturally nuanced tasks. This variability was pronounced in low-resource languages such as Amharic and Igbo, where limited training data often exacerbates the challenges of multilingual evaluations. Models trained predominantly on high-resource language datasets displayed clear biases, often underperforming in culturally diverse or less-represented contexts.
The findings also underscored the need to disaggregate model performance by resource availability of languages. For instance, high-resource languages like English and French achieved the highest accuracy levels, while low-resource languages exhibited significant drops in performance accompanied by higher variability. In culturally sensitive subsets, this variability was amplified due to the nuanced understanding required to interpret cultural, regional, and vernacular references. This trend was not limited to low-resource languages; even high-resource languages experienced variability in rankings when cultural sensitivity was a factor. For example, Hindi and Chinese emerged as the most sensitive languages to culturally specific tasks, showing significant rank changes across evaluated models.
Global-MMLU🌍 introduced separate analysis for culturally sensitive and agnostic subsets to ensure the dataset’s robustness and evaluations. This approach revealed that models demonstrated varying cultural adaptability even within high-resource languages. Closed-source models generally outperformed open-weight systems, yet both categories struggled with tasks requiring a deep contextual understanding of culturally nuanced material. The dataset’s distinct categorization of culturally sensitive and agnostic tasks allowed researchers to pinpoint areas where language models excel or falter.
In conclusion, Global-MMLU🌍 stands as a data-rich benchmark redefining multilingual AI evaluation by addressing critical cultural and linguistic representation gaps. The dataset encompasses 42 languages, including low-resource languages like Amharic and Igbo, and integrates 14,000 samples with over 589,000 translations. Of these, 28% require culturally sensitive knowledge, with 86.5% rooted in Western cultural paradigms. Evaluations revealed that culturally sensitive tasks induce an average rank variability of 5.7 ranks and 7.3 positions across models. High-resource languages achieved superior performance, while low-resource languages showed significant variability, with accuracy fluctuations of up to 6.78%.
Check out the Paper and HF Link. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 60k+ ML SubReddit.
🚨 [Partner with us]: ‘Next Magazine/Report- Open Source AI in Production’
Sana Hassan, a consulting intern at Marktechpost and dual-degree student at IIT Madras, is passionate about applying technology and AI to address real-world challenges. With a keen interest in solving practical problems, he brings a fresh perspective to the intersection of AI and real-life solutions.
